Downloaded 90 times










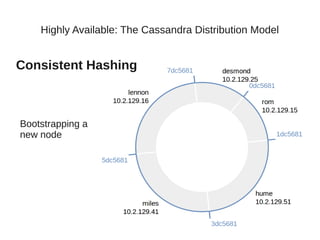


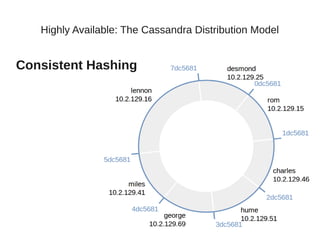

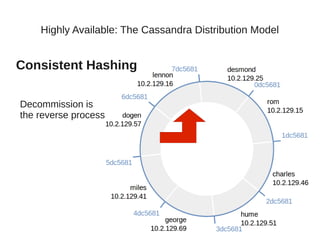
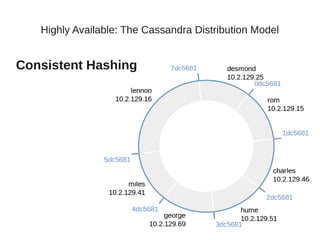












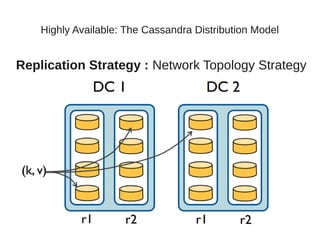











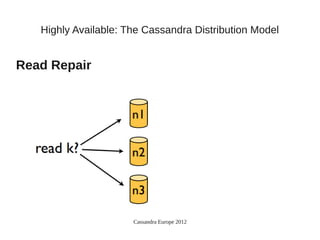

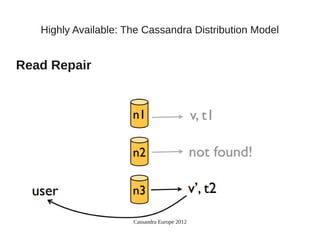

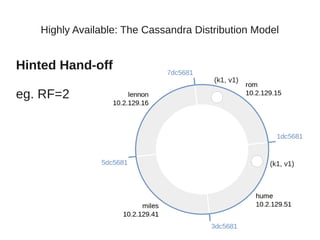


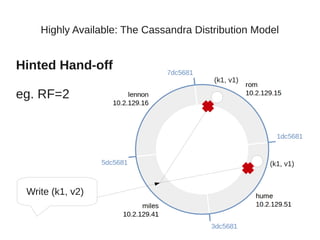


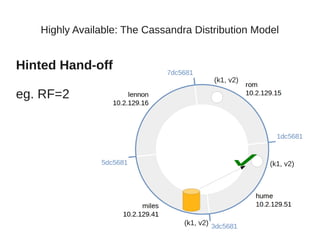





This document summarizes a presentation about Cassandra's highly available distributed data model. The presentation covers Cassandra's key capabilities of scalability, fault tolerance, tunable consistency, and replication without single points of failure. It discusses Cassandra's use of consistent hashing to partition and place data across nodes, as well as its replication strategies and consistency levels that allow tuning availability versus consistency.



































































