Download to read offline






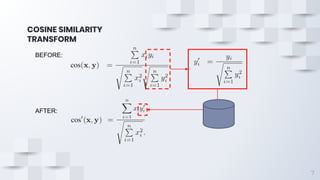



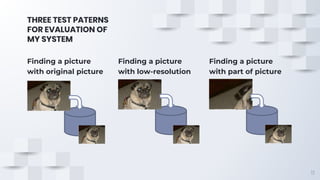
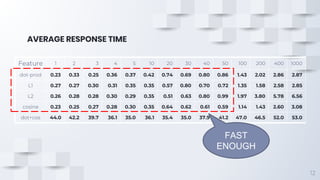
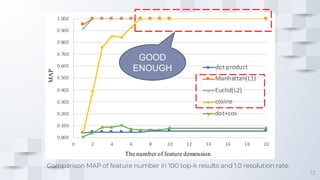
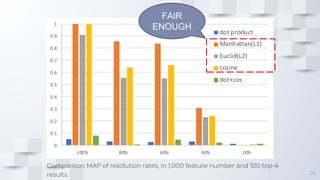
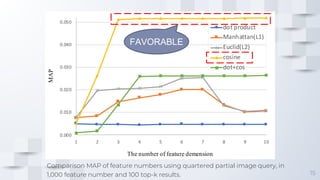




The document describes a fast content-based image retrieval method using deep visual features, focusing on improving efficiency by utilizing normalized vectors and reducing feature dimensions. Key findings demonstrate that pre-normalizing features significantly speeds up cosine similarity calculations, with at least 8 features deemed necessary for effective image searches. Finally, the author provides instructions for using the implemented method in Elasticsearch and shares their GitHub page for further reference.






























![[CVPR 2018] Visual Search (Image Retrieval) and Metric Learning](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr2018imageretrieval-180817015945-thumbnail.jpg?width=640&height=640&fit=bounds)














































