Download as KEY, PPTX







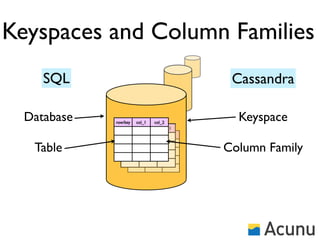


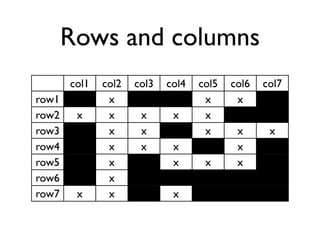
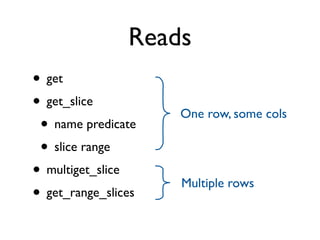
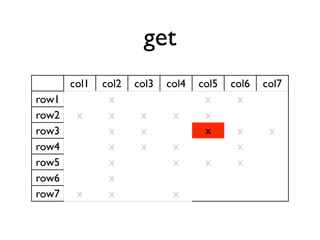
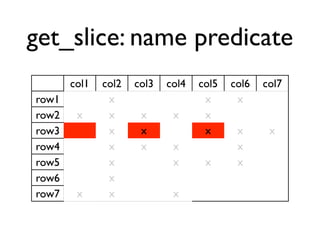
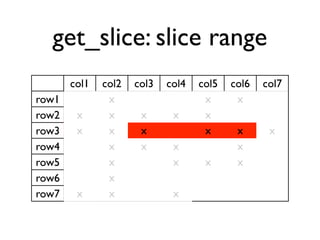
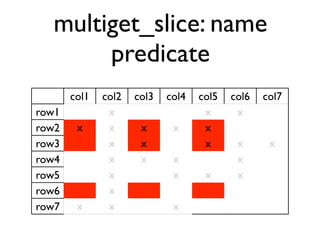
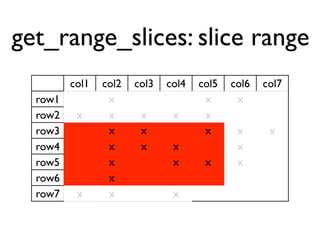

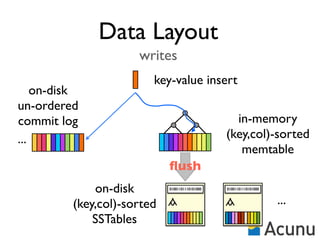
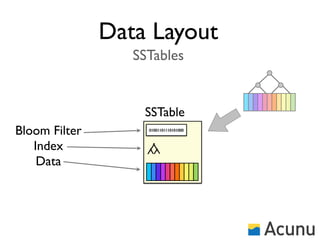
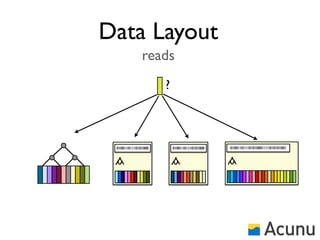
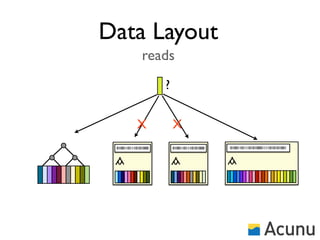

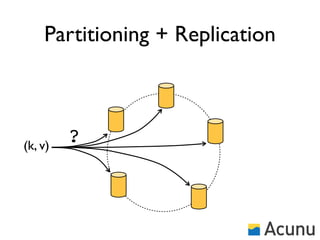


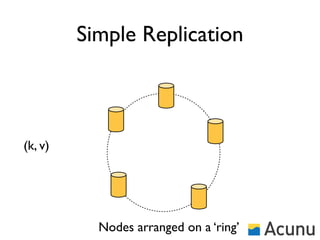
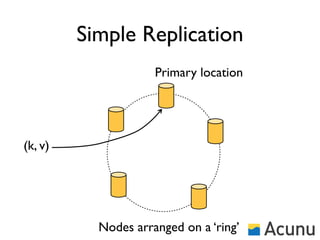
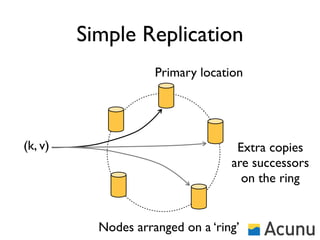

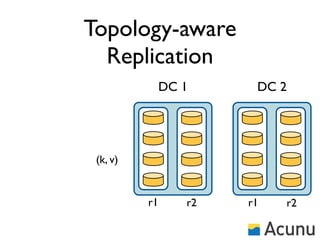
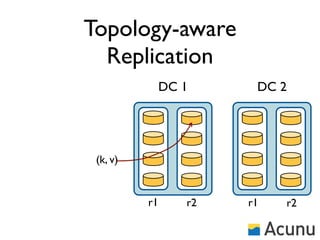
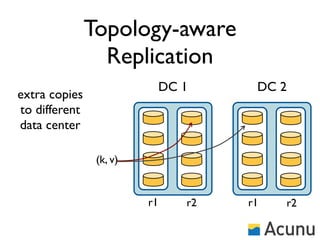
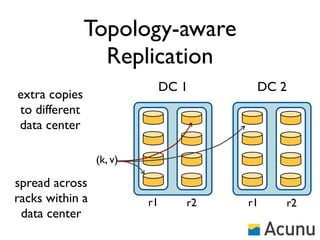




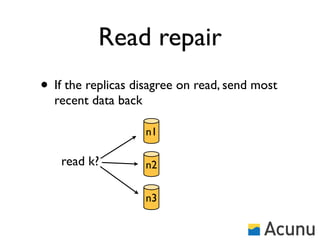
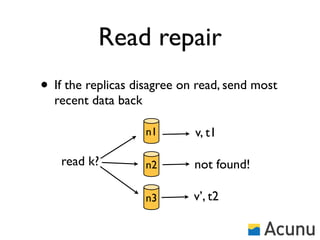
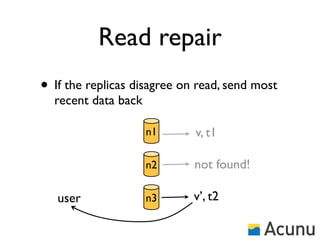
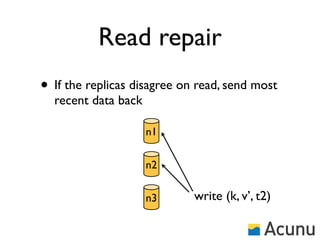




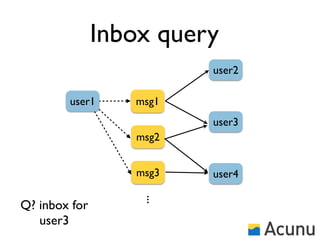










The document discusses the architecture and features of Cassandra, a distributed database developed by Facebook, which was open-sourced in 2008 and later became an Apache project. It highlights Cassandra's strengths, including horizontal scalability, high write workloads, and flexible consistency levels, while noting its limitations in handling transactions and read-heavy operations. The text also covers the data model, partitioning, replication strategies, and de-normalization techniques to optimize performance.



































































