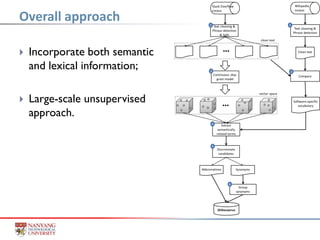
The document presents a method for unsupervised inference of software-specific morphological forms from informal discussions on platforms like Stack Overflow and Wikipedia. It describes challenges in natural language processing due to diverse morphological word forms, such as synonyms and abbreviations, and outlines an approach to build a domain-specific thesaurus that groups related terms based on semantic and lexical information. The evaluation shows significant coverage of software-specific vocabulary, with high accuracy in identifying abbreviations and synonyms.