협력필터
Wij : itemi와 j간의 weight
Conditional probability를 이용하여
score를 계산
qi : item의 특성을 n개의 feature로 표현
pu : 사용자의 특성을 n개의 feature로 표현
사용자와 아이템을 똑같은 n차원의 feature
로 표현하여 둘의 곱으로 선호도를 구함. 전역
적인 특성이 있음
w : feature의 weight
Ii : i 번째 아이템의 feature
각 feature의 global한 weght를 구하여 적
용한다.
Neighborhood
model
1 Factor model2 Contents model3
User behavior 이용 Contents 정보 이용User behavior 이용
𝑆𝑐𝑜𝑟𝑒 𝑢𝑖 = 2 𝑤𝑖𝑗 𝑃 𝑑78𝑑9 +
;∈= >
𝑞𝑖
@
A 𝑝𝑢 + 𝑤 A 𝐼𝑖 2 𝐼𝑗
;∈= >
15
0. 데이터 분석
데이터분석은 크게 5가지 작업으로 구분된다.
(1) Data Collection 수집
: 필요한 자료수집 ( 생각보다 어려움 )
(2) Descriptive Statistics - 기술통계
: 데이터를 이해하는 지점.
(3) Exploratory data analysis 탐구적 자료분석
: 같음, 다름을 찾아내는 지점.
(4) Hypothesis testing 가설검정
: 확신을 얻는 지점.
(5) Estimation 추정
: 모델을 완성하는 지점.
5가지를 균형있게 수행할 수 있는 사람을 ‘데이터사이언티스트’ 라고 한다.
19.
1. 기술통계 (DescriptiveStatistics)
- 데이터가 어떻게 생겼는지 이해하는 부분
“송중기가어떻게생겼는가?”
->잘생겼네.
->눈은어떻고,코는어떻고,…
평균
Median, quantile, variance, …
20.
1. 기술통계 (DescriptiveStatistics)
- 데이터가 어떻게 생겼는지 이해하는 부분
“기초통계를보고싶다”
데이터가 어떻게 생겼는지 알고싶다
[ multi modal 예제 ]
가장짧은말로,가장많은모습을설명한다.
! 대부분, 데이터를 이해하는 과정에서 분석의 전체 구조가 나온다.
21.
2. 탐구적 자료분석(Exploratory Data Analysis )
- 특징 ( 패턴 및 특이점) 찾는 부분
이중에유독다른한장을찾을수있
나?
① ②
③ ④
22.
2. 탐구적 자료분석(Exploratory Data Analysis )
- 패턴 및 특이점 찾는 부분
- SequenceMining
- Clustering
- Classification
- Topicmodeling
- Deeplearning
[ clustering 예제]
23.
3. 가설검정 (Hypothesistesting)
- 찾아낸 특징이 정말로 그러한지 확신하는 부분
“송중기와송혜교가만나는사이인
가?”
->증거: 반지,커플티..
24.
3. 가설검정 (Hypothesistesting)
- 찾아낸 특징이 정말로 그러한지 확신하는 부분
- P-value
- T test,Chisquaretest
- Likelihoodratio
- Crossvalidation
3.4 기초통계
입사한지 얼마안되었을 때.. “기초통계를 보고싶다”
“송중기가어떻게생겼는가?”
->잘생겼네.
->눈은어떻고,코는어떻고,…
평균
Median, quantile, variance, …
“데이터가 어떻게 생겼는지 알고싶다”
38.
3.5 분포통계
Dirichlet -드리쉴레.. 드리끌레.. 그건 어느 나라 말입니까? LDA ( 2010)
분포의 식에 현혹..
분포의 관계로 부터 출발
39.
3.5 분포통계
제가 사용하는분포 구조입니다.
베르누이 이항분포 정규분표
t분표
카이스퀘
어분표
F분표
다항분포
다변량정
규분표
베타분포
드리쉴레
분포
프아송
분포
감마분포
(지수분포)
검정통계continuousdiscrete
동전던지기
여러번 무한번
평균
제곱:
분산
나누기
일정시간
거꾸로
거꾸로
거꾸로
주사위
여러번
무한번
40.
3.5 분포통계
제가 사용하는분포 구조입니다.
베르누이 이항분포 정규분표
t분표
카이스퀘
어분표
F분표
다항분포
다변량정
규분표
베타분포
드리쉴레
분포
프아송
분포
감마분포
(지수분포)
검정통계continuousdiscrete
bernuill binomial
poisson
multinomial
Multivariate
normaml
gaussian
beta
dirichlet
Student t
Chi-square
F
Gamma
일정시간
-
3.6 회귀통계
Y가 좀너무 크거나, 작으면.. 약간 이상해 지는 느낌…
𝑦 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝜖
1년간 회사를 그만둔 사람 수? 좀 작은데..
연봉..? 좀 너무 숫자가 큰데..
poisson
gamma
44.
3.6 회귀통계
Y가 좀너무 크거나, 작으면.. 약간 이상해 지는 느낌…
𝑦 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝜖
1년간 회사를 그만둔 사람 수? 좀 작은데..
연봉..? 좀 너무 숫자가 큰데..
poisson
gamma
logistic
Multi
logistic
identity
45.
3.6 회귀통계 예제
노출되는랭킹과 클릭수와의 관계
𝑦 = 𝑤1 𝑥1 + 𝜖
10000 = w*1등 + error
5000 = w*2등 + error
중요한건 Y 의 분포 à 분포를 알아야..
log ( 𝑦) = 𝑤1 𝑥1 + 𝜖
LINEARNON-L
46.
3.6 통계
분포 +회귀 + 검정 à 경험으로 습득
poisson
gamma
logistic
Multi
logistic
identity
평균
분산






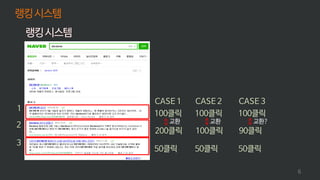
![랭킹시스템
1
2
3
[능력] =[순수능력]+[위치능력]
𝜂1
𝜂2
𝜂3
𝜂 = 𝜙 + 𝑥𝛽
100 = 70 + 30
90 = 75 + 15
50 = 45 + 5
7](https://image.slidesharecdn.com/2-170224052557/85/2-7-320.jpg)












![1. 기술통계 (Descriptive Statistics)
- 데이터가 어떻게 생겼는지 이해하는 부분
“기초통계를보고싶다”
데이터가 어떻게 생겼는지 알고싶다
[ multi modal 예제 ]
가장짧은말로,가장많은모습을설명한다.
! 대부분, 데이터를 이해하는 과정에서 분석의 전체 구조가 나온다.](https://image.slidesharecdn.com/2-170224052557/85/2-20-320.jpg)

![2. 탐구적 자료분석 (Exploratory Data Analysis )
- 패턴 및 특이점 찾는 부분
- SequenceMining
- Clustering
- Classification
- Topicmodeling
- Deeplearning
[ clustering 예제]](https://image.slidesharecdn.com/2-170224052557/85/2-22-320.jpg)




























![[D2 CAMPUS] Tech meet-up `data science` 발표자료](https://cdn.slidesharecdn.com/ss_thumbnails/random-170411050317-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]딥러닝예제로보는개발자를위한통계 최재걸](https://cdn.slidesharecdn.com/ss_thumbnails/216-161025031655-thumbnail.jpg?width=640&height=640&fit=bounds)


![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











![[D2 오픈세미나]4.네이티브앱저장통신](https://cdn.slidesharecdn.com/ss_thumbnails/4-140804011236-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D2 오픈세미나]5.robolectric 안드로이드 테스팅](https://cdn.slidesharecdn.com/ss_thumbnails/5-140804011233-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 오픈세미나]3.web view hybridapp](https://cdn.slidesharecdn.com/ss_thumbnails/3-140804011233-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2CAMPUS] Algorithm tips - ALGOS](https://cdn.slidesharecdn.com/ss_thumbnails/algospart1-d2-170223060957-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] ECMAScript 2015 S67 seminar - 1. primitive](https://cdn.slidesharecdn.com/ss_thumbnails/1primitive-161207024601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 오픈세미나]1.무한스크롤성능개선](https://cdn.slidesharecdn.com/ss_thumbnails/1-140804011241-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] Open Container Seoul Meetup - 마이크로 서비스 아키텍쳐와 Docker kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/dockerkubernetes-161207045638-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 COMMUNITY] Open Container Seoul Meetup - Running a container platform in ...](https://cdn.slidesharecdn.com/ss_thumbnails/runningacontainerplatforminproductionexperienceatgsshop-161207045420-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] ECMAScript 2015 S67 seminar - 3. generator](https://cdn.slidesharecdn.com/ss_thumbnails/3generator-161207024803-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 오픈세미나]2.모바일웹디버깅](https://cdn.slidesharecdn.com/ss_thumbnails/2-140804011239-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] Open Container Seoul Meetup - Kubernetes를 이용한 서비스 구축과 openshift](https://cdn.slidesharecdn.com/ss_thumbnails/kubernetesopenshift-161207045304-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 COMMUNITY] ECMAScript 2015 S67 seminar - 2. functions](https://cdn.slidesharecdn.com/ss_thumbnails/2functions-161207024734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] Open Container Seoul Meetup - Docker security](https://cdn.slidesharecdn.com/ss_thumbnails/dockersecurity-161207045539-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] ECMAScript 2015 S67 seminar - 4. promise](https://cdn.slidesharecdn.com/ss_thumbnails/4promise-161207024833-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2018joeunparksweat-180820041651-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Ankus Open Source Conference 2013] 빅데이터 분석을 위한 통계 이해와 해석](https://cdn.slidesharecdn.com/ss_thumbnails/random-131117193321-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[통계페스티발] 무덤에서 요람까지 통계와 함께](https://cdn.slidesharecdn.com/ss_thumbnails/20151217-151221153120-thumbnail.jpg?width=640&height=640&fit=bounds)









![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)