Downloaded 51 times


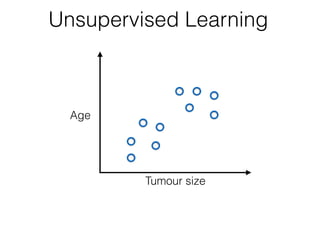















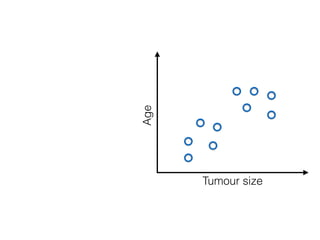
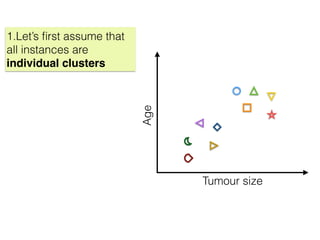
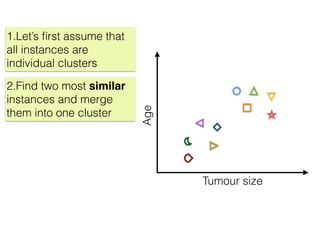
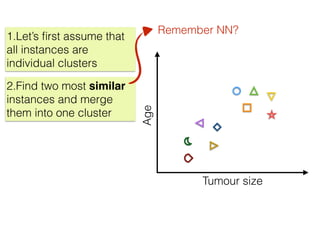
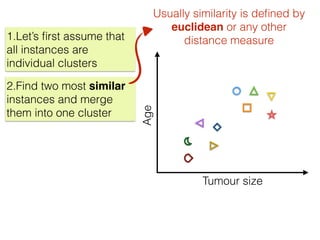
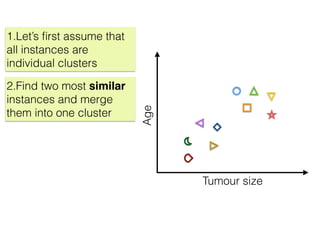
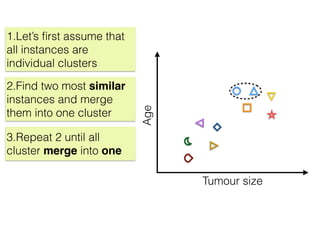
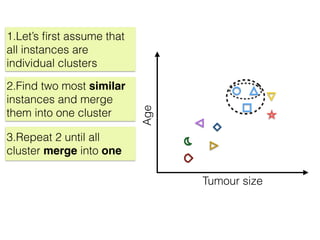
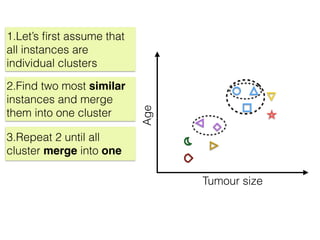
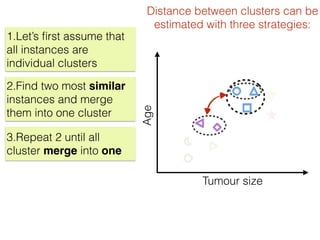
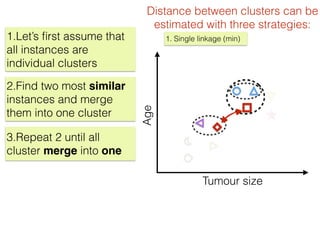
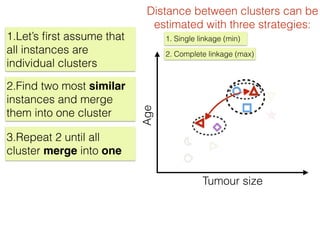
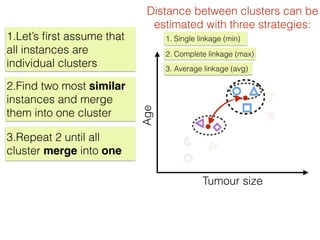
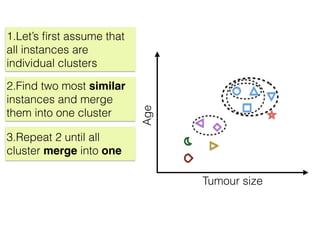
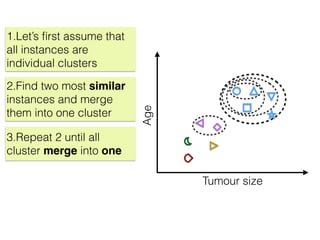
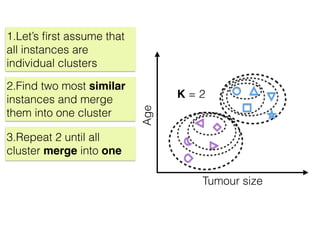
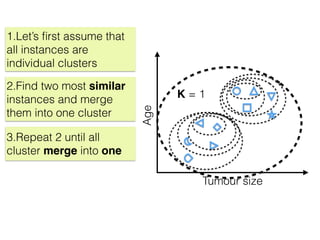
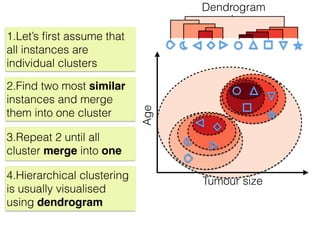
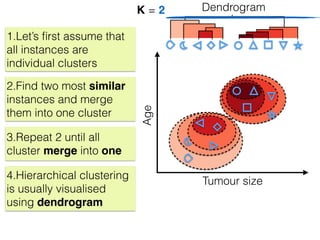
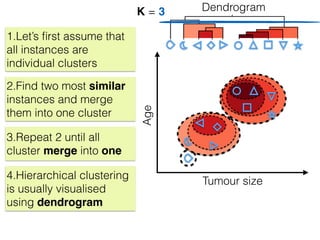
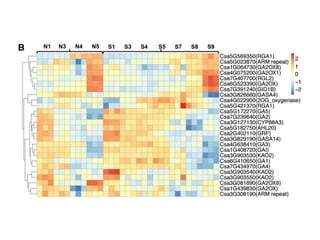
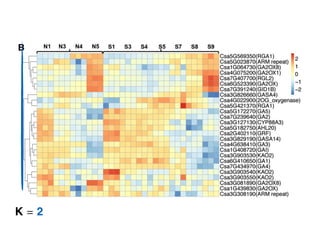
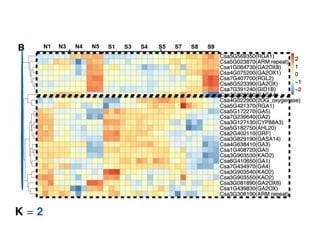


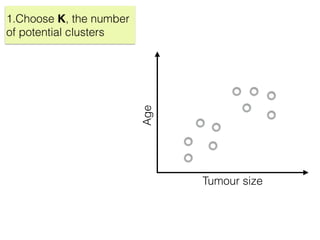
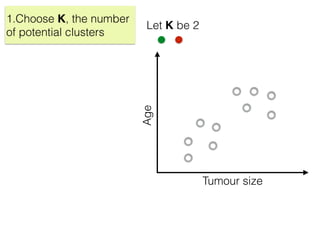
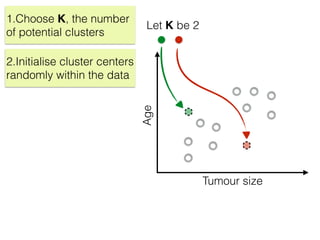
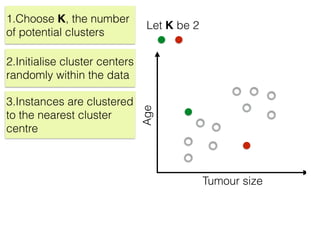
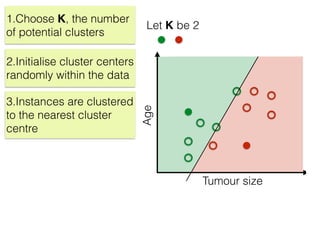
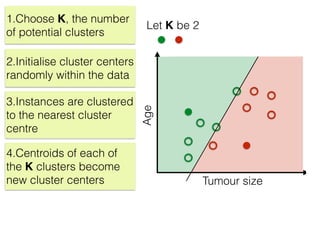
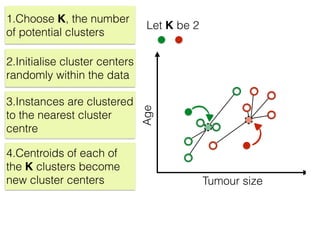
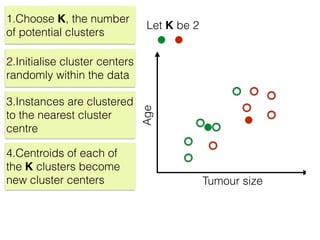
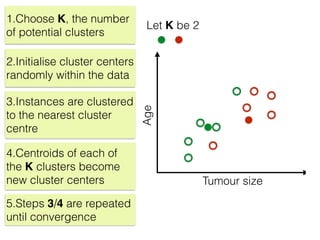
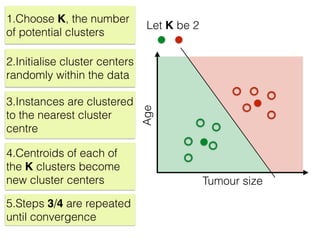
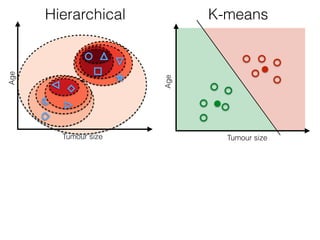
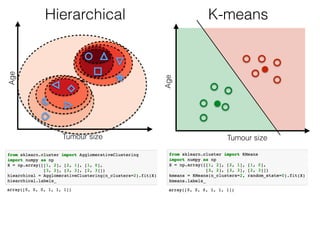
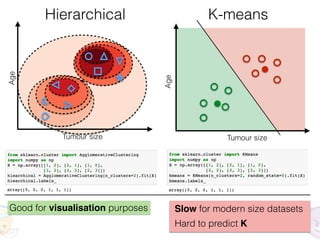





The document discusses unsupervised learning in machine learning, focusing on clustering methods such as hierarchical clustering and k-means clustering. It details processes for grouping data points into clusters based on their similarities, and outlines steps for algorithms, including the selection of cluster centers and convergence criteria. Additionally, it mentions references for further learning about machine learning concepts and techniques.




























































