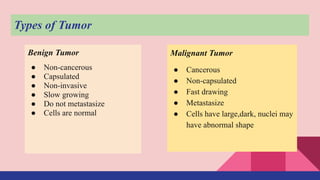
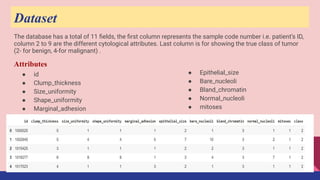
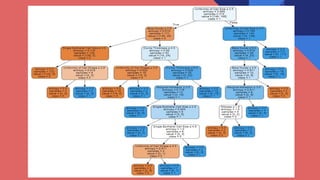
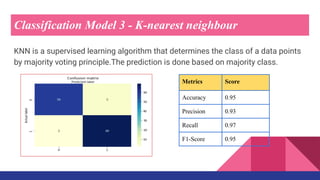
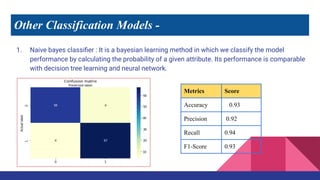
This document describes a machine learning project to classify breast cancer tumors as either benign or malignant. The project uses a dataset containing attributes of breast cancer cases to build classification models using logistic regression, decision trees, k-nearest neighbors, and naive bayes. The k-nearest neighbors model achieved the highest accuracy of 95% and recall of 97%, making it the best performing model for this classification task.