Download to read offline






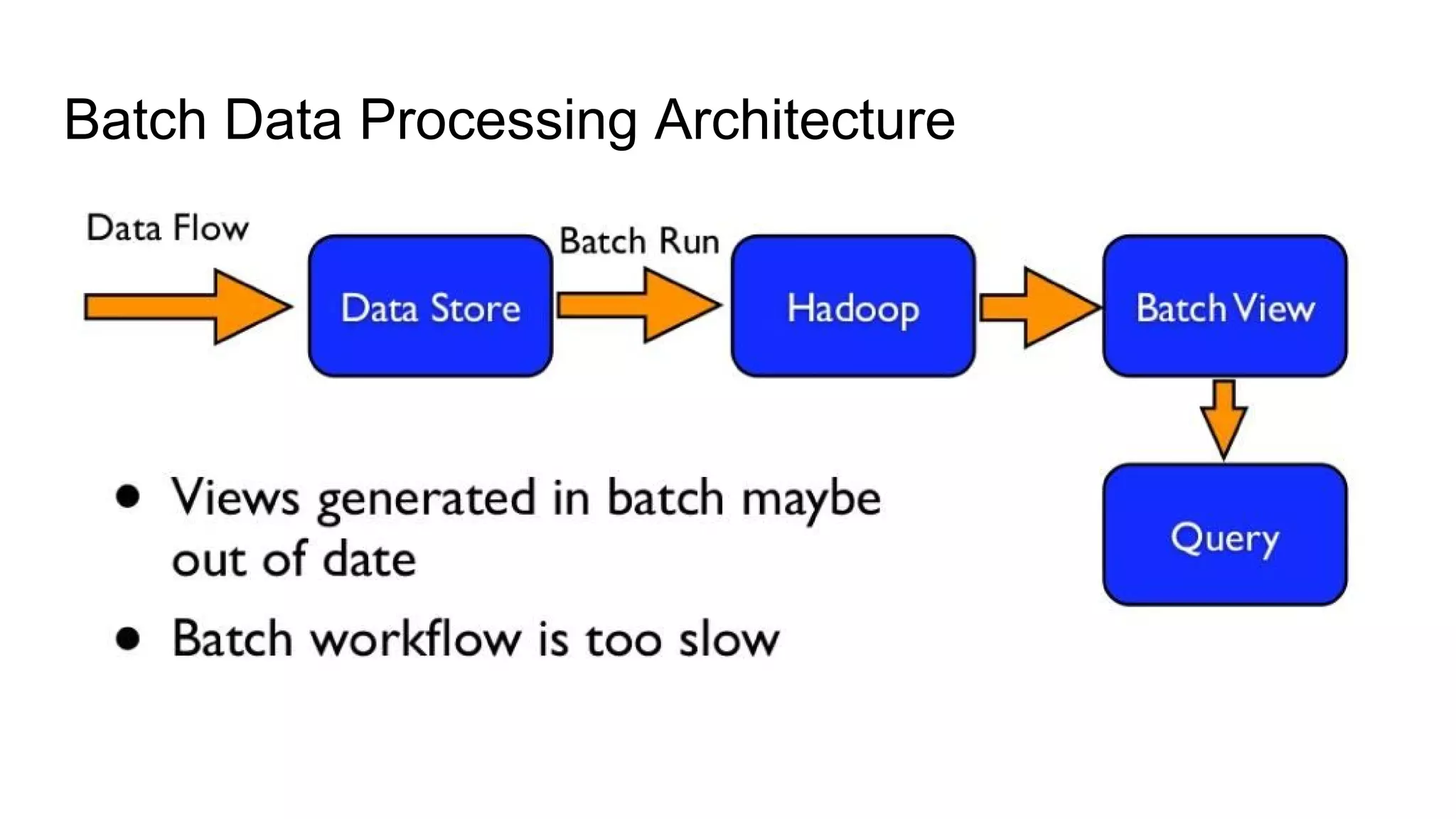

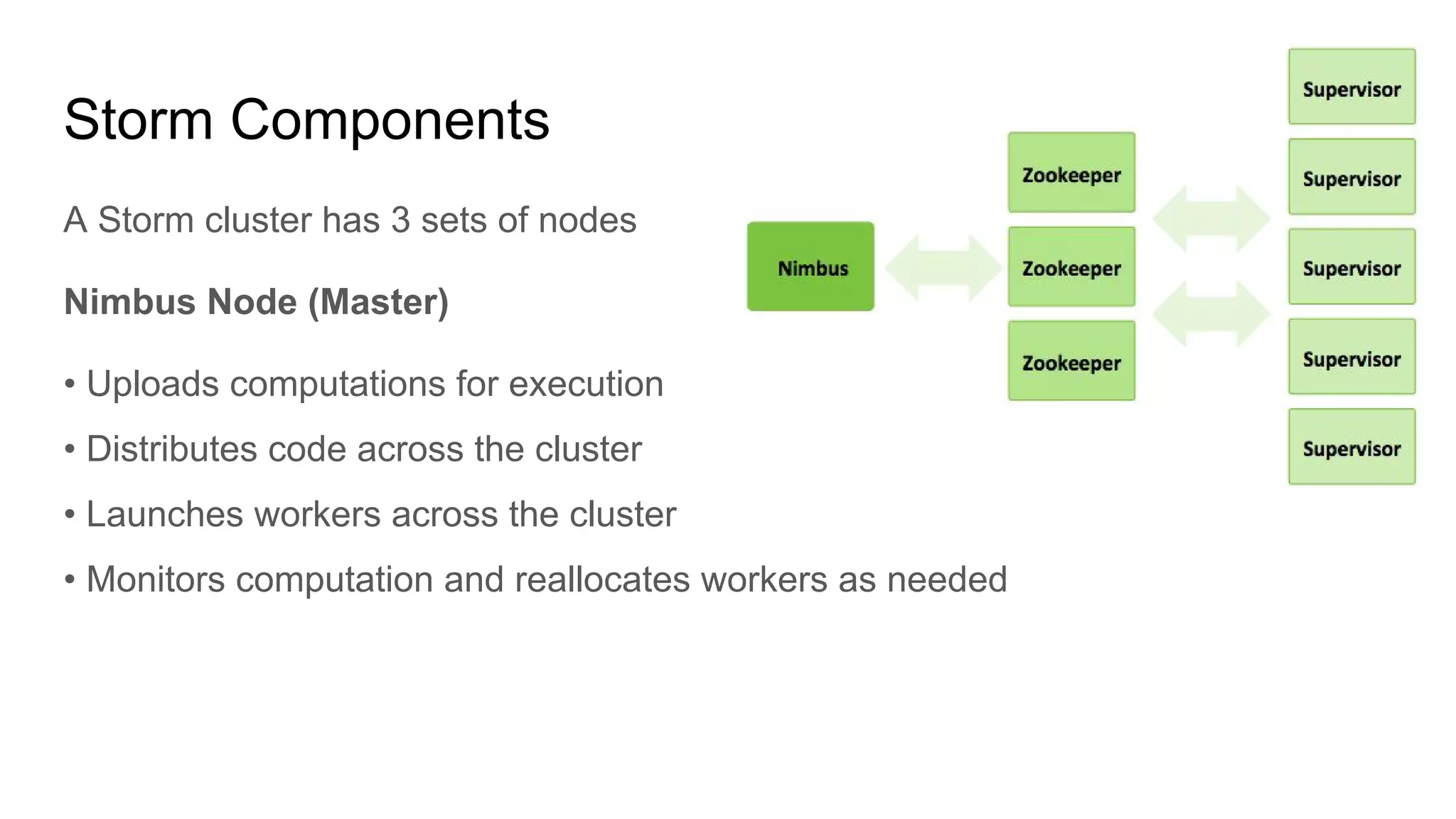
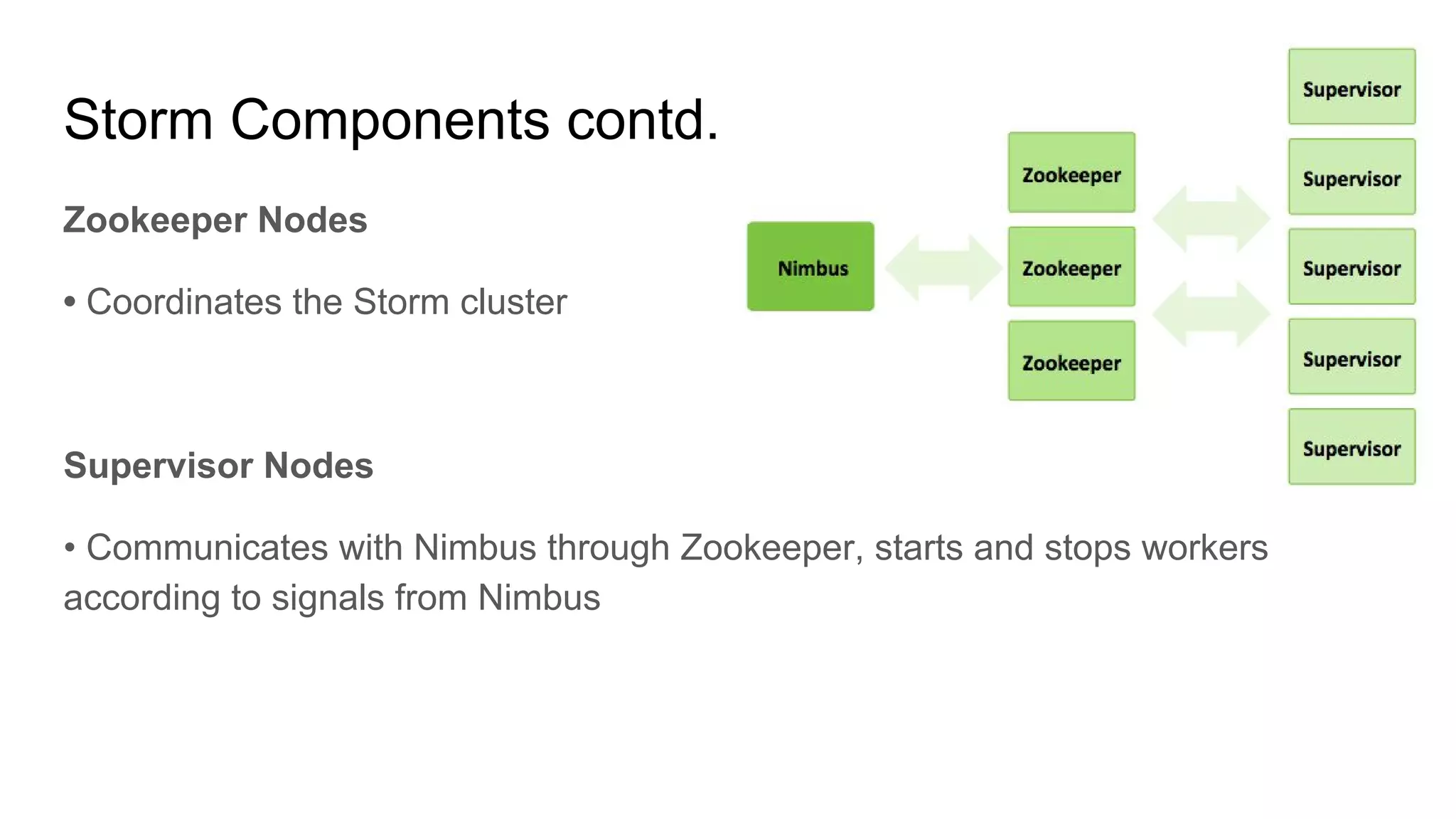

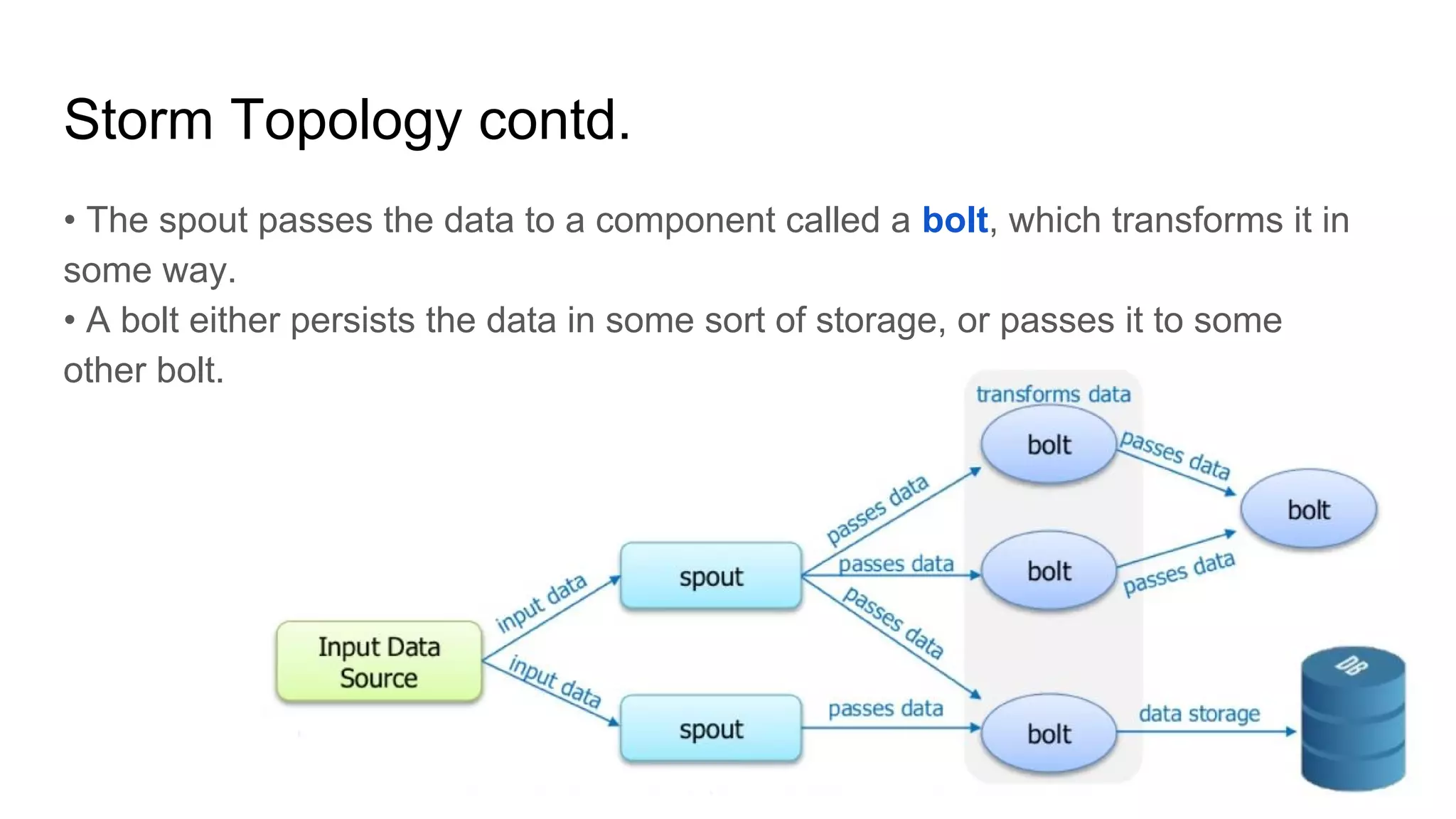


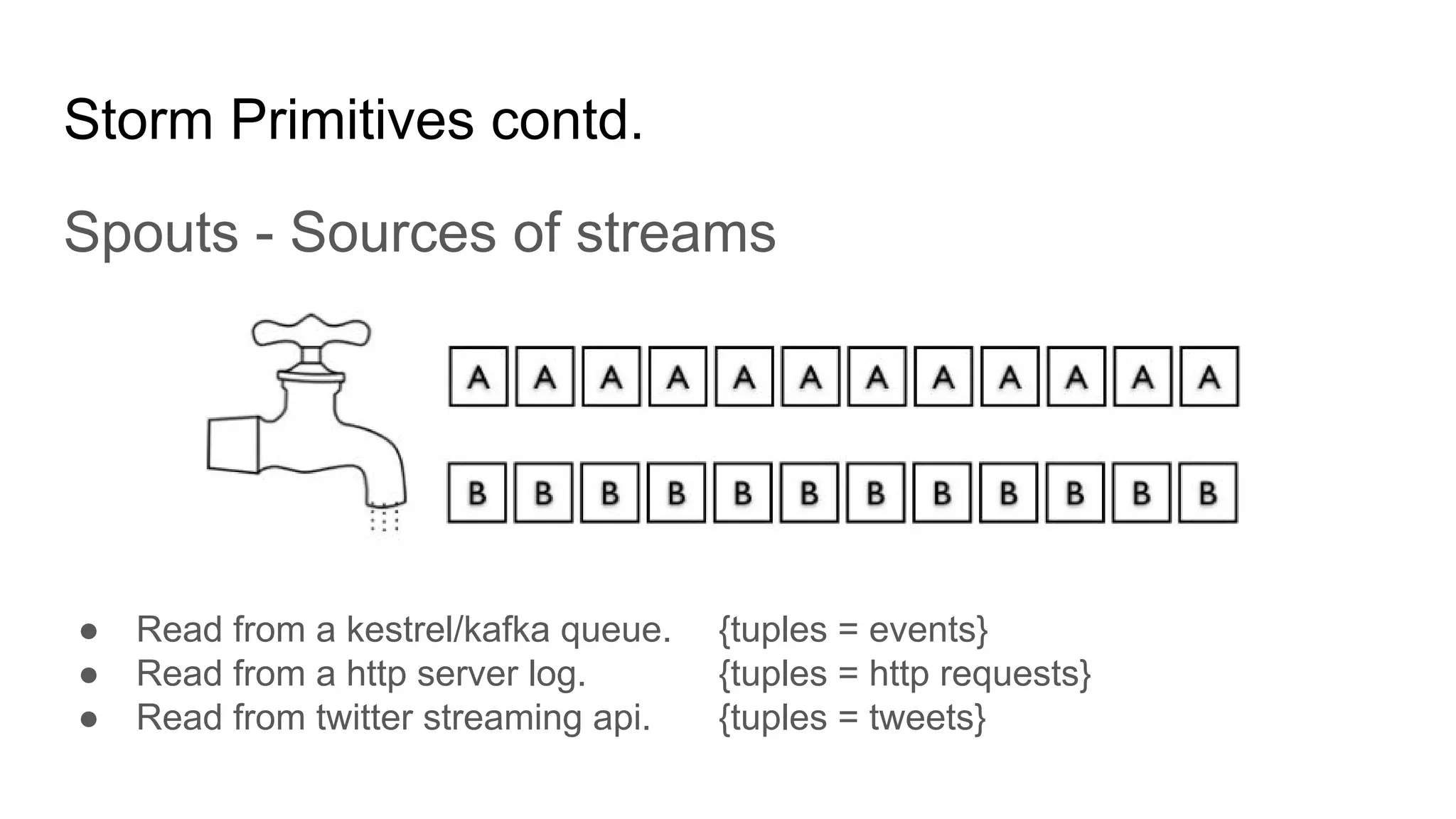


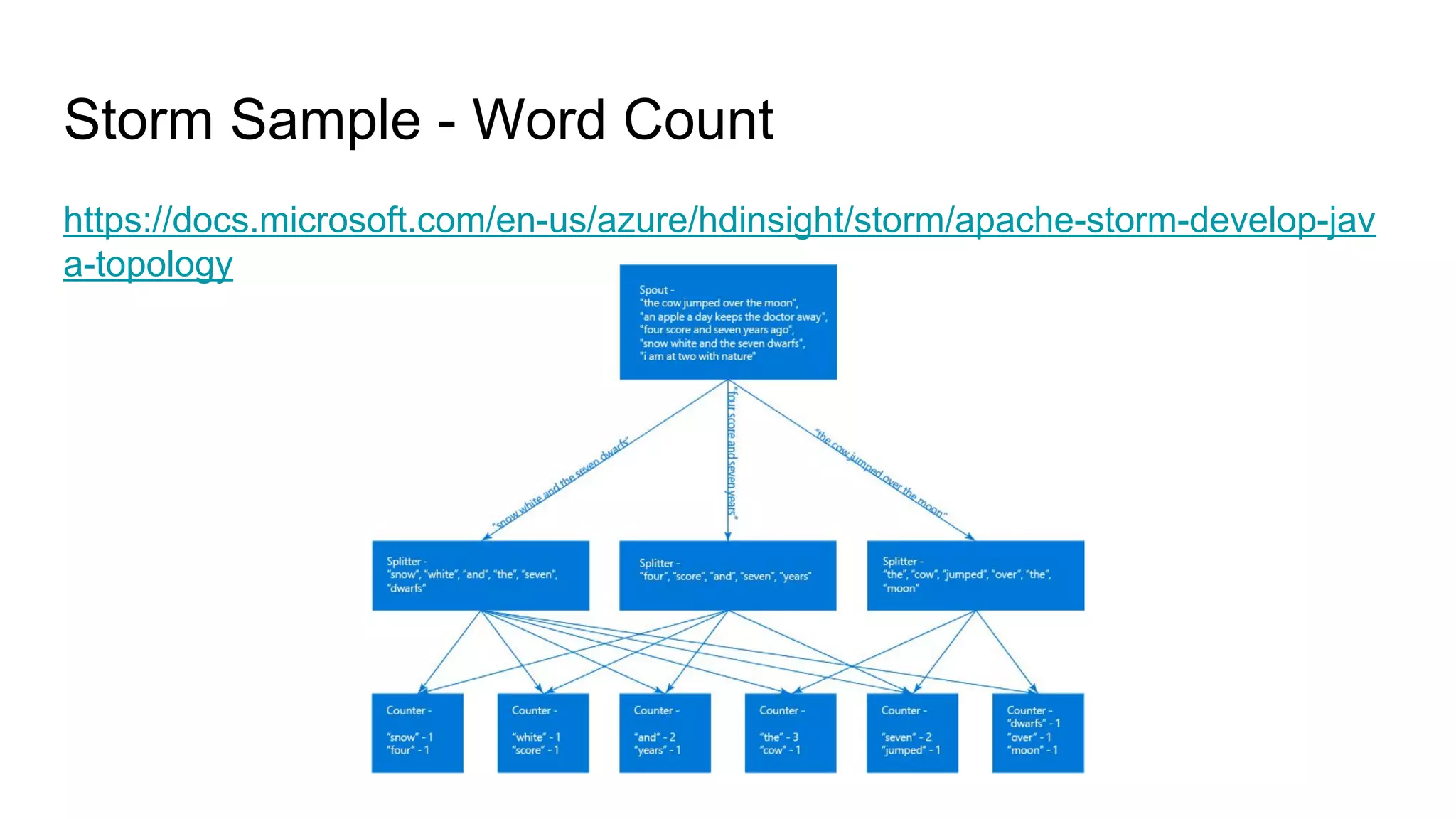

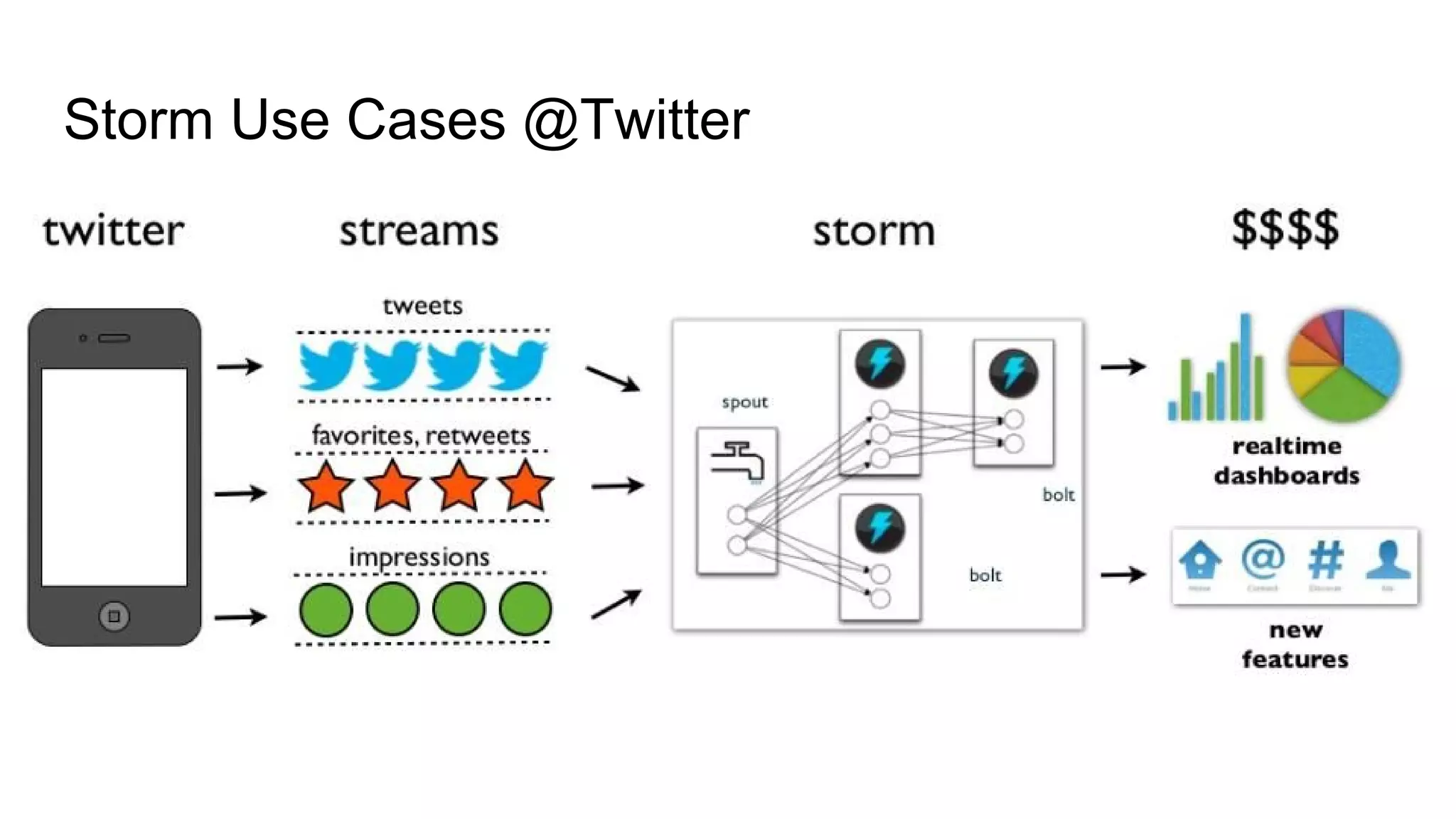




Apache Storm is an open-source, distributed real-time computation system that processes unbounded streams of data, comparable to how Hadoop handles batch processing. It consists of various components, including spouts and bolts in a topology, which manage data flow and processing tasks. Storm is favored for real-time applications due to its speed, scalability, fault tolerance, and ease of operation, with use cases from companies like Twitter for analytics and log processing.


































































