Downloaded 11 times


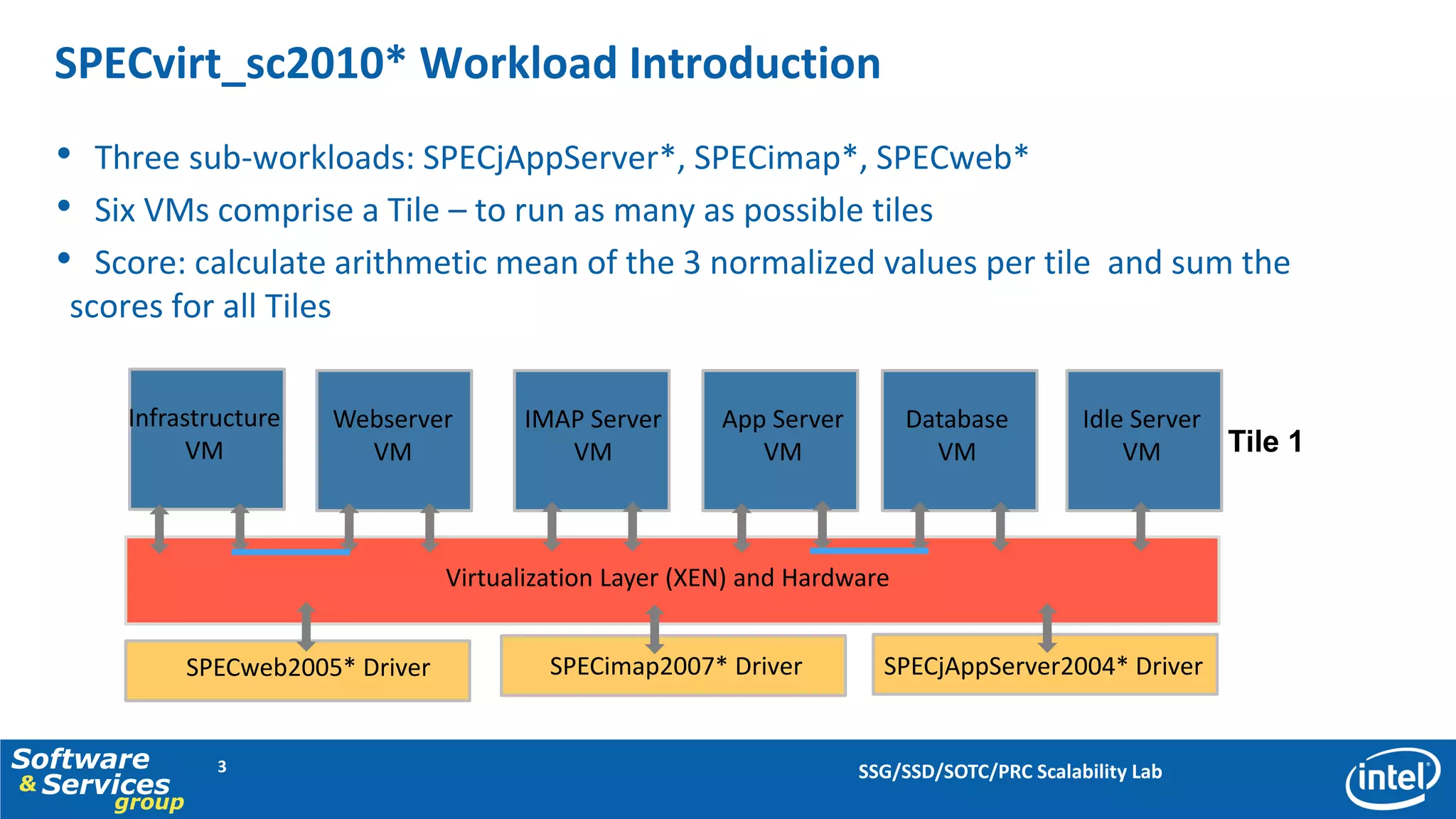
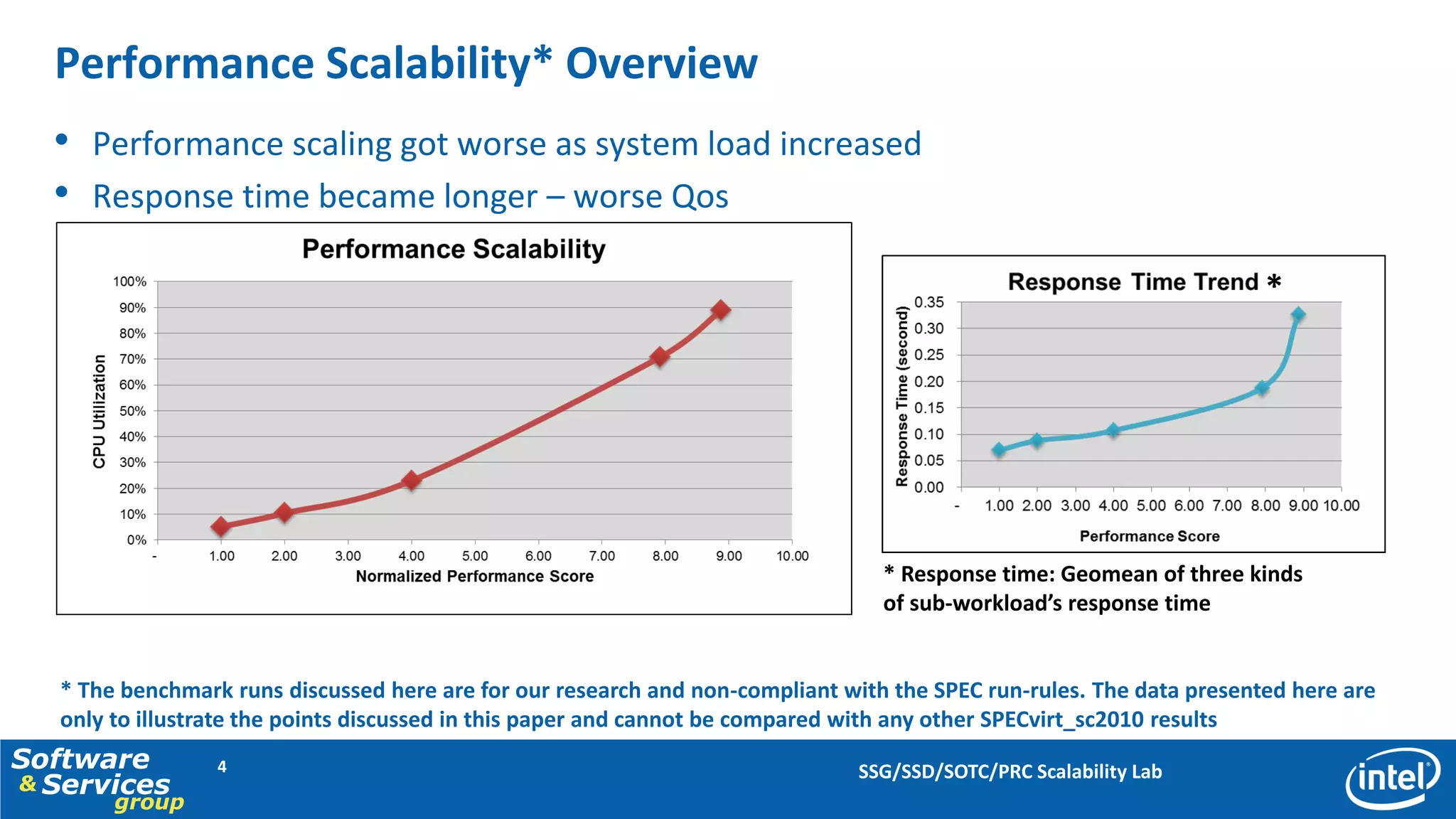
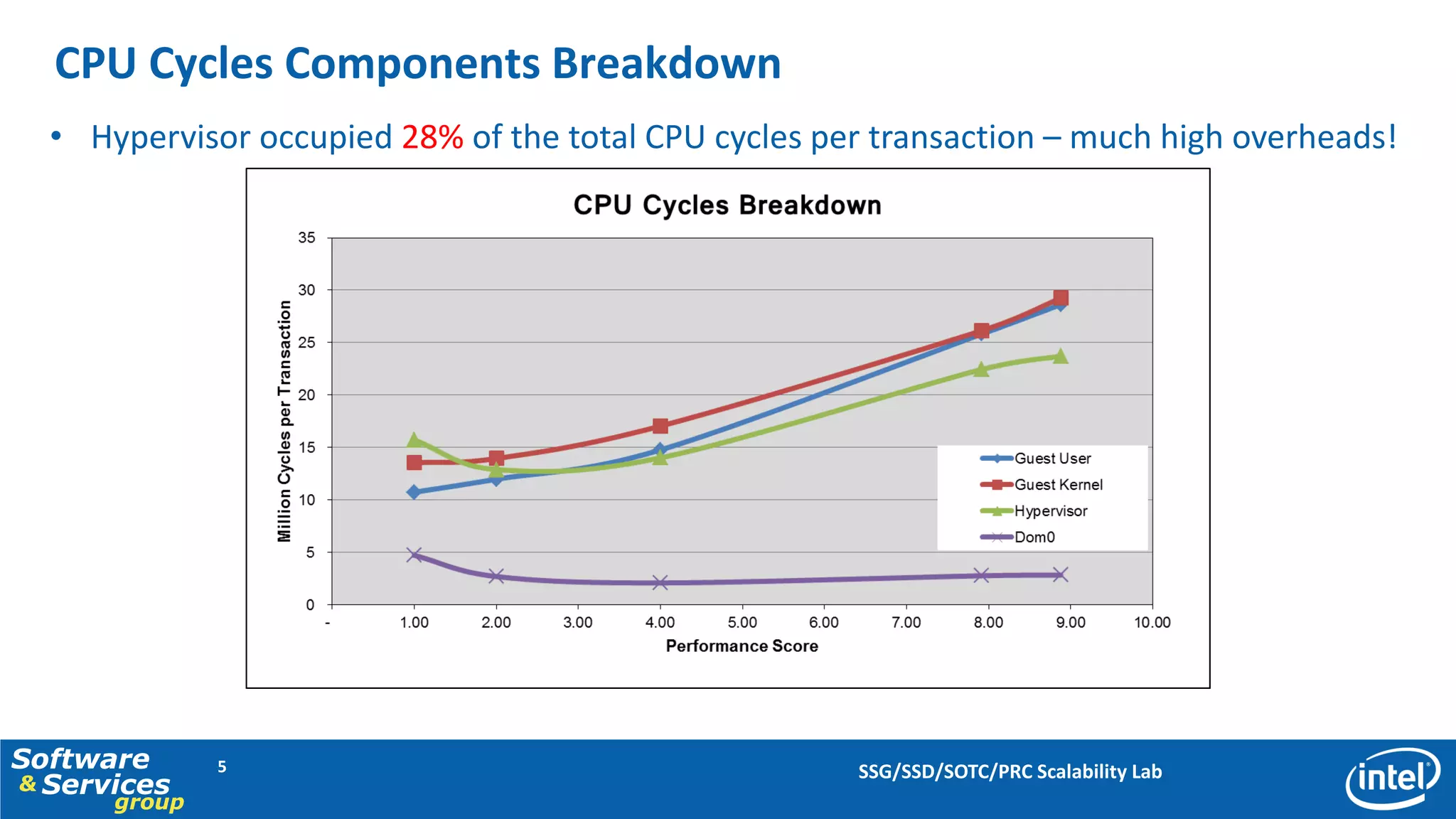
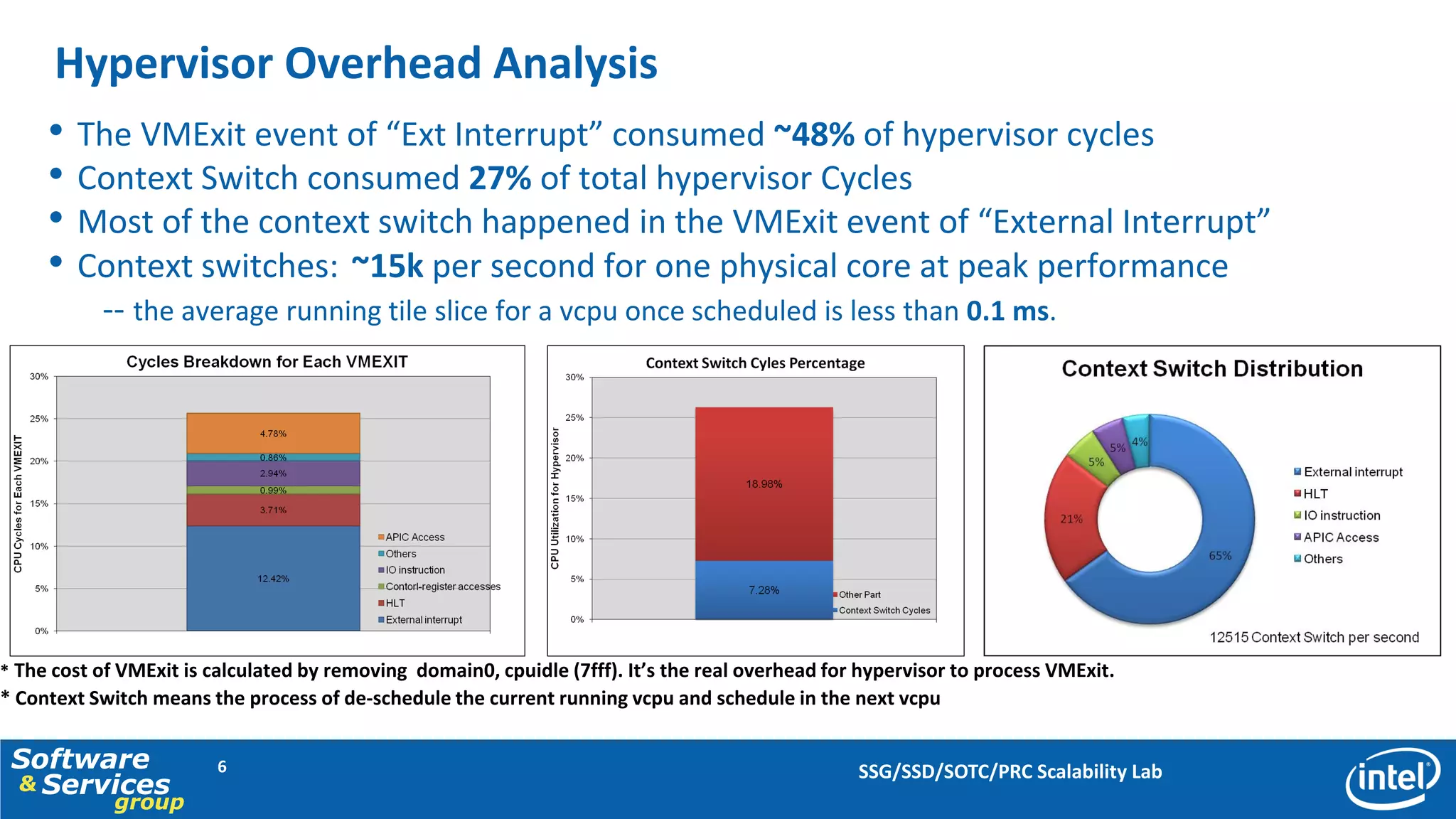

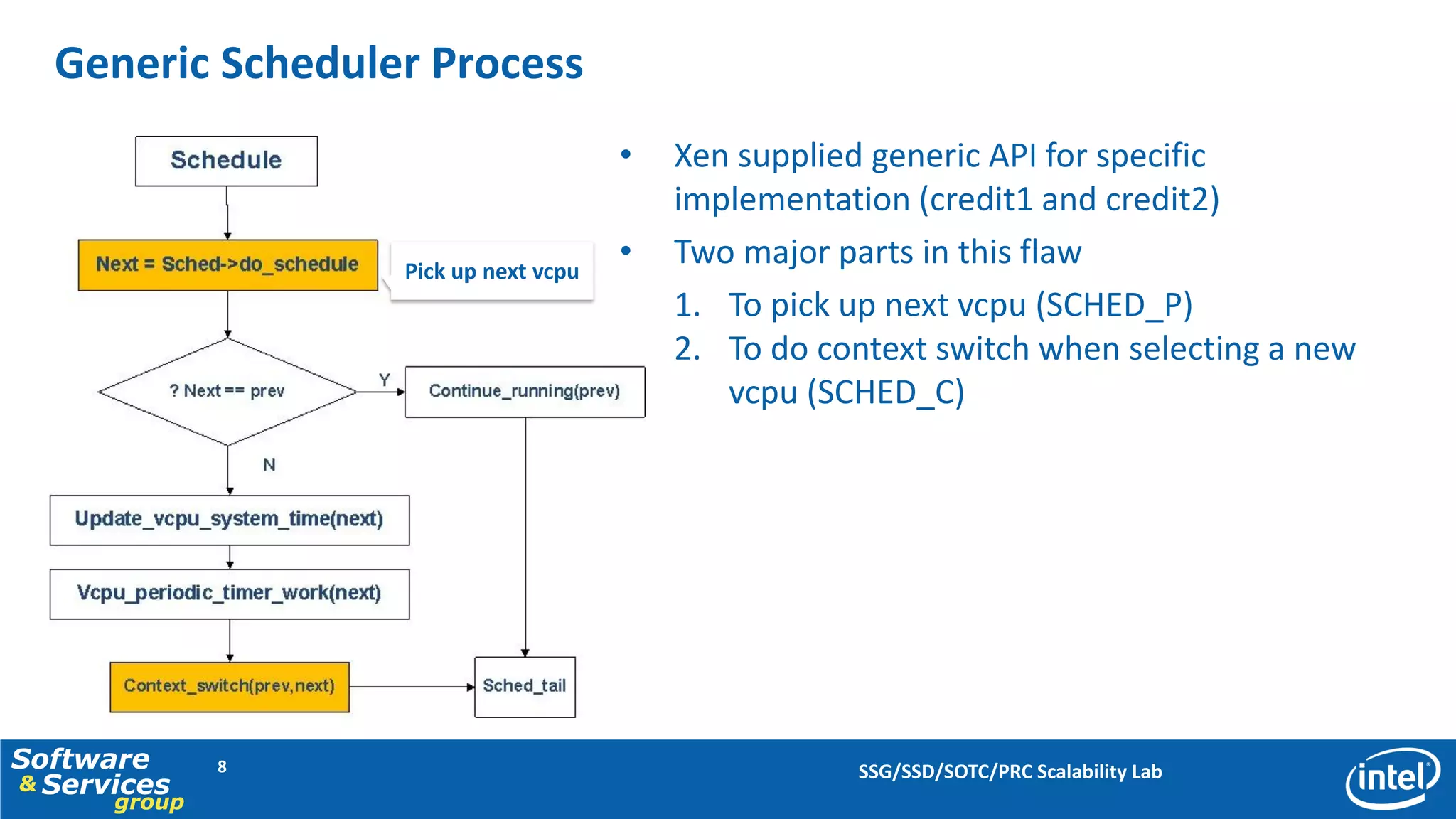
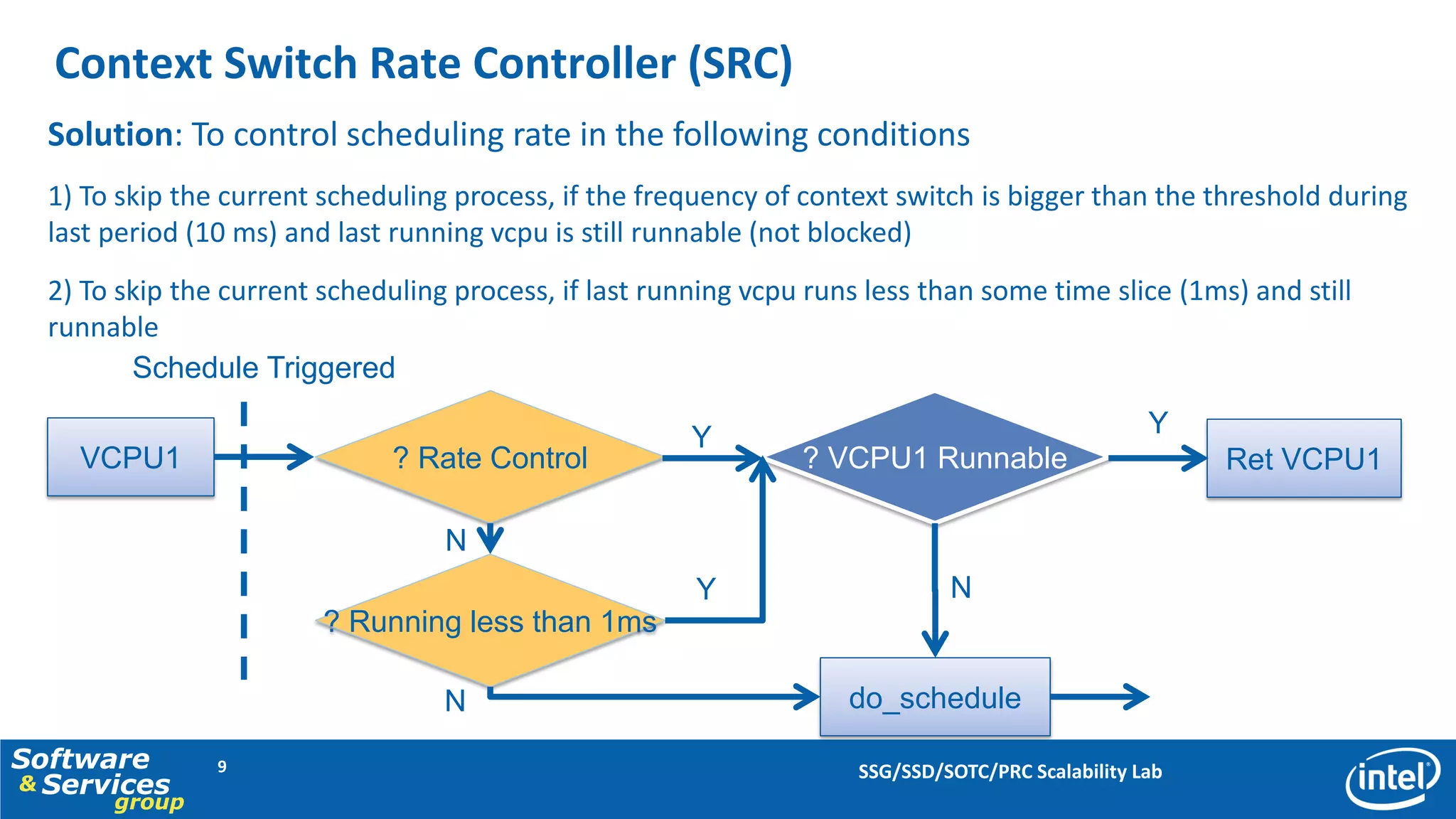
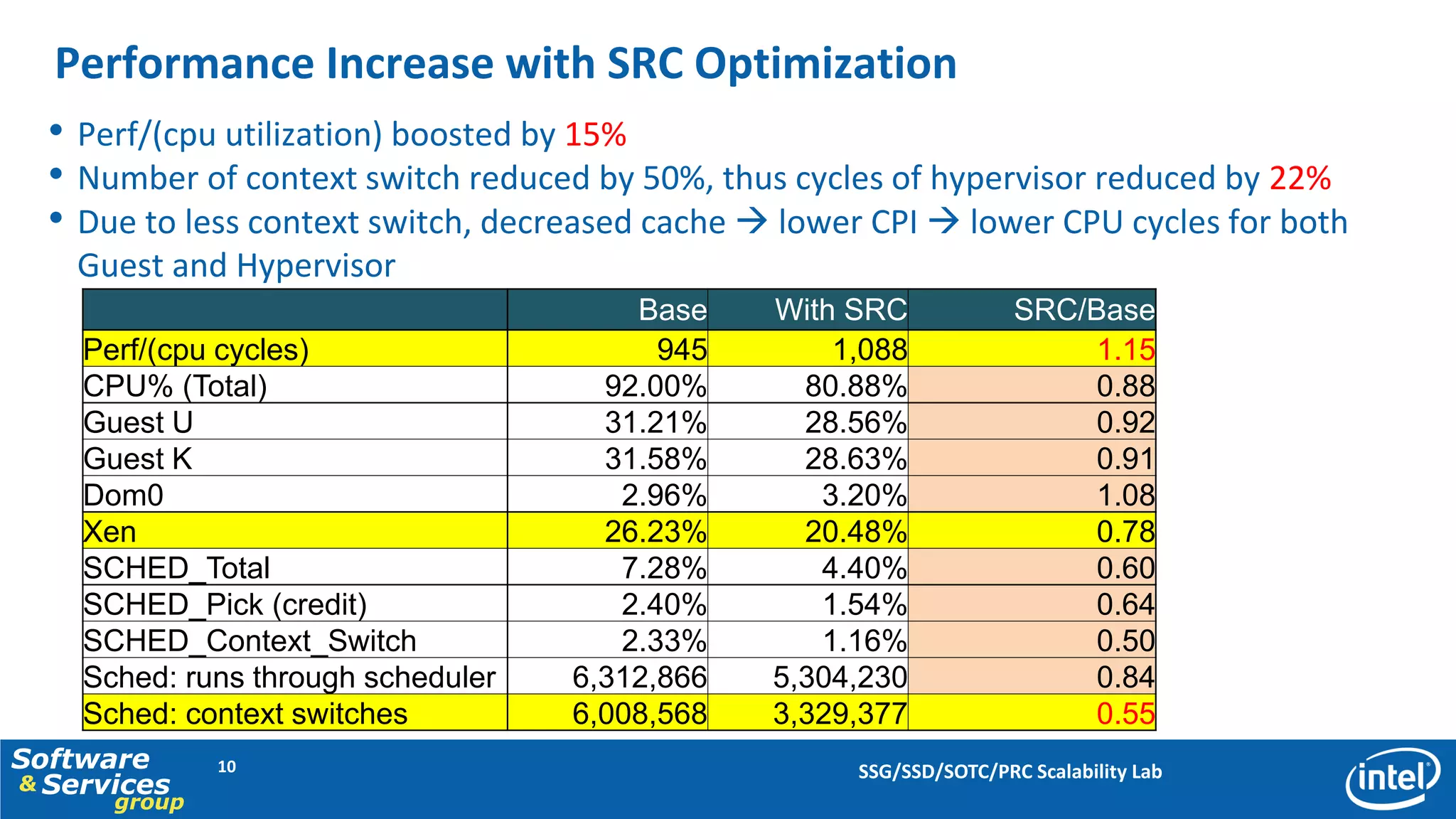




This document discusses server consolidation challenges on multi-core systems. It finds that hypervisor overhead increases significantly under high system load. Frequent context switching accounts for a large portion of hypervisor CPU cycles. Optimizing the credit scheduler to reduce context switching frequency improves performance by lowering hypervisor overhead by 22% and increasing performance per CPU utilization by 15%.









































































![XPDDS19: [ARM] OP-TEE Mediator in Xen - Volodymyr Babchuk, EPAM Systems](https://cdn.slidesharecdn.com/ss_thumbnails/xendevsummit2019-babchuk-op-tee-190812095541-thumbnail.jpg?width=640&height=640&fit=bounds)























