포먼트 합성
음향정보를 기반으로 하여 규칙과 필터를 이용하여 각각의 포먼트를 합성
1980년 이전 대부분의 합성 방식
MITalk
DECtalk
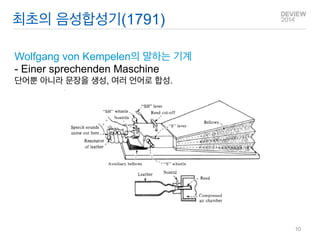
Stephen Hawking
20
21.
포먼트 합성
StephenHawking: http://www.youtube.com/watch?v=w0QY4cGY0pU
21
22.
편집 합성
음성데이터베이스를 기반으로 개별 단위를 편집하여 합성
최초의 편집 합성 시스템: Talking Clock (1936)
단어나 구를 녹음
녹음된 단위를 편집하여 합성
Radio Free Vestibule (1994)
Bell Labs TTS: 1977, 1985
22
23.
편집 합성
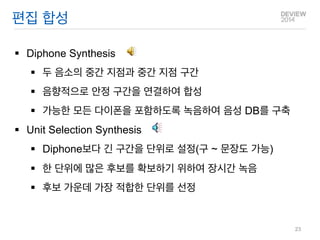
DiphoneSynthesis
두 음소의 중간 지점과 중간 지점 구간
음향적으로 안정 구간을 연결하여 합성
가능한 모든 다이폰을 포함하도록 녹음하여 음성 DB를 구축
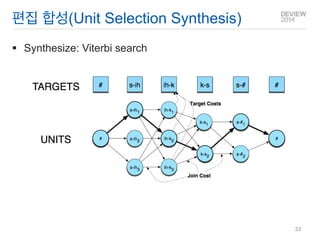
Unit Selection Synthesis
Diphone보다 긴 구간을 단위로 설정(구 ~ 문장도 가능)
한 단위에 많은 후보를 확보하기 위하여 장시간 녹음
후보 가운데 가장 적합한 단위를 선정
23
24.
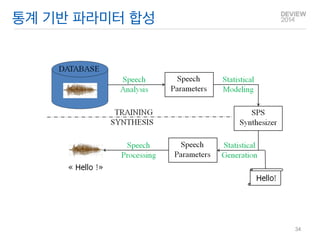
통계 기반 파라미터합성
편집 합성의 문제점
음성 처리(변조)가 용이하지 않음.
DB가 충분하지 않은 경우에 성능이 저하됨.
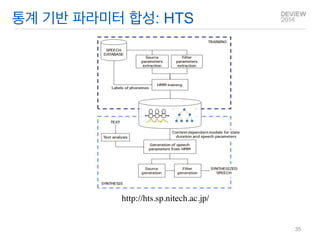
HMM 기반 파라미터 음성합성
DB로부터 통계적인 방법으로 파라미터를 학습.
파라미터의 조정을 통한 음성 변조가 용이함.
기존 편집 합성 성능을 보완할 수 있음.
편집 합성(USS) vs. 파라미터 합성(HMM)
Roger
Nina
24
25.
편집 합성 vs.파라미터 합성
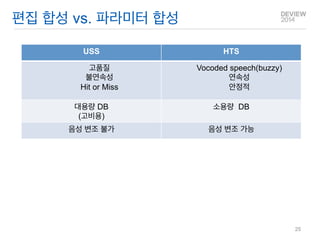
USS
HTS
고품질
불연속성
Hit or Miss
Vocoded speech(buzzy)
연속성
안정적
대용량 DB
(고비용)
소용량 DB
음성 변조 불가
음성 변조 가능
25
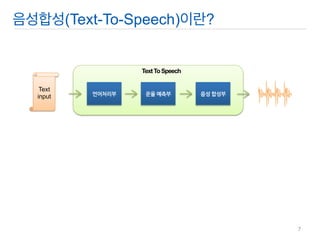
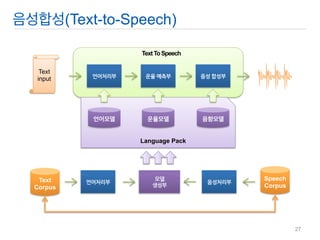
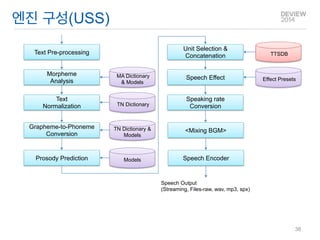
언어처리부
운율 예측부
음성 합성부
Text input
Text To Speech
언어모델
운율모델
음향모델
Language Pack
Text Corpus
Speech Corpus
언어처리부
모델 생성부
음성처리부
음성합성(Text-to-Speech)
27
28.
언어처리부
텍스트정규화(Text Normalization)
예제
일본이 최근 미국 보잉사로부터 도입한 E 767기 흔히 AWACS라고 불리는 조기경보 통제기로 미국도 아직 보유하지 못한 최신예깁니다
대장균 균이 가장 많이 검출된 제품은 일경식품의 와퍼로 1g당 4만마리가 나왔으며 한국 맥도널드의 빅맥에서도 1g당 64만마리가 검출됐습니다.
문장 내의 숫자, 기호, 외국어, 등 여러가지 문제들을 처리하는 모듈
방법론: 규칙 기반 혹은 통계 기반 방법
28
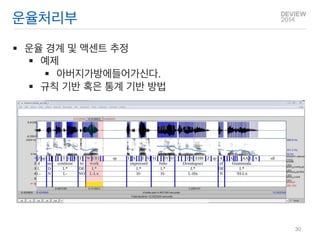
운율처리부
운율 경계및 액센트 추정
예제
아버지가방에들어가신다.
규칙 기반 혹은 통계 기반 방법
30
31.
편집 합성: UnitSelection Synthesis
합성 방법: 전사된 DB 가운데 합성하고자 하는 최적의 단위를 선정
최적의 의미
Target cost: Find closest match in terms of
Phonetic context
F0, stress, phrase position
Join cost: Find best join with neighboring units
Matching formants + other spectral characteristics
Matching energy
Matching F0
31
32.
편집 합성(Unit SelectionSynthesis)
Total Costs
We now have weights (per phone type) for features set between target and database units
Find best path of units through database that minimize:
Standard problem solvable with Viterbi search with beam width constraint for pruning
32
NVOICE: NAVER 다국어음성 합성 엔진
개발 언어
한국어
영어
일본어
합성 방식
Unit Selection Synthesis (USS)
대용량 엔진
소용량 엔진
Statistical Parametric Synthesis: HTS
Hybrid
37
발성목록 설계
도메인별 모집단 코퍼스
국내/외 신문 텍스트 사용
14개 큰 도메인, 244개 상세 도메인 구성
문장선정 알고리즘
Word 기반으로 문장을 선정
WCR + CCR + Entropy 조합으로 문장을 선정
WCR : Word Cover Rate, 모집단 문장셋 전체 고유 단어 수와 선정 문장셋의 고유 단어 수 비율
CCR : 각 고유단어의 발생빈도(확률)을 고려한 WCR, 모집단 코퍼스의 coverage
Entropy : 각 고유 단어 발생빈도(확률) 을 이용한 선정 문장의 평균 정보량
39
40.
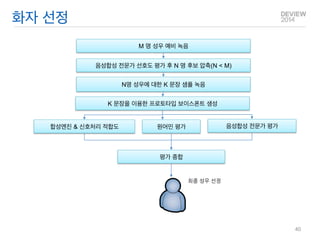
화자 선정
M명 성우 예비 녹음
음성합성 전문가 선호도 평가 후 N 명 후보 압축(N < M)
N명 성우에 대한 K 문장 샘플 녹음
K 문장을 이용한 프로토타입 보이스폰트 생성
합성엔진 & 신호처리 적합도 원어민 평가 음성합성 전문가 평가
평가 종합
최종 성우 선정
40
41.
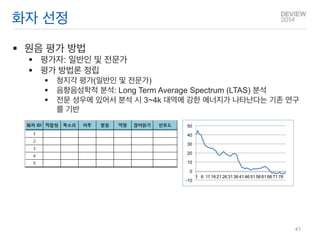
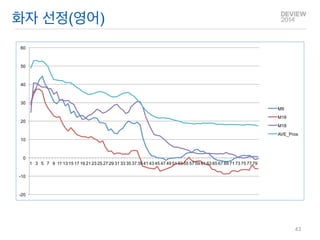
화자 선정
원음평가 방법
평가자: 일반인 및 전문가
평가 방법론 정립
청지각 평가(일반인 및 전문가)
음향음성학적 분석: Long Term Average Spectrum (LTAS) 분석
전문 성우에 있어서 분석 시 3~4k 대역에 강한 에너지가 나타난다는 기존 연구를 기반
-20
0
20
40
60
1
6
11
16
21
26
31
36
41
46
51
56
61
66
71
76
41
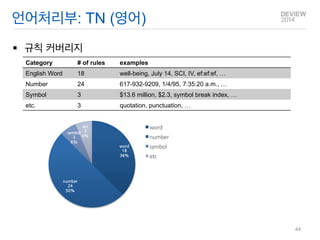
언어처리부: TN (영어)
규칙 커버리지
word 18 38%
number 24 50%
symbol 3 6%
etc 3 6%
word
number
symbol
etc
Category
# of rules
examples
English Word
18
well-being, July 14, SCI, IV, ef:ef:ef, …
Number
24
617-932-9209, 1/4/95, 7:35:20 a.m., …
Symbol
3
$13.6 million, $2.3, symbol break index, …
etc.
3
quotation, punctuation, …
44
45.
품사 태깅 정확도
95.54%
초당 분석 문장 수
약 1,022 문장 (1 문장당 평균 20토큰)
초당 분석 토큰 수
약 21,180 토큰
메모리 사용량
약 11MB
사전 및 모델 크기
약 3MB
내용
끊어 읽기 및 발음 등 합성에서의 형태소 사전 편집의 용이성을 제공
성능
언어처리부: 품사 태거 (영어)
45
46.
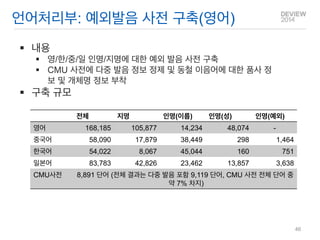
내용
영/한/중/일 인명/지명에대한 예외 발음 사전 구축
CMU 사전에 다중 발음 정보 정제 및 동철 이음어에 대한 품사 정보 및 개체명 정보 부착
구축 규모
언어처리부: 예외발음 사전 구축(영어)
전체
지명
인명(이름)
인명(성)
인명(예외)
영어
168,185
105,877
14,234
48,074
-
중국어
58,090
17,879
38,449
298
1,464
한국어
54,022
8,067
45,044
160
751
일본어
83,783
42,826
23,462
13,857
3,638
CMU사전
8,891 단어 (전체 결과는 다중 발음 포함 9,119 단어, CMU 사전 전체 단어 중 약 7% 차지)
46
47.
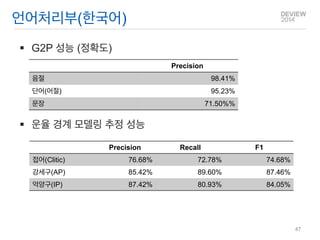
G2P 성능 (정확도)
운율 경계 모델링 추정 성능
언어처리부(한국어)
Precision
Recall
F1
접어(Clitic)
76.68%
72.78%
74.68%
강세구(AP)
85.42%
89.60%
87.46%
억양구(IP)
87.42%
80.93%
84.05%
Precision
음절
98.41%
단어(어절)
95.23%
문장
71.50%%
47
48.
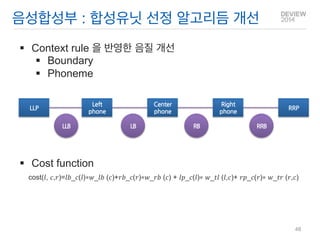
Context rule 을반영한 음질 개선
Boundary
Phoneme
Cost function cost(푙, 푐,푟)=푙푏_푐(푙)∗푤_푙푏 (푐)+푟푏_푐(푟)∗푤_푟푏 (푐) + 푙푝_푐(푙)∗ 푤_푡푙 (푙,푐)+ 푟푝_푐(푟)∗ 푤_푡푟 (푟,푐)
음성합성부 : 합성유닛 선정 알고리듬 개선
LLP
Left
phone
Right
phone
RRP
LLB
RB
Center
phone
LB
RRB
48
49.
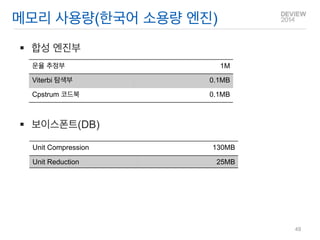
합성 엔진부
보이스폰트(DB)
메모리 사용량(한국어 소용량 엔진)
Unit Compression
130MB
Unit Reduction
25MB
운율 추정부
1M
Viterbi 탐색부
0.1MB
Cpstrum 코드북
0.1MB
49
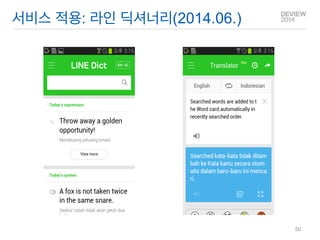
음성합성 샘플(영어)
Vanityand pride are different two things, though the words are often used synonymously. A person may be proud without being vain. Pride relates more to our opinion of ourselves, vanity, to that we would have others think of us. Jane Austen
51


































![[C++ Korea 3rd Seminar] 새 C++은 새 Visual Studio에, 좌충우돌 마이그레이션 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/ckorea3rdseminarcvisualstudio-170218150400-thumbnail.jpg?width=640&height=640&fit=bounds)















![제 15회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Find Your Style 팀] : 사용자 이미지 라벨링을 통한 의류 추천 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/04findyourstyle-220124104046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]누구나 만드는 내 목소리 합성기 (부제: 그게 정말 되나요?)](https://cdn.slidesharecdn.com/ss_thumbnails/222voice-181012004315-thumbnail.jpg?width=640&height=640&fit=bounds)








![[A2]android security의 과거와 미래 – from linux to jelly bean](https://cdn.slidesharecdn.com/ss_thumbnails/a2androidsecurityfromlinuxtojellybean-120919013120-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[F1]nuance](https://cdn.slidesharecdn.com/ss_thumbnails/f1nuance-120919022014-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2SF] Naver 오픈 API 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/naver-api20160509-160601074917-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 CAMPUS] 분야별 모임 '보안' 발표자료](https://cdn.slidesharecdn.com/ss_thumbnails/random-170117071928-thumbnail.jpg?width=640&height=640&fit=bounds)







![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[F2]자연어처리를 위한 기계학습 소개](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NUGU Conference 2018] 세션 B-1 : 음성인식 기술 및 응용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/b-1-181031060358-thumbnail.jpg?width=640&height=640&fit=bounds)





![제 20회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [B01Z] HAP-PY_음성 인식 기반 AI 면접 솔루...](https://cdn.slidesharecdn.com/ss_thumbnails/b01zhap-pyai-240812134440-ff36618d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Innovate 온라인 컨퍼런스] 한국어를 위한 AWS 인공지능(AI) 서비스 소개 및 활용 방법 - 강정희, AWS 솔루션즈 아키텍트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session3jungheekang-200319071626-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NUGU Conference 2018] 세션 B-3.2 : 지식기술 소개 2](https://cdn.slidesharecdn.com/ss_thumbnails/b-3-2-181031061921-thumbnail.jpg?width=640&height=640&fit=bounds)



![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)