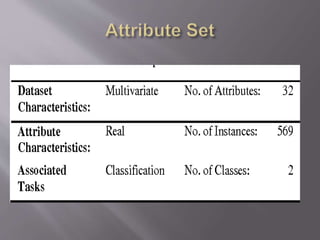
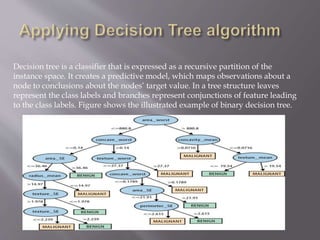
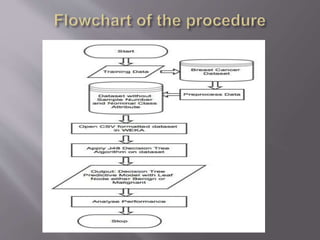
Cancer is a disease caused by abnormal cell growth and can affect different cell types. This paper focuses on breast cancer, which is classified based on the type of affected cell. There are several risk factors that can increase the likelihood of developing cancer, including gender, age, genetics, family history, weight, alcohol use, and smoking. The dataset used contains information from 569 breast cancer cases, including demographic and cell feature data. Machine learning algorithms like decision trees can be applied to build models for diagnosing breast cancer based on these attributes with up to 96.46% accuracy.