Download as PDF, PPTX




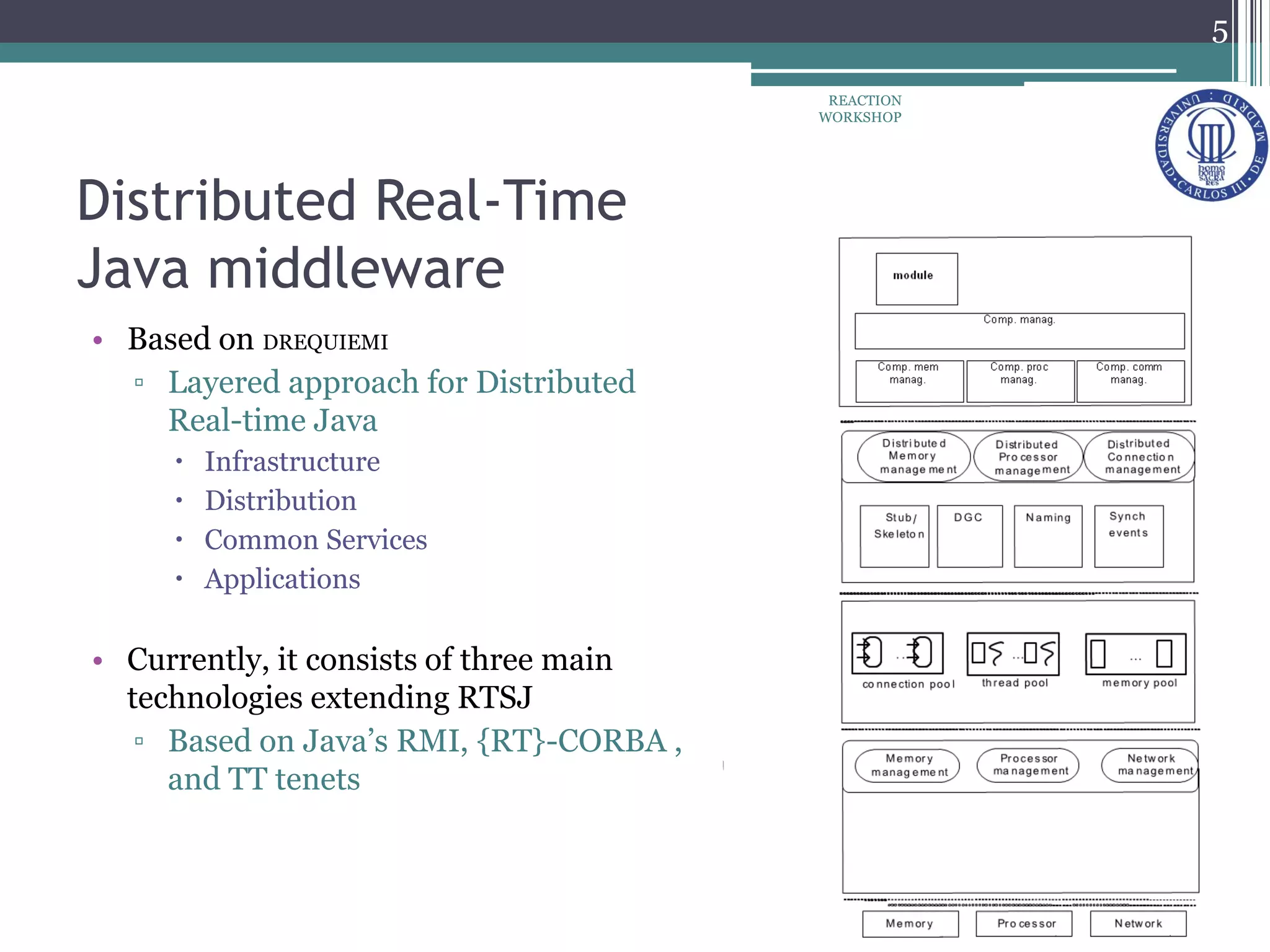

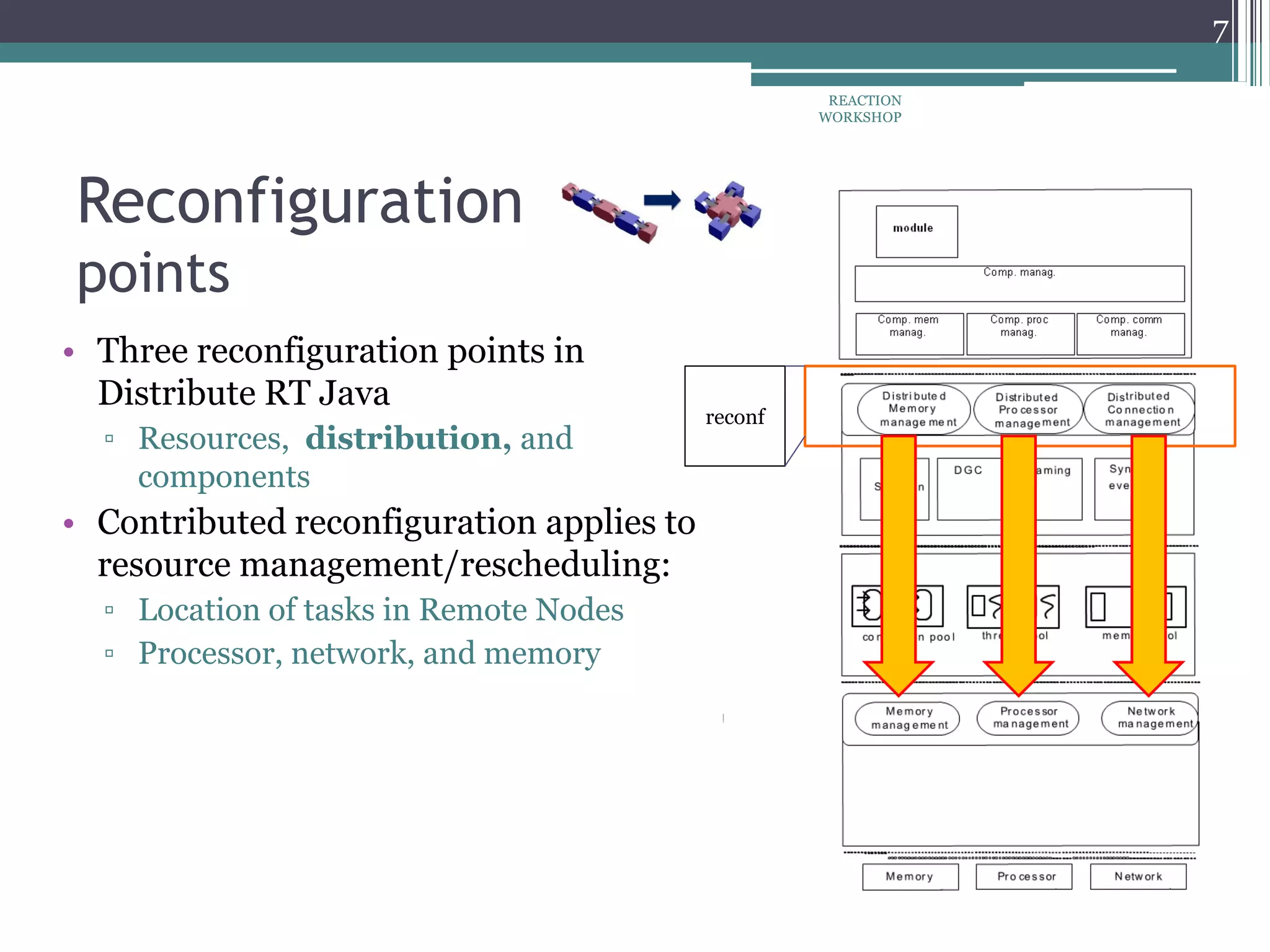
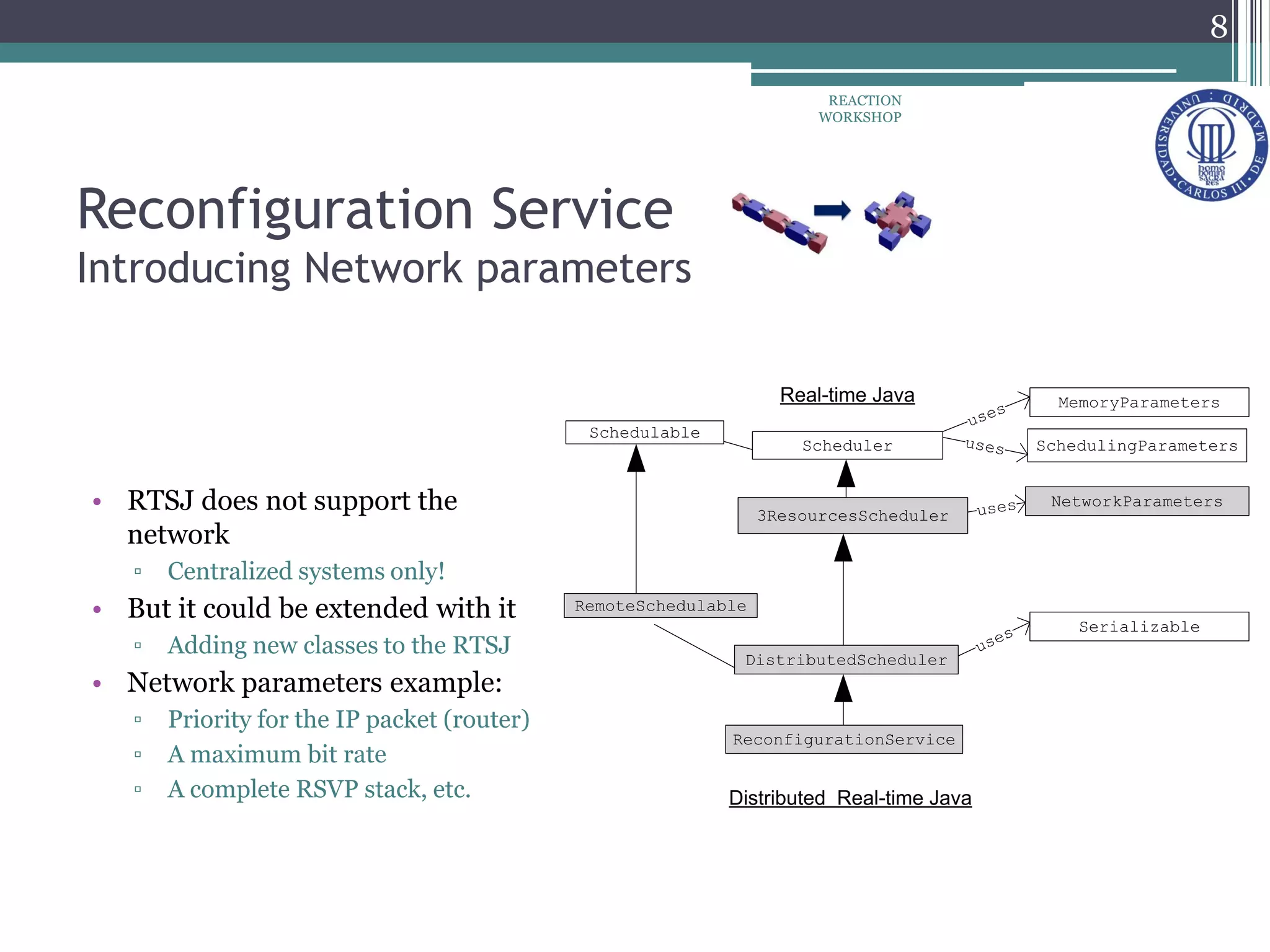



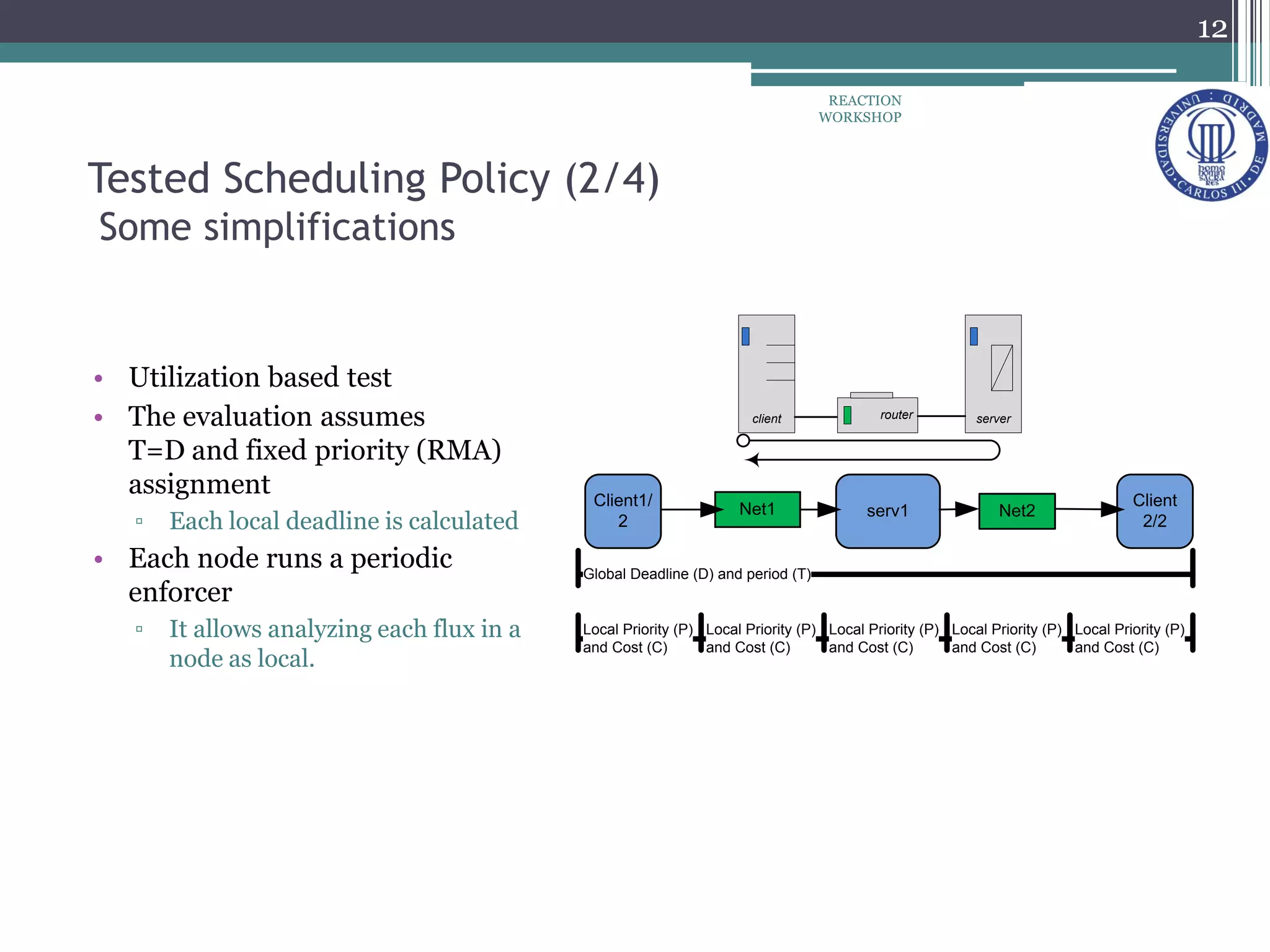
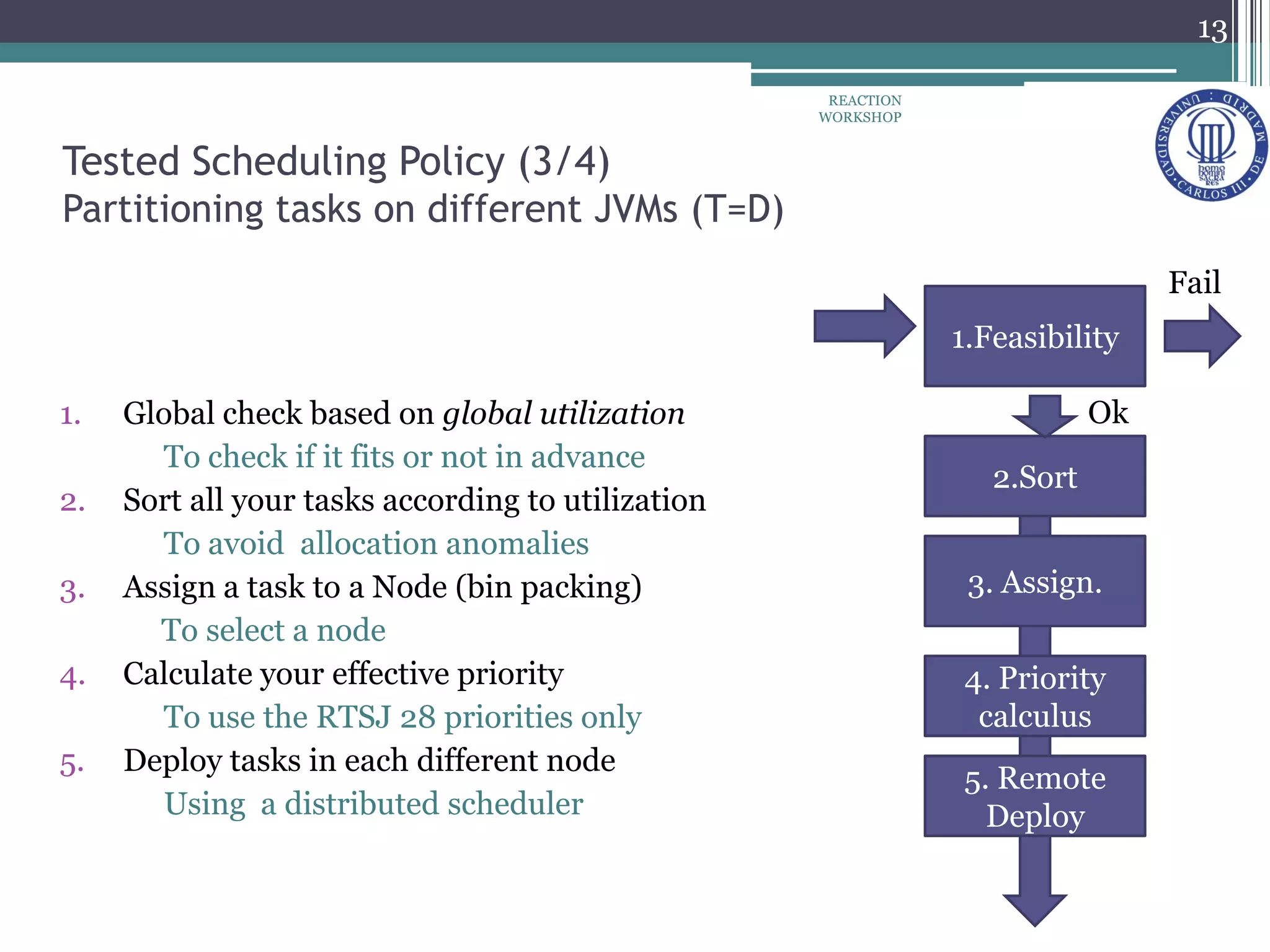

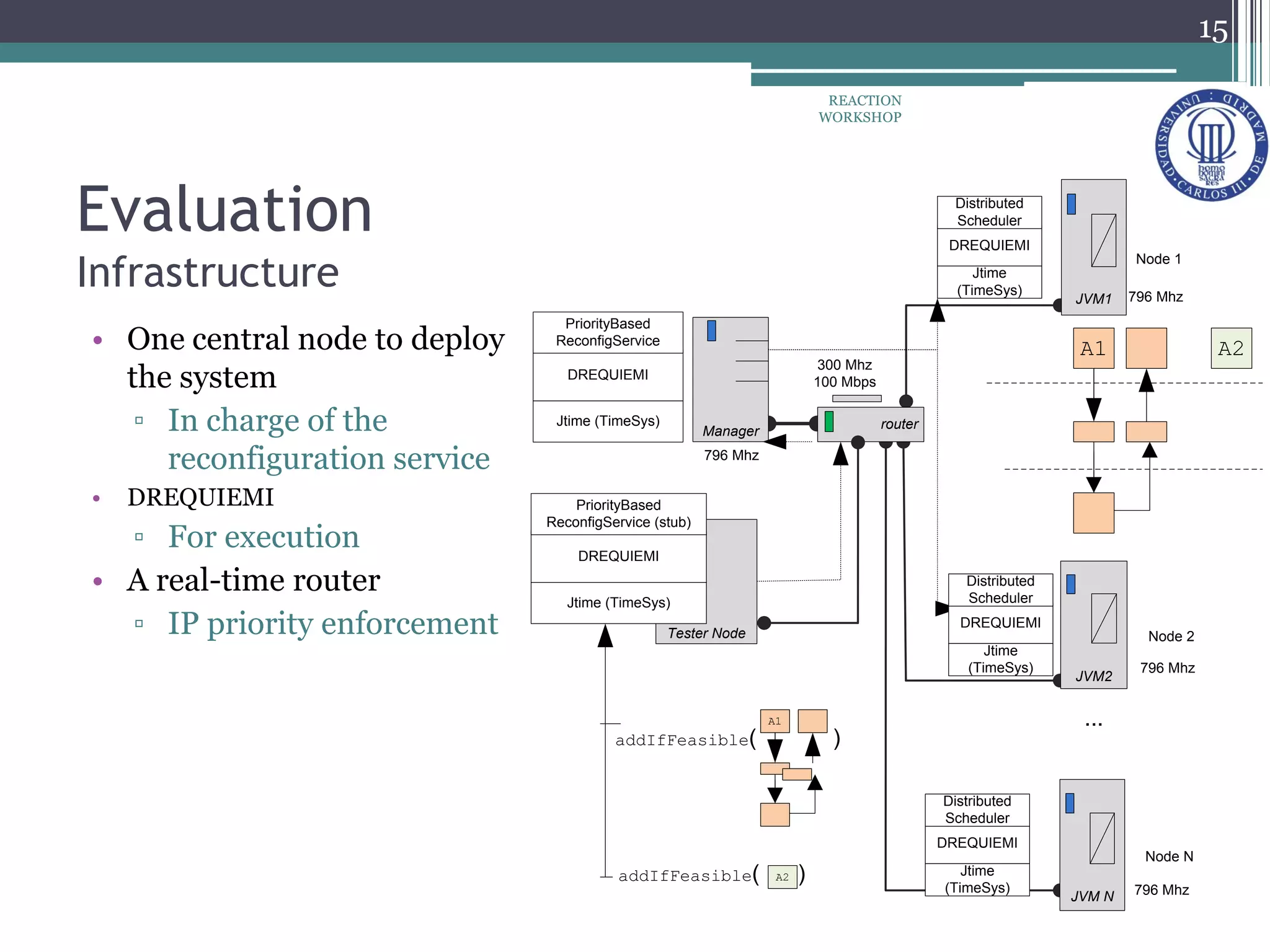
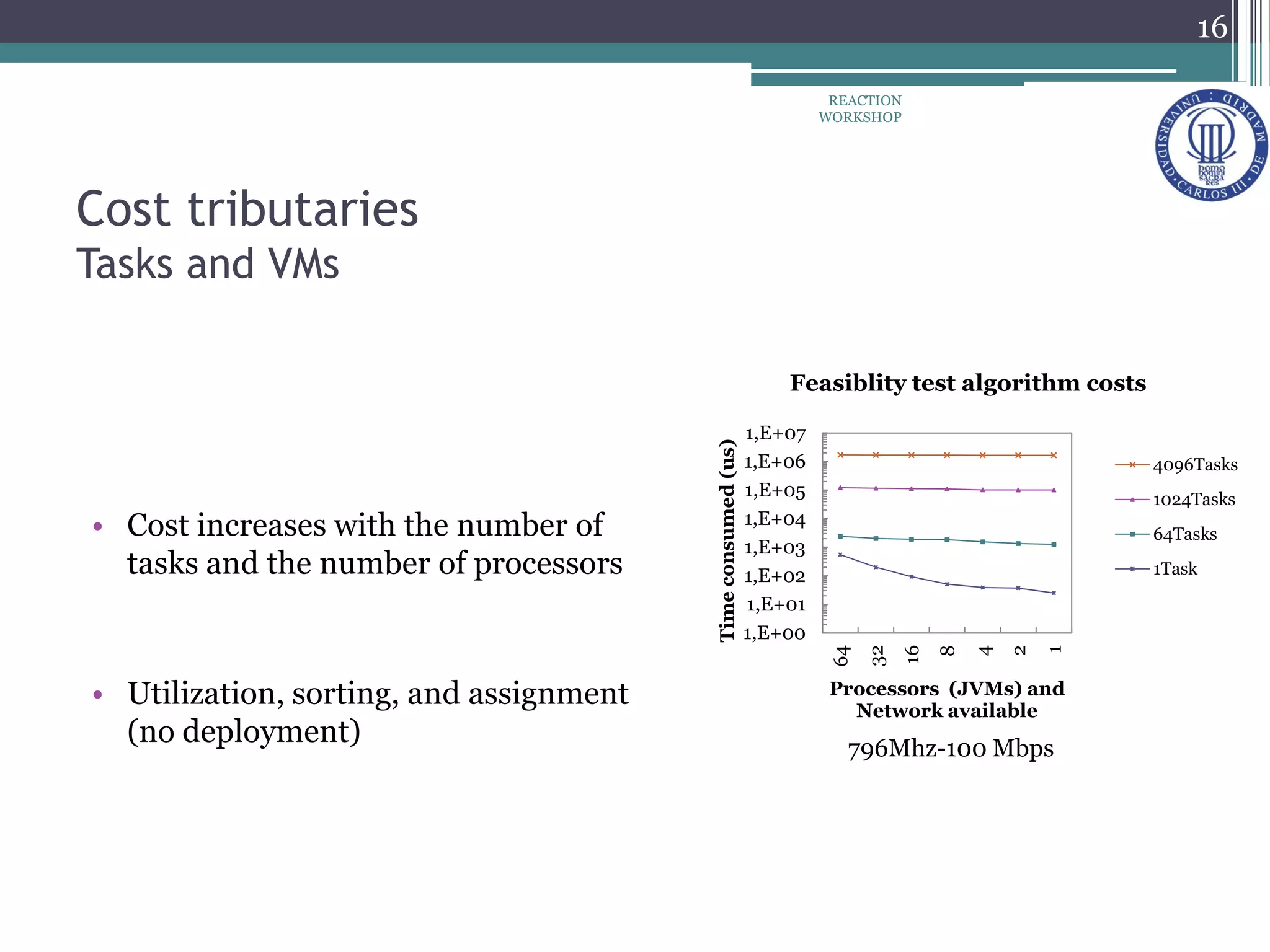
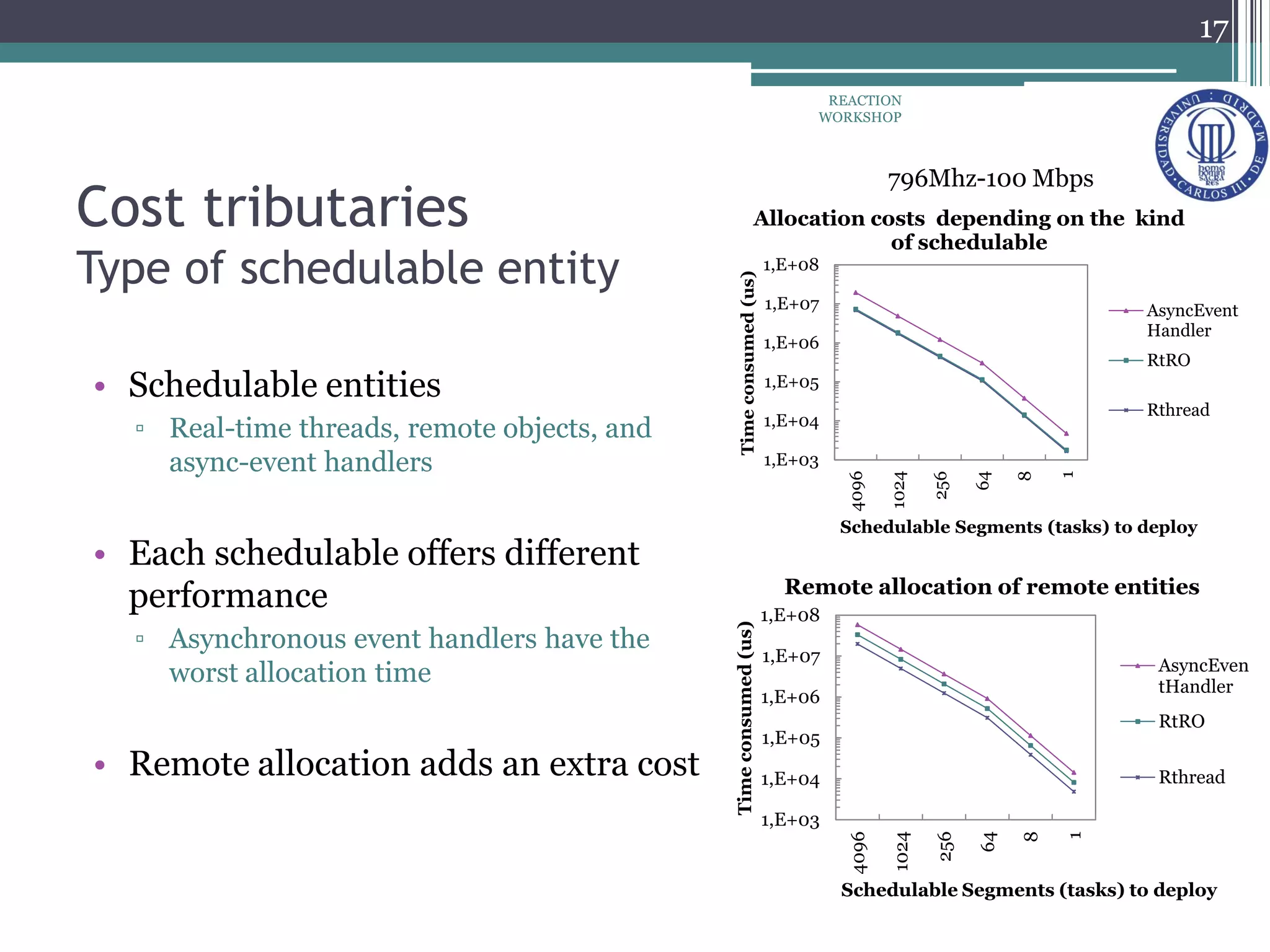




The document proposes a reconfiguration service for distributed real-time Java applications. It introduces extensions to support real-time parameters like scheduling, release, memory and network parameters. The service allows adding and removing tasks from distributed Java VMs. It evaluates a priority-based partitioning policy for task allocation. The policy checks feasibility and assigns priorities. Evaluation shows reconfiguration time increases with number of tasks and VMs. Asynchronous events have the highest cost. Ongoing work aims to support different scheduling policies and adaptation using real-time OSGi.













































































