Downloaded 48 times











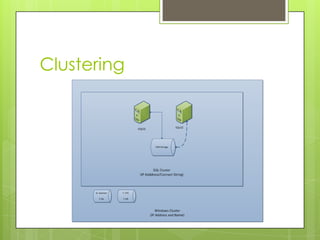



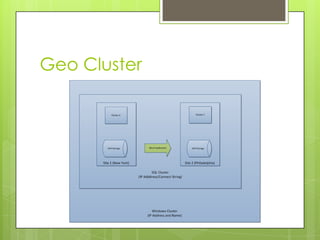

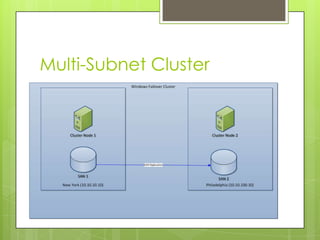








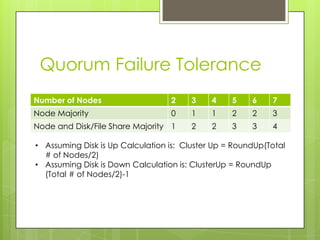



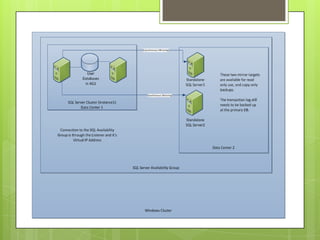












The document discusses SQL Server 2012's high availability and disaster recovery features, including licensing changes and new options such as always-on availability groups. Key topics include clustering, backup and recovery methods, flexible failover policies, and the importance of quorum in maintaining cluster communication. It highlights changes from SQL Server 2008 to 2012, aimed at DBAs for better management of high availability and disaster recovery scenarios.













































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














