App Engine のこれまで3 年 - 進化を続けるプラットフォーム
Apr 2008 Python launch
May 2008 Memcache API, Images API
Jul 2008 Logs export
Aug 2008 Batch write/delete
Oct 2008 HTTPS support
Dec 2008 Status dashboard, quota details
Feb 2009 Billing, Remote API, Larger HTTP request/response size limits (10MB)
Apr 2009 Java launch, Bulkloader (DB import), Cron jobs, SDC
May 2009 Key-only queries, Quota API
Jun 2009 Task queue API, Django 1.0 support
Sep 2009 XMPP API, Remote API shell, Django 1.1 support
Oct 2009 Incoming email
Dec 2009 Blobstore API
Feb 2010 Datastore cursors, Async URLfetch, App stats
Mar 2010 Denial-of-Service filtering, eventual consistency support
May 2010 OpenID, OAuth, App Engine for Business, new bulkloader
Aug 2010 Namespaces, increased quotas, high perf image serving
Oct 2010 Instances console, datastore admin & bulk entity deletes
Dec 2010 Channel API, 10-minute tasks & cron jobs, AlwaysOn & Warmup
Jan 2011 High Replication datastore, entity copy b/w apps, 10-minute URLfetch
Feb 2011 Improved XMPP and Task Queue, Django 1.2 support
6.
ロードマップ
SSL accesson non-appspot.com domains
Full-text Search over Datastore
Support for Python 2.7
Background servers capable of running for longer than 30s
Support for running MapReduce jobs across App Engine datasets
Bulk Datastore Import and Export tool
Improved monitoring and alerting of application serving
Logging system improvements to remove limits on size and storage
Raise HTTP request and response size limits
Integration with Google Storage for Developers
Programmatic Blob creation in Blobstore
Quota and presence improvements for Channel API
Datastore の設計
非正規化 を嫌がらない - No join
必要な index のみ作成
最小限の Entity Group
トランザクションが必要な箇所のみ
可能なら速い方を使う
query より keys_only query が速い
query より get が速い
複数の get より batch get が速い
kind の分割が有効なケース
一部のプロパティだけ取得
少しの失敗を受け入れる
リトライ、deadline の指定
12.
Datastore の設計
非正規化 を嫌がらない - No join
必要な index のみ作成
最小限の Entity Group
トランザクションが必要な箇所のみ
可能なら速い方を使う
query より keys_only query が速い
query より get が速い
複数の get より batch get が速い
kind の分割が有効なケース
一部のプロパティだけ取得
少しの失敗を受け入れる
リトライ、deadline の指定
13.
Datastore の設計 -非正規化
Before
from google.appengine.ext import db
class User(db.Model):
name = db.StringProperty()
groups = db.ListProperty(db.Key)
class Group(db.Model):
name = db.StringProperty()
user = User.get(user_key)
group_names = [group.name for group in db.get(user.groups)]
14.
Datastore の設計 -非正規化
After
from google.appengine.ext import db
class User(db.Model):
name = db.StringProperty()
groups = db.ListProperty(db.Key)
group_names = db.StringListProperty()
class Group(db.Model):
name = db.StringProperty()
user = User.get(user_key)
# group_names = user.group_names
15.
Datastore の設計
非正規化 を嫌がらない - No join
必要な index のみ作成
最小限の Entity Group
トランザクションが必要な箇所のみ
可能なら速い方を使う
query より keys_only query が速い
query より get が速い
複数の get より batch get が速い
kind の分割が有効なケース
一部のプロパティだけ取得
少しの失敗を受け入れる
リトライ、deadline の指定
16.
Datastore の設計 -必要な index のみ作成
from google.appengine.ext import db
class MyModel(db.Model):
name = db.StringProperty()
total = db.IntegerProperty(indexed=False)
index が増えると書き込み速度は遅くなります
17.
Datastore の設計
非正規化 を嫌がらない - No join
必要な index のみ作成
最小限の Entity Group
トランザクションが必要な箇所のみ
可能なら速い方を使う
query より keys_only query が速い
query より get が速い
複数の get より batch get が速い
kind の分割が有効なケース
一部のプロパティだけ取得
少しの失敗を受け入れる
リトライ、deadline の指定
18.
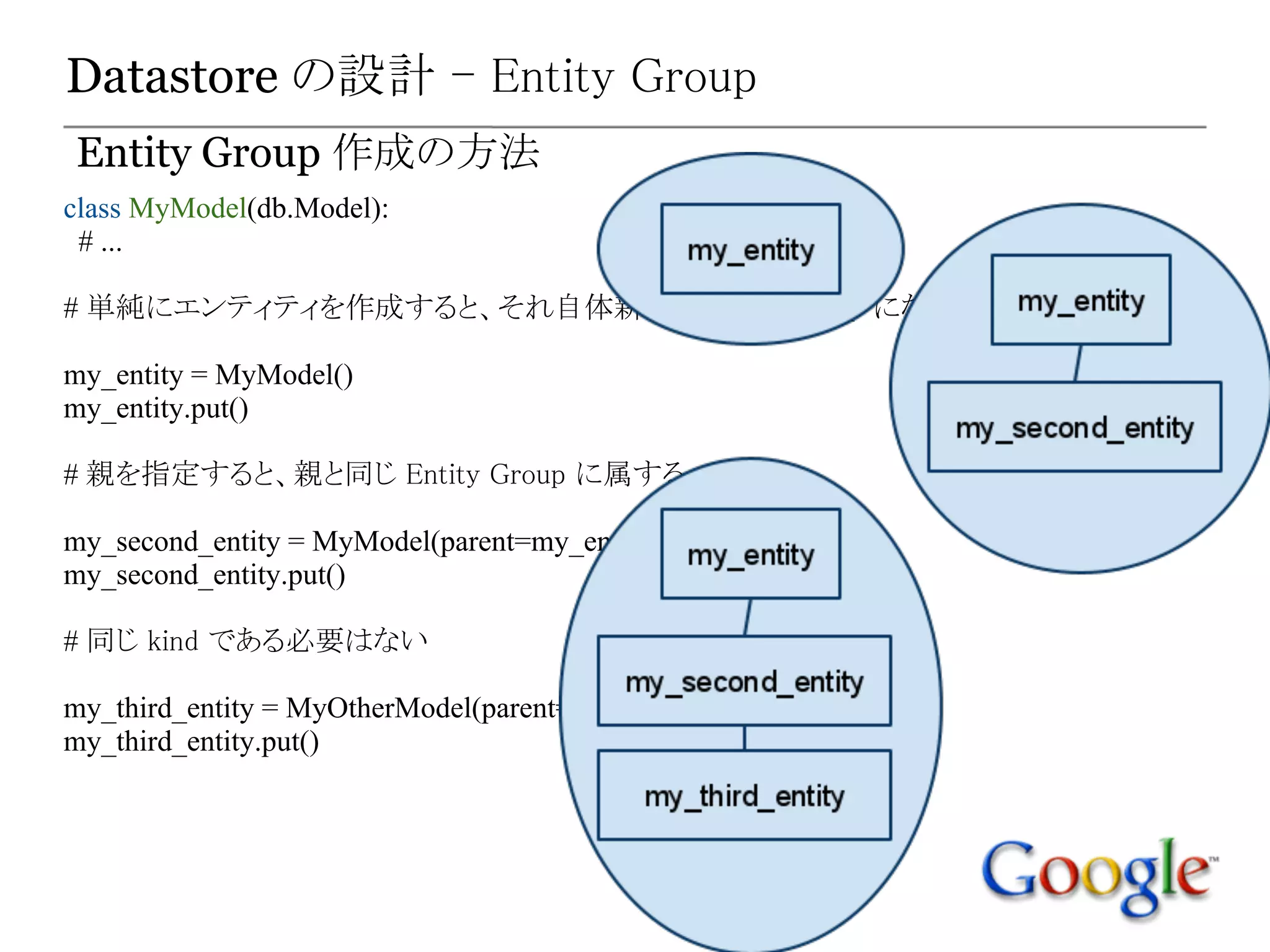
Datastore の設計 -Entity Group
Entity Group 作成の方法
class MyModel(db.Model):
# ...
# 単純にエンティティを作成すると、それ自体新しい Entity Group になる
my_entity = MyModel()
my_entity.put()
# 親を指定すると、親と同じ Entity Group に属する
my_second_entity = MyModel(parent=my_entity)
my_second_entity.put()
# 同じ kind である必要はない
my_third_entity = MyOtherModel(parent=my_second_entity)
my_third_entity.put()
19.
Datastore の設計 -Entity Group
Entity Group 作成の方法
class MyModel(db.Model):
# ...
# 単純にエンティティを作成すると、それ自体新しい Entity Group になる
my_entity = MyModel()
my_entity.put()
# 親を指定すると、親と同じ Entity Group に属する
my_second_entity = MyModel(parent=my_entity)
my_second_entity.put()
# 同じ kind である必要はない
my_third_entity = MyOtherModel(parent=my_second_entity)
my_third_entity.put()
20.
Datastore の設計 -Entity Group
親子関係全てに Entity Group を使用するべきではない
例えば BlogEntry と Comment には不適切
基本的にはトランザクションが必要な箇所に使う
検索用インデックスを自前で作る時などにも有効
21.
Datastore の設計 -Entity Group の使用例
検索用インデックス - Before
class Sentence(db.Model):
body = db.TextProperty()
indexes = db.StringListProperty()
query = Sentence.all().filter(
"indexes =", search_word
)
search_result = query.fetch(20)
fetch 時に不必要な indexes のデシリアライズが発生
22.
Datastore の設計 -Entity Group の使用例
検索用インデックス - After
class Sentence(db.Model):
body = db.TextProperty()
class SearchIndex(db.Model):
indexes = db.StringListProperty()
query = SearchIndex.all(keys_only=True).
filter("indexes =", search_word)
search_result = db.get(
[key.parent() for key in query.fetch(20)])
保存時に Entity Group を形成
23.
Datastore の設計
非正規化 を嫌がらない - No join
必要な index のみ作成
最小限の Entity Group
トランザクションが必要な箇所のみ
可能なら速い方を使う
query より keys_only query が速い
query より get が速い
複数の get より batch get が速い
kind の分割が有効なケース
一部のプロパティだけ取得
少しの失敗を受け入れる
リトライ、deadline の指定
24.
Datastore の設計
非正規化 を嫌がらない - No join
必要な index のみ作成
最小限の Entity Group
トランザクションが必要な箇所のみ
可能なら速い方を使う
query より keys_only query が速い
query より get が速い
複数の get より batch get が速い
kind の分割が有効なケース
一部のプロパティだけ取得
少しの失敗を受け入れる
リトライ、deadline の指定
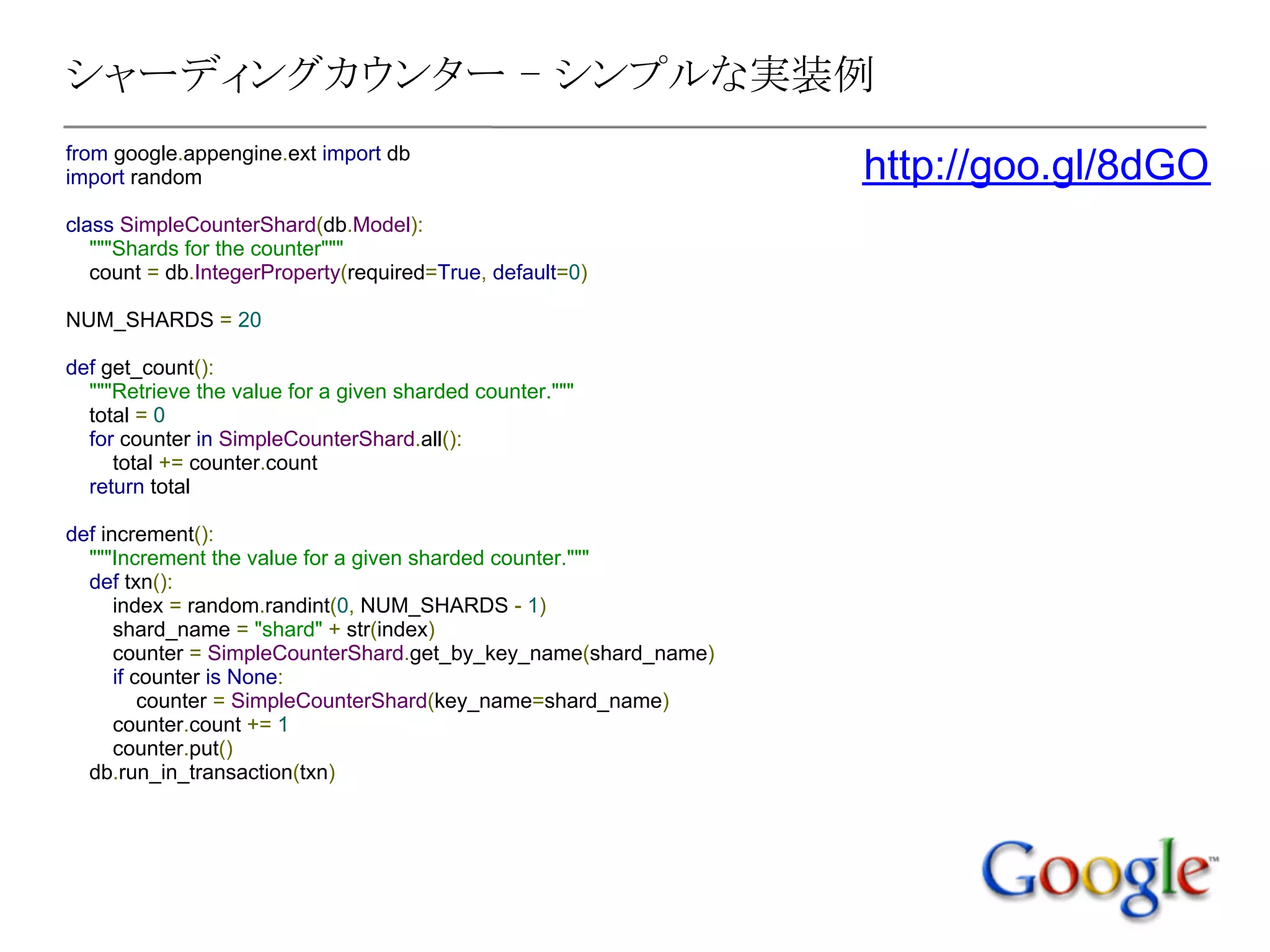
シャーディングカウンター - シンプルな実装例
fromgoogle.appengine.ext import db
import random http://goo.gl/8dGO
class SimpleCounterShard(db.Model):
"""Shards for the counter"""
count = db.IntegerProperty(required=True, default=0)
NUM_SHARDS = 20
def get_count():
"""Retrieve the value for a given sharded counter."""
total = 0
for counter in SimpleCounterShard.all():
total += counter.count
return total
def increment():
"""Increment the value for a given sharded counter."""
def txn():
index = random.randint(0, NUM_SHARDS - 1)
shard_name = "shard" + str(index)
counter = SimpleCounterShard.get_by_key_name(shard_name)
if counter is None:
counter = SimpleCounterShard(key_name=shard_name)
counter.count += 1
counter.put()
db.run_in_transaction(txn)













![Datastore の設計 - 非正規化
Before
from google.appengine.ext import db
class User(db.Model):
name = db.StringProperty()
groups = db.ListProperty(db.Key)
class Group(db.Model):
name = db.StringProperty()
user = User.get(user_key)
group_names = [group.name for group in db.get(user.groups)]](https://image.slidesharecdn.com/developersummit2011appenginetoinfinity1-110218023421-phpapp01/75/18-C-4-Google-App-Engine-13-2048.jpg)







![Datastore の設計 - Entity Group の使用例
検索用インデックス - After
class Sentence(db.Model):
body = db.TextProperty()
class SearchIndex(db.Model):
indexes = db.StringListProperty()
query = SearchIndex.all(keys_only=True).
filter("indexes =", search_word)
search_result = db.get(
[key.parent() for key in query.fetch(20)])
保存時に Entity Group を形成](https://image.slidesharecdn.com/developersummit2011appenginetoinfinity1-110218023421-phpapp01/75/18-C-4-Google-App-Engine-22-2048.jpg)


















![[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法](https://cdn.slidesharecdn.com/ss_thumbnails/di08-170605024559-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[HQ Nacional] Street Fighter II Ano I - Número 1 - parte 2](https://cdn.slidesharecdn.com/ss_thumbnails/streetfighterii-anoi-nmero1-parte2-110702183634-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































