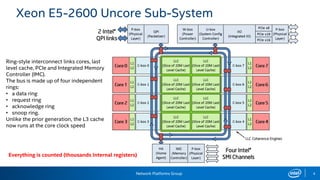
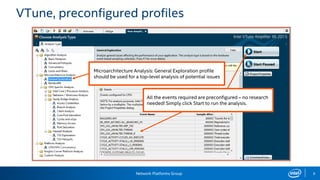
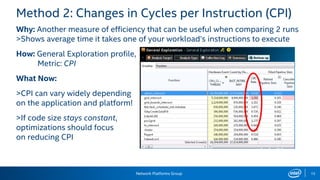
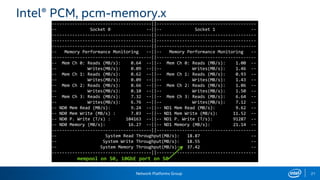
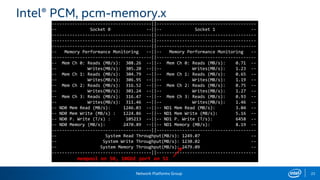
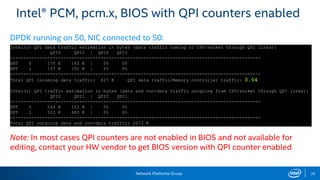
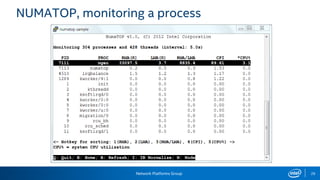
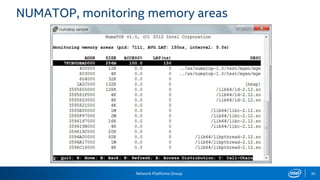
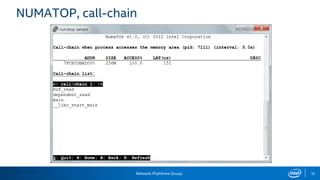
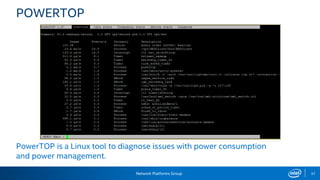
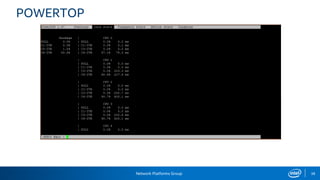
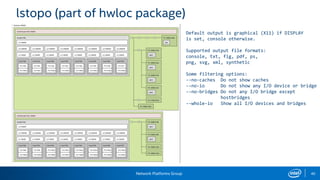
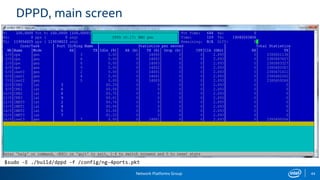
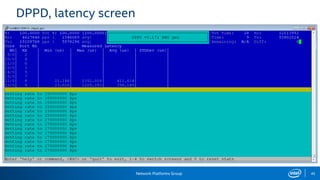
The document provides information on performance monitoring and analysis tools from Intel, including the Intel VTune Amplifier XE, Intel Performance Counter Monitor (PCM), and guidance on using them. It outlines a process for identifying performance bottlenecks including finding hotspots, determining efficiency, and identifying the underlying architectural issues. Potential issues discussed include cache misses, data access problems, allocation stalls, and branch mispredictions. The document also provides usage examples and resources for further information.

![Network Platforms Group
Legal Disclaimer
General Disclaimer:
© Copyright 2015 Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, the Intel Inside logo, Intel.
Experience What’s Inside are trademarks of Intel. Corporation in the U.S. and/or other countries. *Other names and
brands may be claimed as the property of others.
FTC Disclaimer:
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software
or service activation. Performance varies depending on system configuration. No computer system can be absolutely
secure. Check with your system manufacturer or retailer or learn more at [intel.com].
Software and workloads used in performance tests may have been optimized for performance only on Intel
microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems,
components, software, operations and functions. Any change to any of those factors may cause the results to vary. You
should consult other information and performance tests to assist you in fully evaluating your contemplated purchases,
including the performance of that product when combined with other products. For more complete information visit
http://www.intel.com/performance.](https://image.slidesharecdn.com/6profilingtools-150616084054-lva1-app6892/85/6-profiling-tools-2-320.jpg)