Download to read offline























![Tools don’t create reliability.
Human do.
[But tools can help.]
@CaseyRosenthal
Thank You!!!](https://image.slidesharecdn.com/azureday-rome-embracingfailure-191130080914/85/Embracing-Failure-AzureDay-Rome-36-320.jpg)



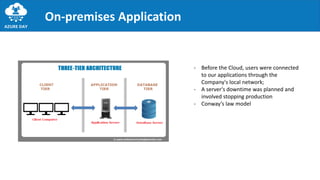
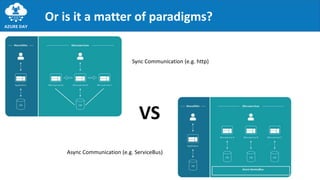
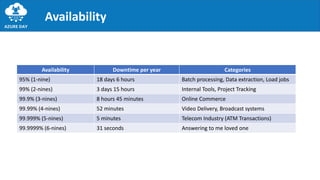
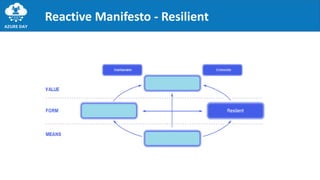
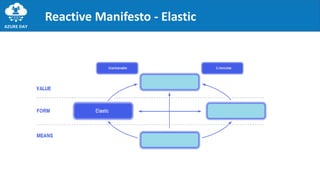
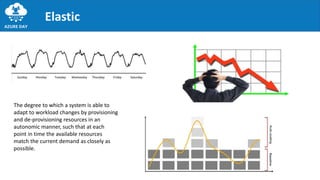
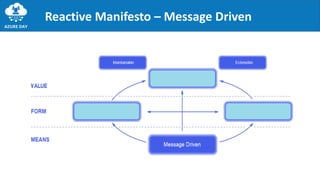
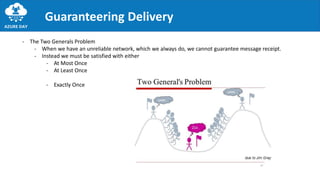
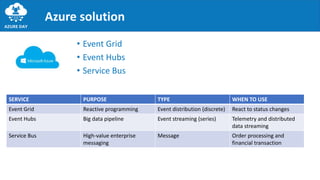
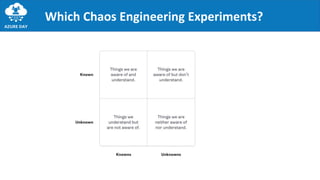
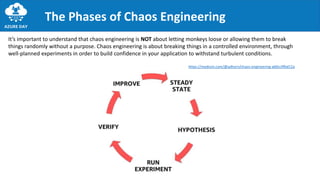
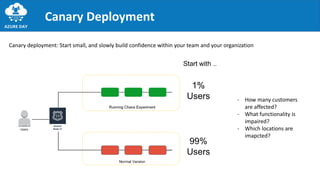
The document discusses the importance of embracing failure in cloud-based application development, highlighting the differences between traditional on-premises applications and modern microservices architectures. It emphasizes the need for a resilient, responsive, and elastic system design that incorporates chaos engineering techniques to enhance reliability and availability while adapting to workload changes. Additionally, it covers architectural patterns and principles for building reliable systems, including the role of continuous integration and continuous delivery tools.


















![Mitel Virtual Solutions[1]](https://cdn.slidesharecdn.com/ss_thumbnails/mitelvirtualsolutions1-1300105531069-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)





