Download as PDF, PPTX













![[1]. Survey of Task Scheduling Methods for MapReduce Framework in Hadoop.
This paper discusses about the survey of various earlier scheduling methods which have been proposed.
These scheduling methods include-
First In First Out scheduler,
Fair Scheduler,
Capacity Scheduler,
LATE scheduler,
Deadline constraint scheduler,
Etc.,
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-17-2048.jpg)
![[1]. Conclusion and future scope
By achieving data locality in the MapReduce framework performance can be improved.
Finally they concluded with how we can consider the scheduling methods in Hadoop heterogeneous clusters.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-18-2048.jpg)
![[2]. Perform Wordcount MapReduce Job in Single Node Apache Hadoop Cluster & Compress Data Using LZO Algorithm.
Applications like Yahoo, Facebook, and Twitter have huge data which has to be stored and retrieved as per client access.
This huge data storage requires huge database leading to increase in physical storage and becomes complex for analysis required in business growth.
Lempel-Ziv-Oberhumer (LZO) algorithm, is used to compress the redundant data.
LZO algorithm is developed by considering the “Speed as the Priority”.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-19-2048.jpg)
![[2]. Conclusion and future scope
LZO algorithm compress the file 5 times faster than the gzip format.
Decompression ratio of LZO algorithm is 2 times the faster than gzip format.
Size of the LZO file is slightly larger than the gzip file after the compression.
Compressed file using LZO or gzip format is very much smaller than the original file.
In future we can implement this in heterogeneous multinode clusters.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-20-2048.jpg)
![[3]. S3: An Efficient Shared Scan Scheduler on MapReduce Framework.
To improve performance, multiple jobs operating on a common data file can be processed as a batch to share the cost of scanning the file.
Jobs often do not arrive at the same time.
S3 operates like this: At the same time-
System may be processing a batch of sub-jobs,
Also there are sub-jobs which are waiting in job-queue,
As a new job arrives,
Its sub-jobs can be aligned with waiting jobs in job-queue,
Once the current-batch of sub-jobs completes processing-
Then next batch of sub-jobs is initiated for processing.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-21-2048.jpg)
![[3]. Conclusion and future scope
S3 can exploit the sharing of data scan to improve performance.
Unlike existing batch-based schedulers S3 allows jobs to be processed as they arrive, and arriving job does not need to wait for long time.
More computational policies such as computational resources and job priorities can be added to S3 to make more flexible.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-22-2048.jpg)
![[4]. Two Sides of a Coin: Optimizing the Schedule of MapReduce Jobs to Minimize their Makespan and Improve Cluster Performance.
This paper proposes the key- challenge to increase the utilization of MapReduce clusters.
Here the goal is to automate the design of a job schedule that minimizes the completion- time or deadline of MapReduce jobs.
A novel abstraction framework and a heuristic called BalancedPools are discussed.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-23-2048.jpg)
![[4]. Conclusion and future scope
They have simulated the things over a realistic workload and observed that 15%-38% completion-time improvements.
This shows that, the order in which jobs executed can have significant impact on their overall completion-time and the cluster resource utilization.
Future step may include addressing a more general problem of minimizing the deadline of batch workloads.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-24-2048.jpg)
![[5]. ThroughputScheduler: Learning to Schedule on Heterogeneous Hadoop Clusters.
Presently available schedulers for Hadoop clusters assign tasks to nodes without regard to the capability of the nodes.
This paper proposes a method, which reduces the overall job completion time on a cluster of heterogeneous nodes by actively scheduling tasks on nodes based on optimally matching job requirements to node capabilities.
Node capabilities are learned by running probe jobs on the cluster.
Bayesian active learning scheme is used to learn source requirements of jobs on-the-fly.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-25-2048.jpg)
![[5]. Conclusion and future scope
The framework learns both server capabilities and job task parameters autonomously.
ThroughputScheduler can reduce total job completion time by almost 20% compared to the Hadoop Fair Scheduler and 40% compared to FIFO Scheduler.
ThroughputScheduler also reduces average mapping time by 33% compared to either of these schedulers.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-26-2048.jpg)

![References
[1]. J. Dean and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters.” Proc. Sixth Symp. Operating System Design and Implementation, San Francisco, CA, Dec. 6-8, Usenix, 2004. [2]. Lei Shi, Xiaohui Li, Kian-Lee Tan, “S3: An Efficient Shared Scan Scheduler on MapReduce Framework.”, School of Computing National University of Singapore, comp.nus.edu.sg, 2012. [3]. Dr. Umesh Bellur, Nidhi Tiwari, “Scheduling and Energy Efficiency Improvement Techniques for Hadoop MapReduce: State of Art and Directions for Future Research.”, Department of Computer Science and Engineering Indian Institute of Technology, Mumbai. [4]. Abhishek Verma, Ludmila Cherkasova, Roy H. Campbell, “Two Sides of a Coin: Optimizing the Schedule of MapReduce Jobs to Minimize Their Makespan and Improve Cluster Performance.”, HP Labs. Supported in part by Air Force Research grant FA8750-11-2-0084. [5]. Nandan Mirajkar, Sandeep Bhujbal, Aaradhana Deshmukh, “Perform Wordcount MapReduce Job in Single Node Apache Hadoop Cluster and Compress Data Using Lempel-Ziv-Oberhumer (LZO) Algorithm.”, Department of Advanced Software and Computing Technologies IGNOU –I2IT, Centre of Excellence for Advanced Education and Research Pune, India.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-28-2048.jpg)
![References continued…
[6]. Houvik B Ardhan, Daniel A. Menasce. “The Anatomy of MapReduce Jobs, Scheduling, and Performance Challenges”, Proceedings of the 2013 Conference of the Computer Measurement Group, San Diego, CA, November 5-8, 2013. [7]. Shekhar Gupta, Christian Fritz, Bob Price, Roger Hoover, and Johan de Kleer, “ThroughputScheduler: Learning to Schedule on Heterogeneous Hadoop Clusters”, USENIX Association, 10th International Conference on Autonomic Computing (ICAC 2013). [8]. Nilam Kadale, U. A. Mande, “Survey of Task Scheduling Method for MapReduce Framework in Hadoop.”, 2nd National Conference on Innovative Paradigms in Engineering & Technology (NCIPET 2013). [9]. Tom Wille, “Hadoop: The Definitive Guide.” 2nd edition, O’Reilly publications, Sebastopol, CA 95472. October 2010. [10]. J Jeffery Hanson. “An Introduction to the Hadoop Distributed File System.” IBM DeveloperWorks, 2011.
Dept. of ISE, AIT, Bangalore](https://image.slidesharecdn.com/bigdataseminarbymants-131224083456-phpapp02-140927020157-phpapp02/75/BIGDATA-Survey-on-Scheduling-Methods-in-Hadoop-MapReduce-Framework-29-2048.jpg)


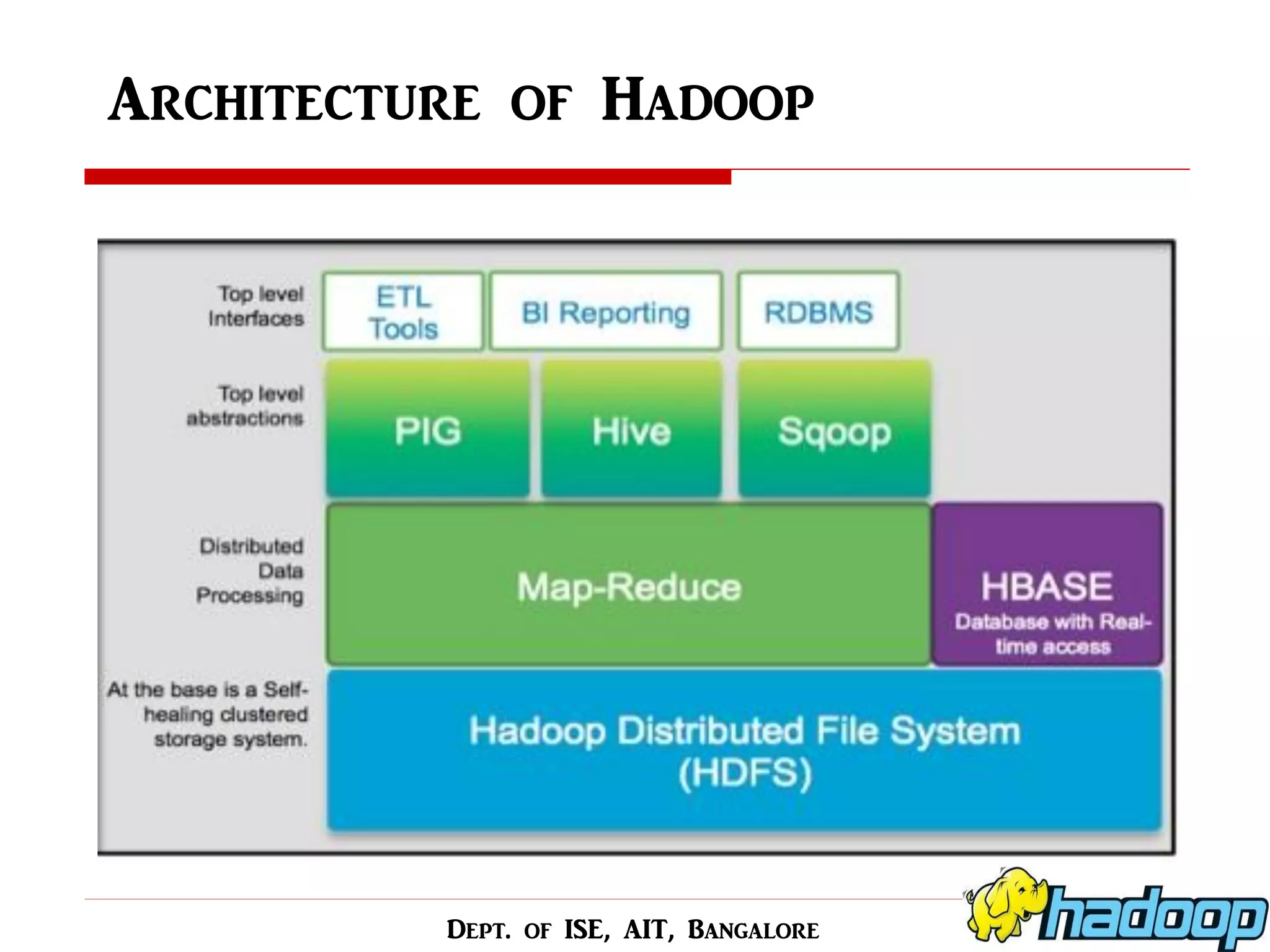
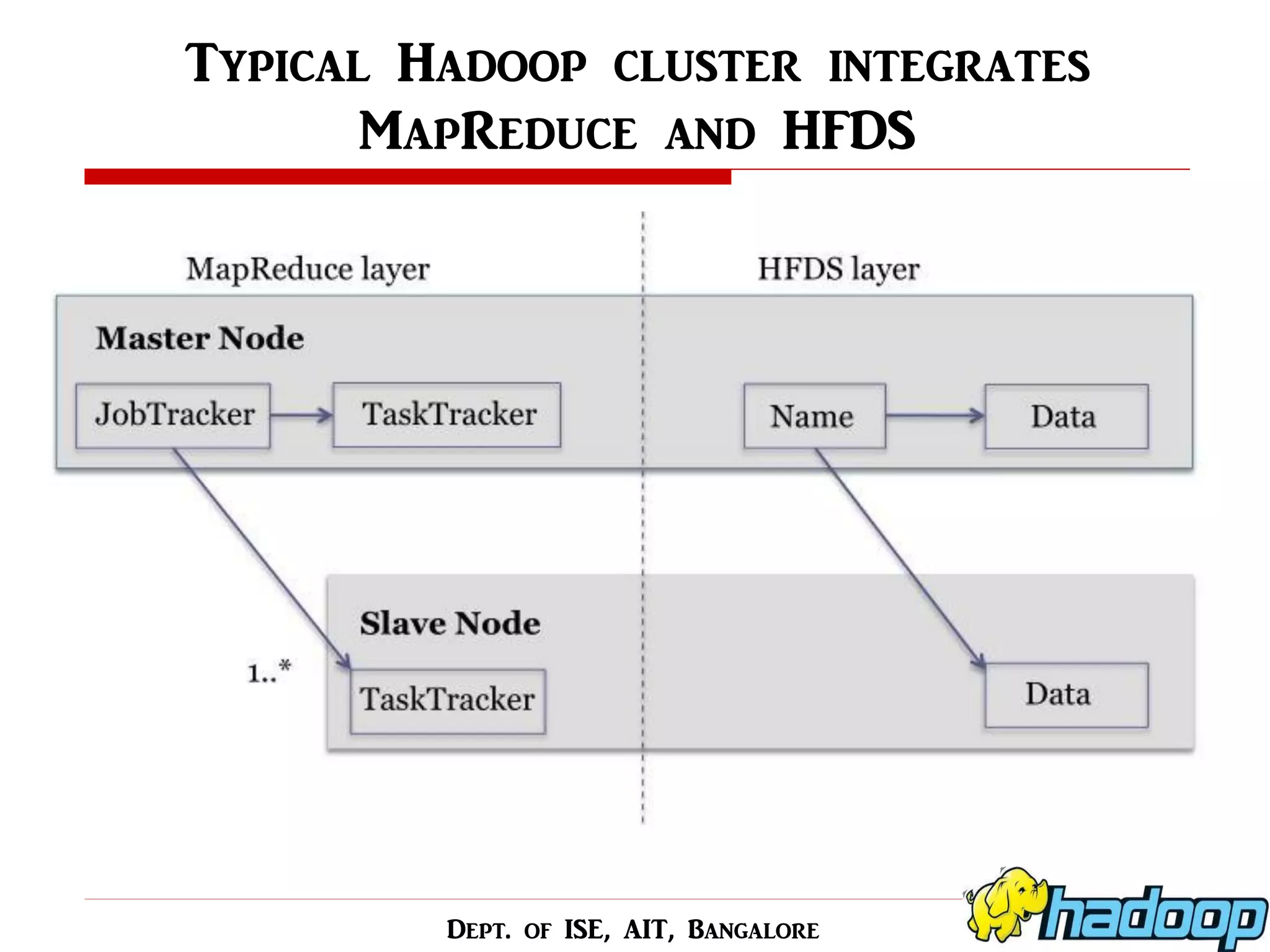
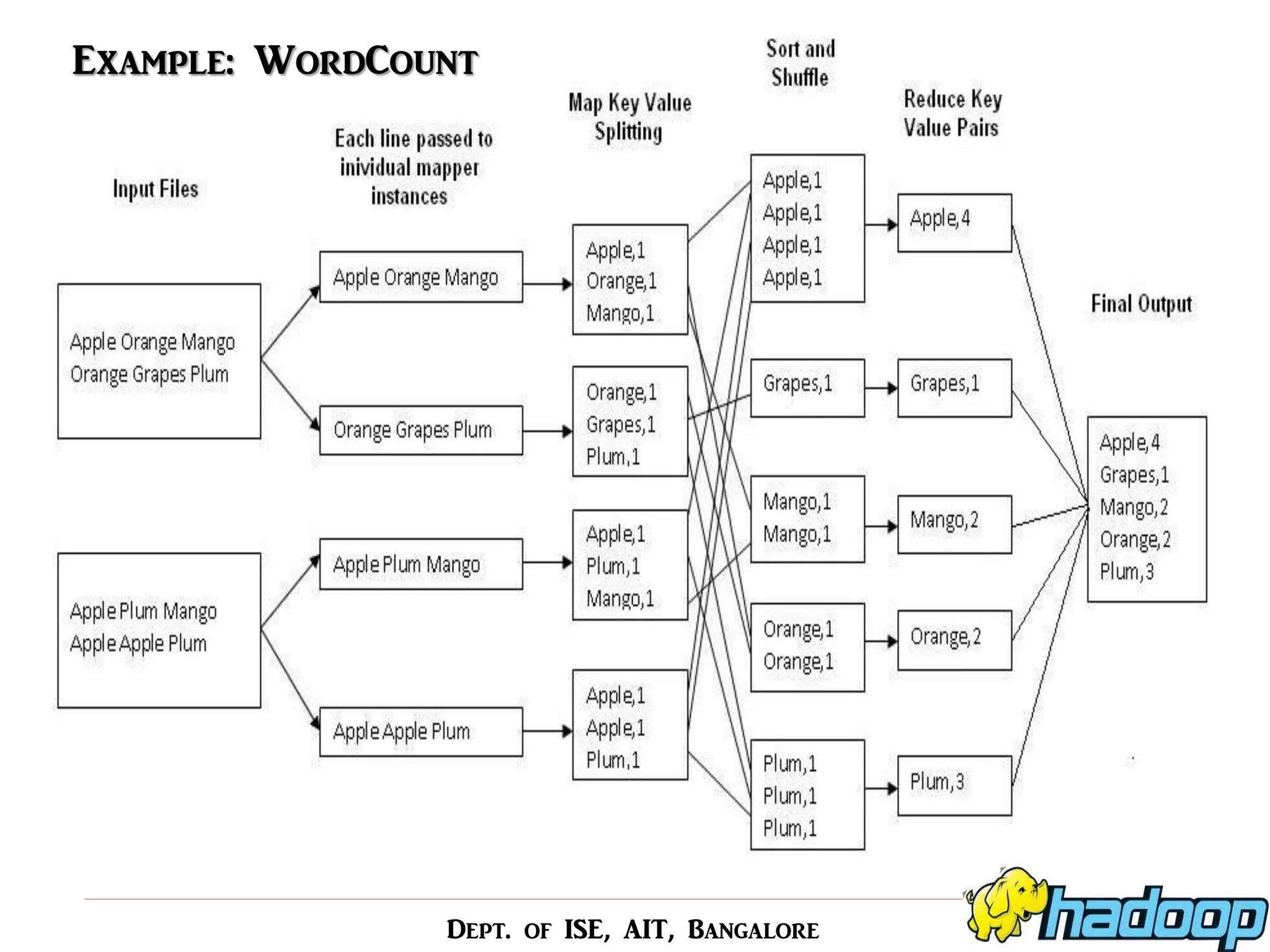
This seminar presentation provides an overview of scheduling methods in the Hadoop MapReduce framework. It begins with motivations for using distributed computing for big data and introduces Hadoop and MapReduce. The presentation then surveys several proposed scheduling methods, including static methods like FIFO and adaptive methods like the Fair Scheduler. It summarizes five research papers on scheduling, discussing proposed approaches like optimizing job completion time and learning node capabilities for heterogeneous clusters. The presentation concludes that scheduling algorithms should improve data locality and use prediction to efficiently schedule jobs on heterogeneous Hadoop clusters.

















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)












