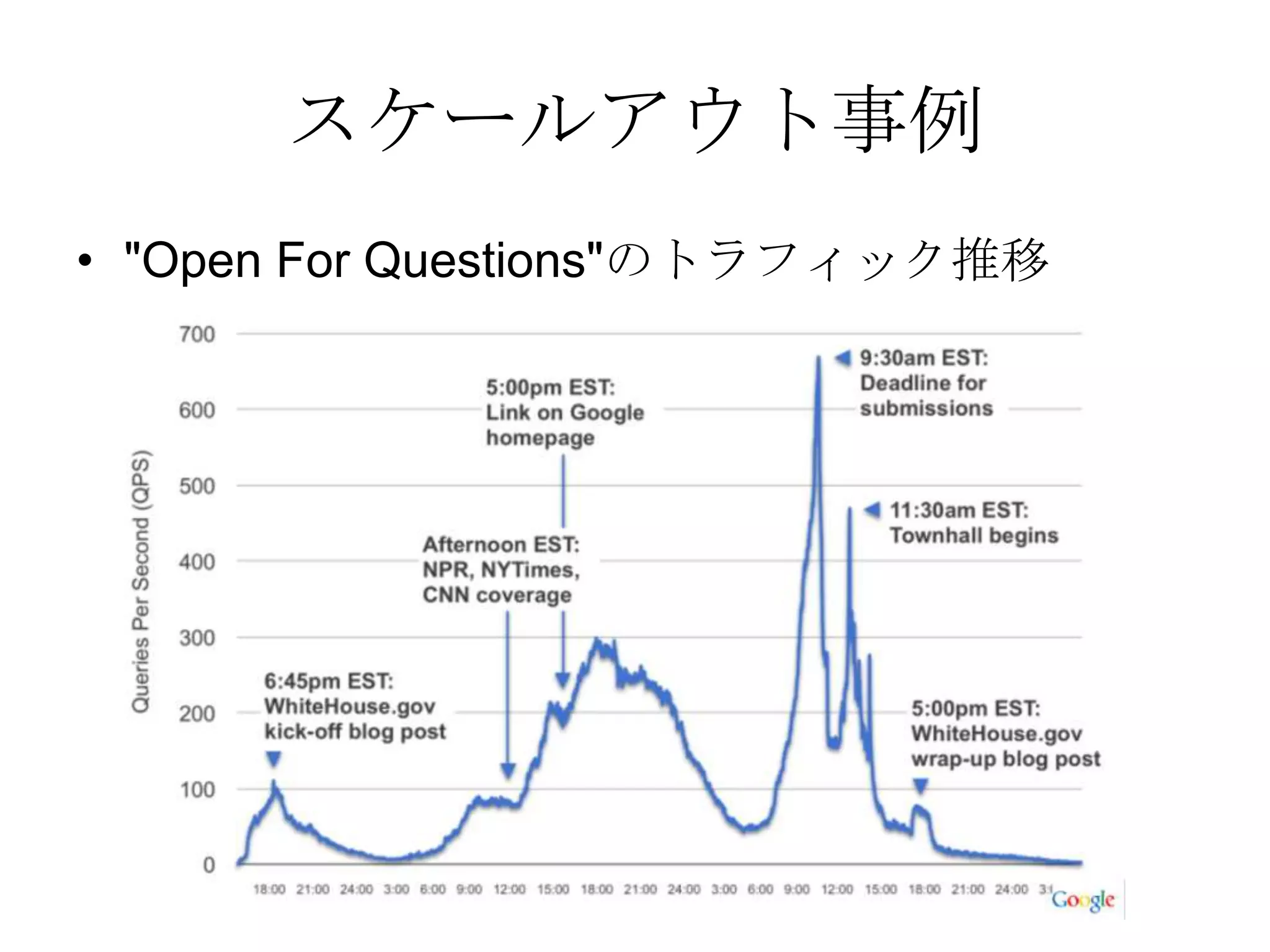
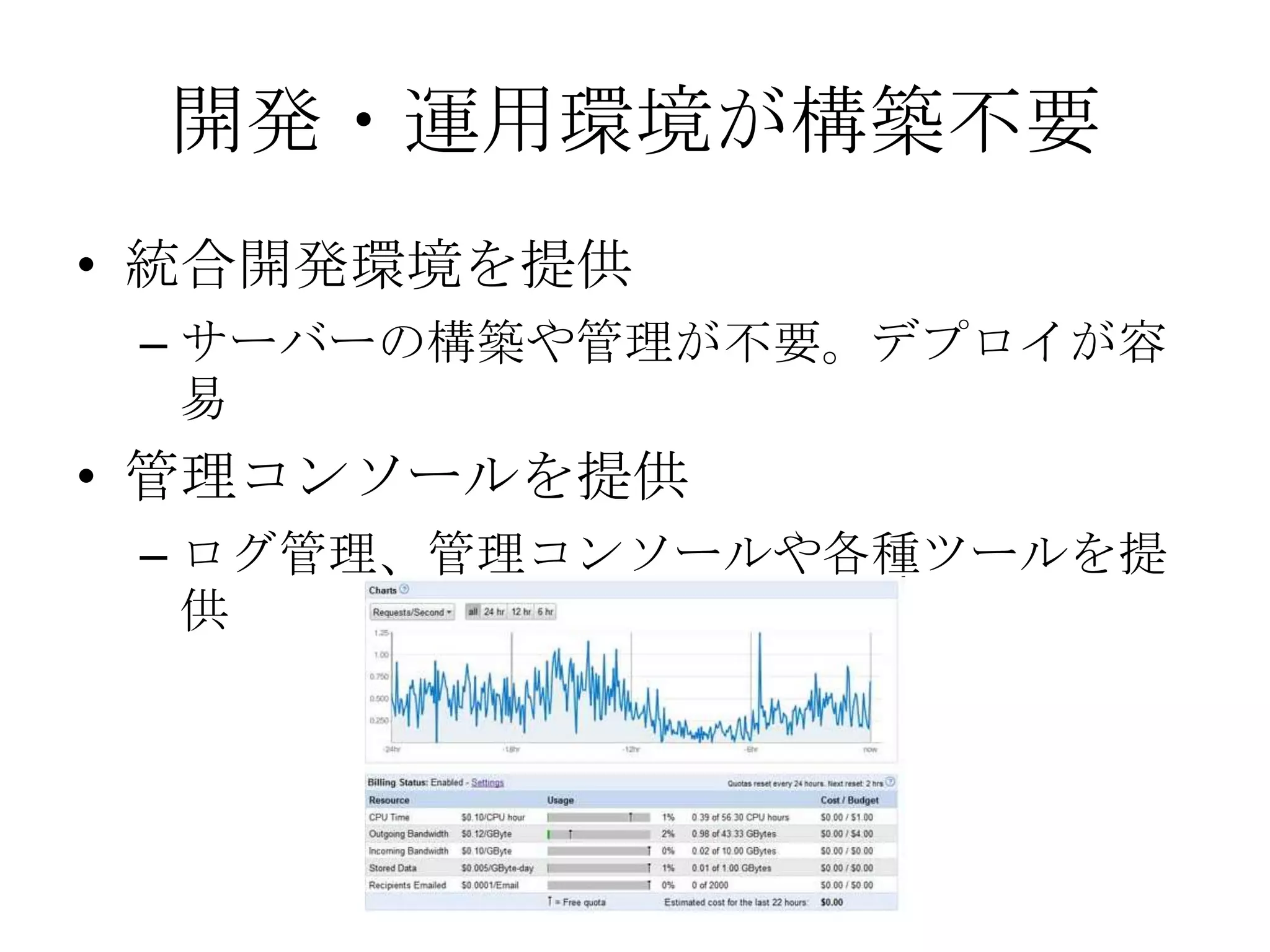
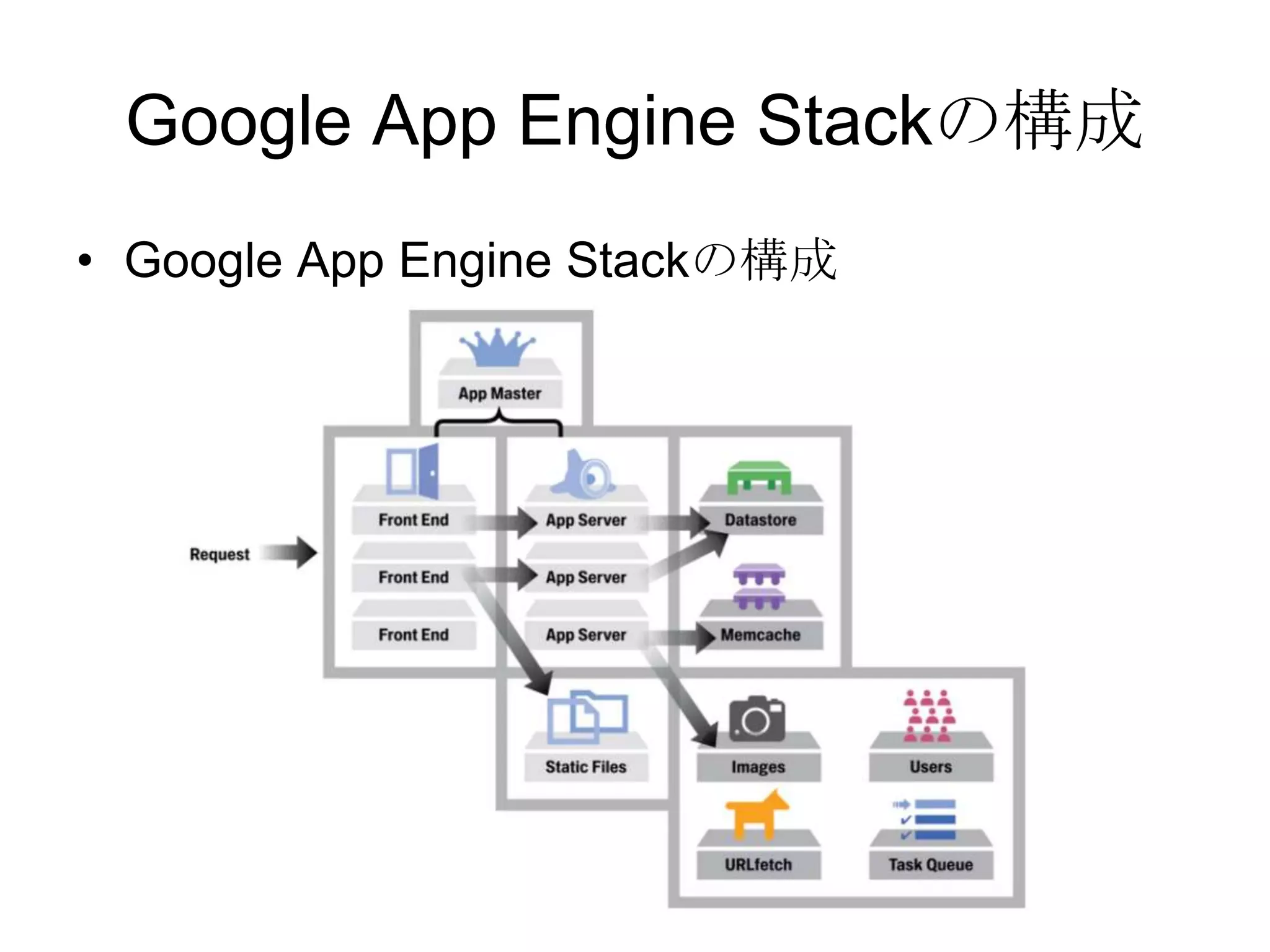
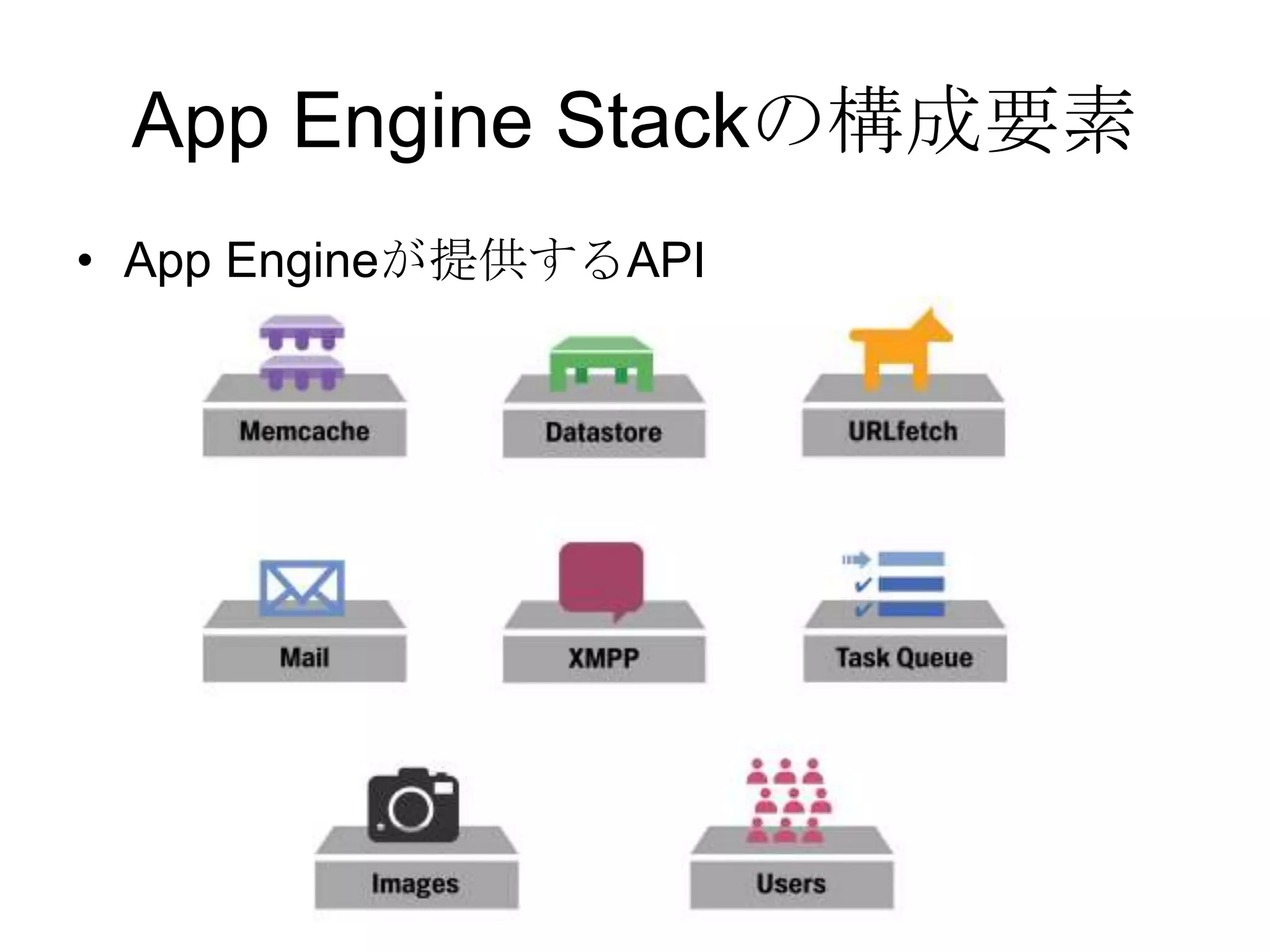
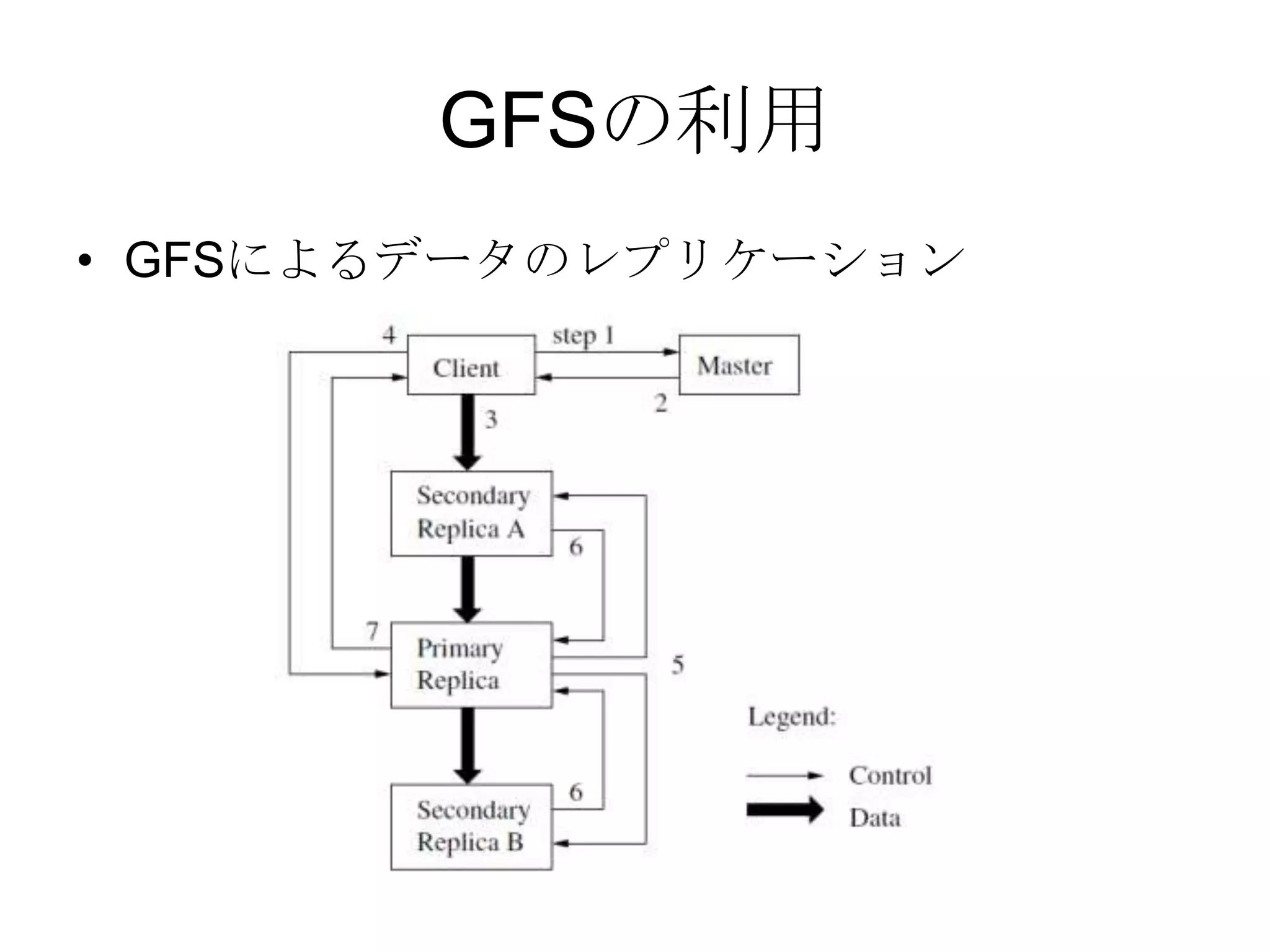
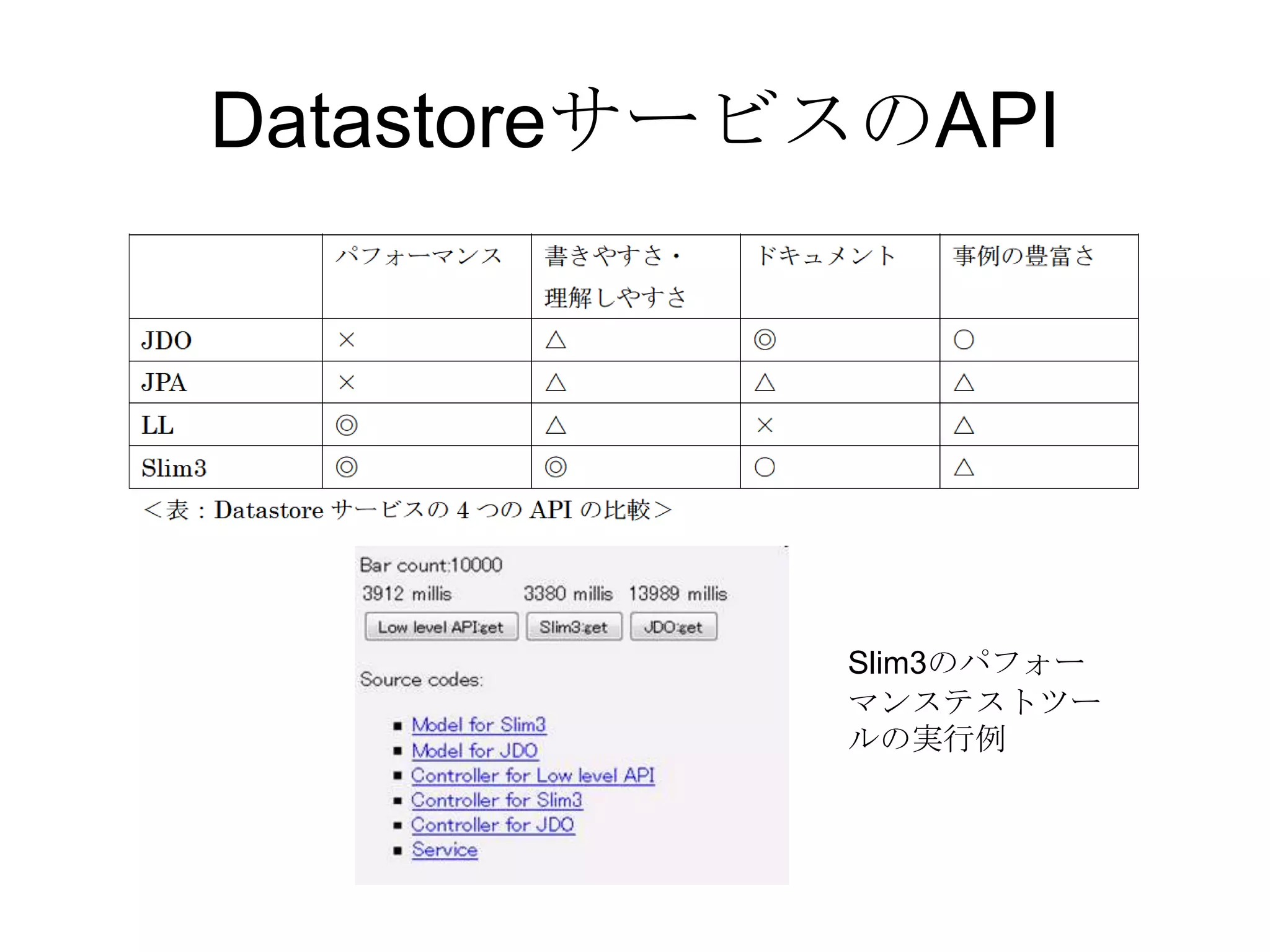
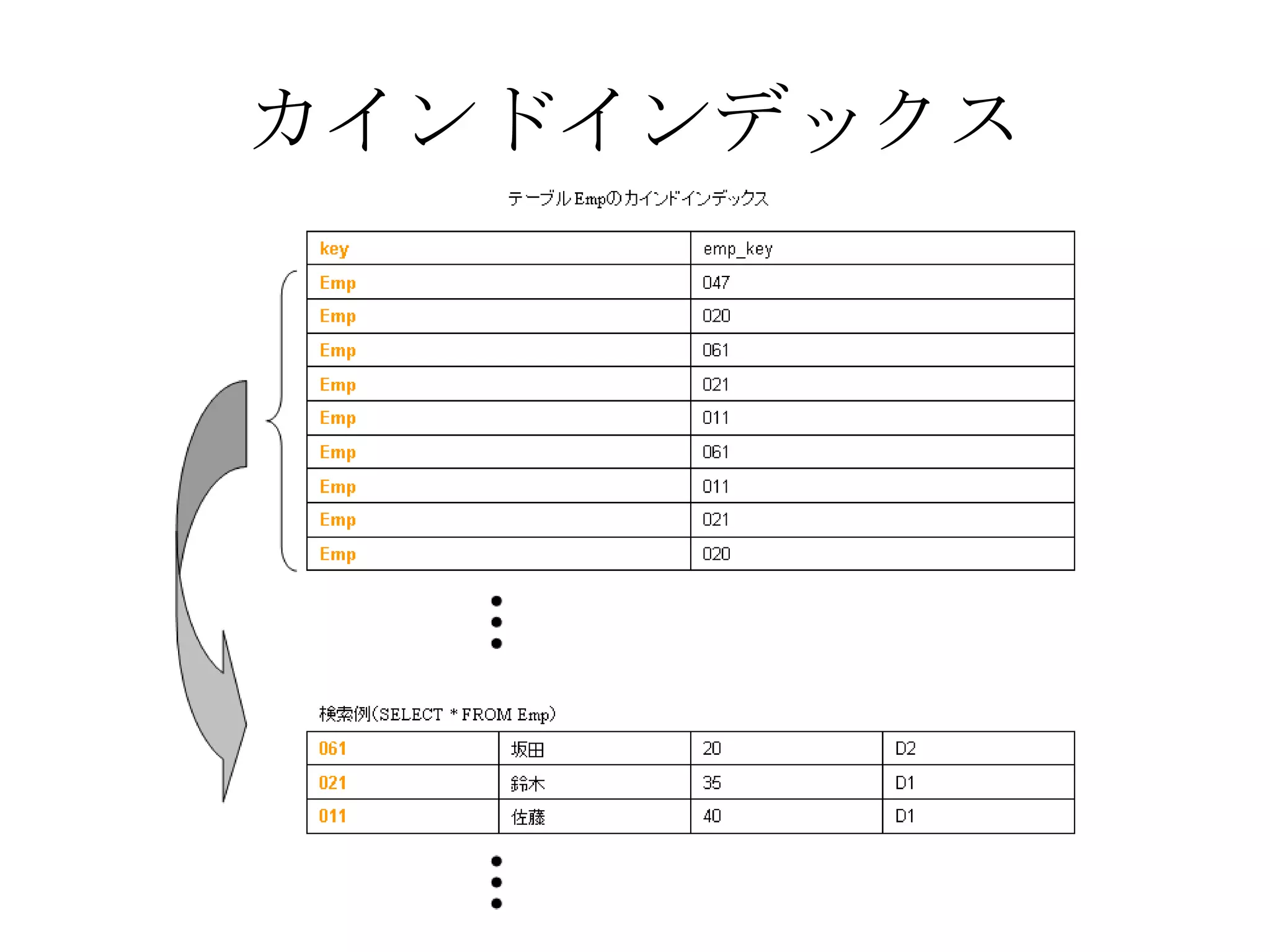
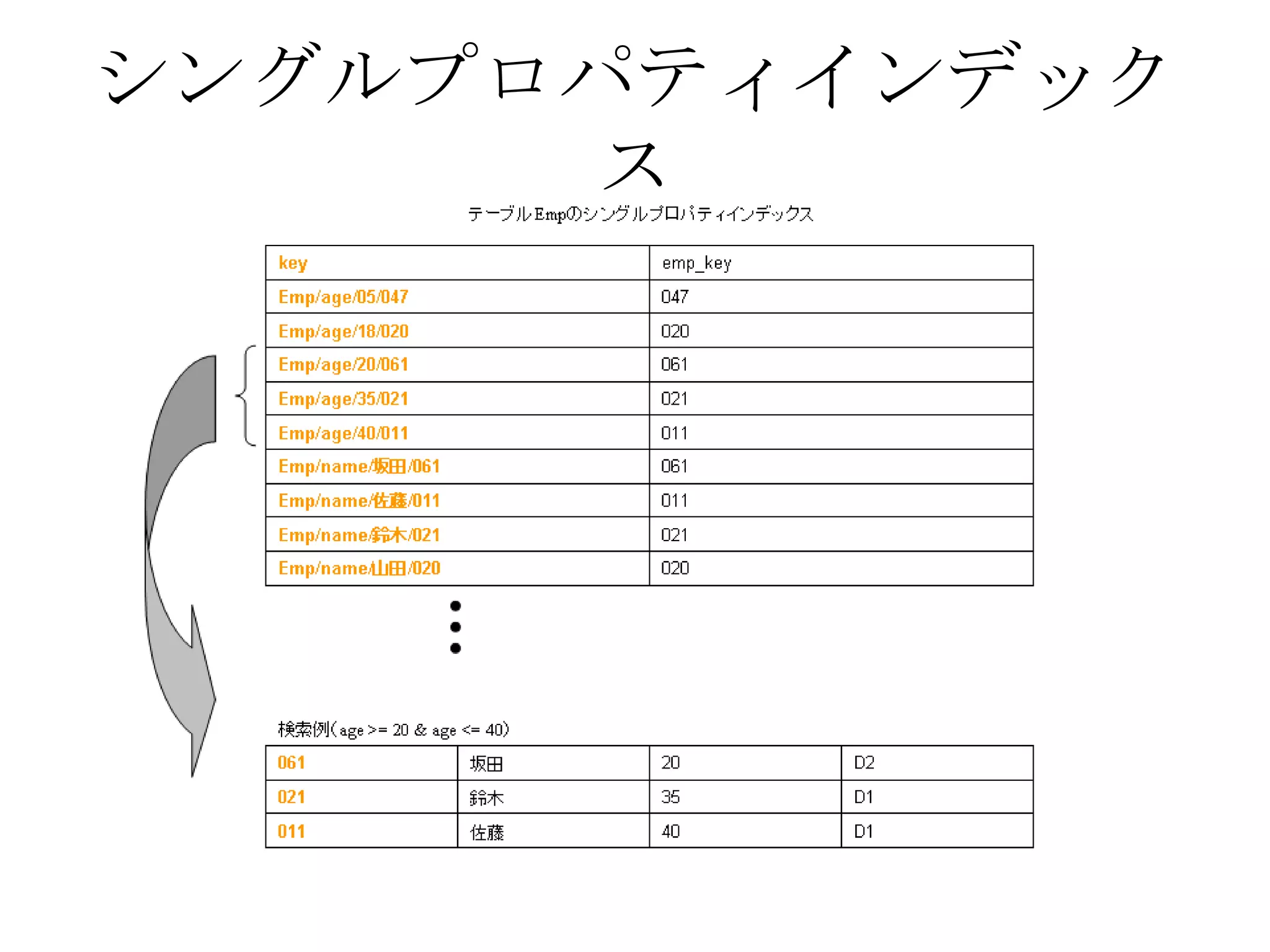
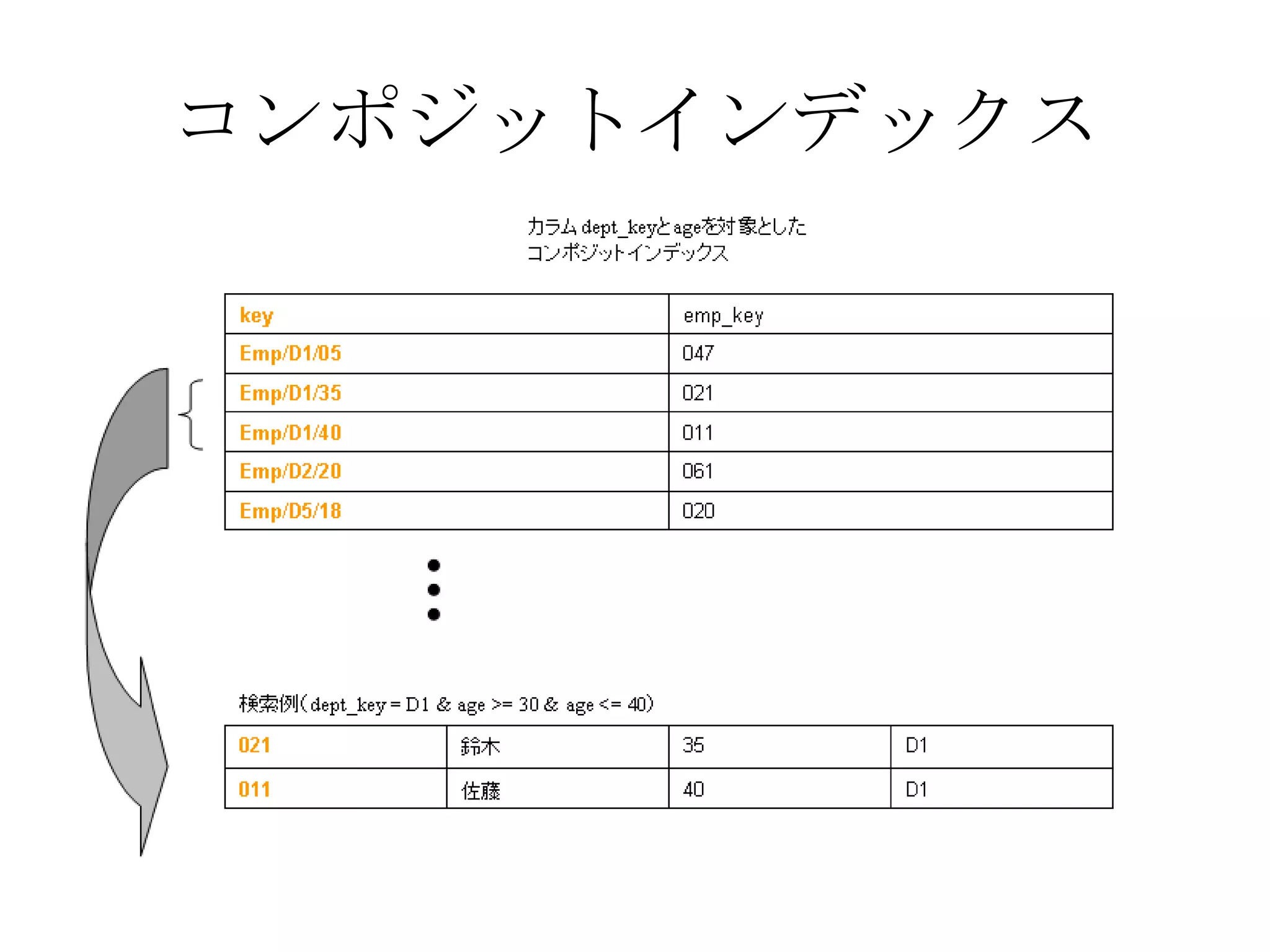
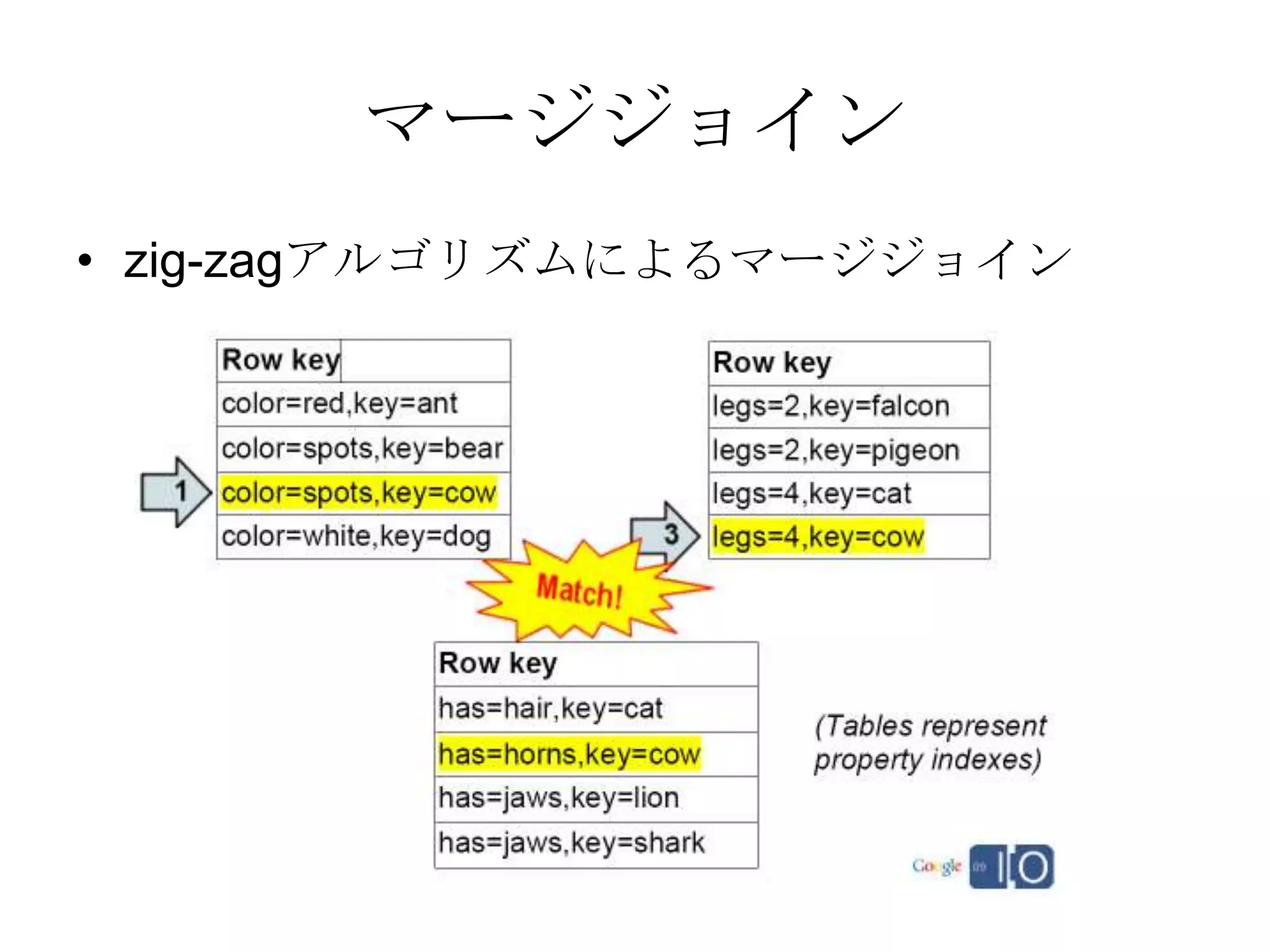
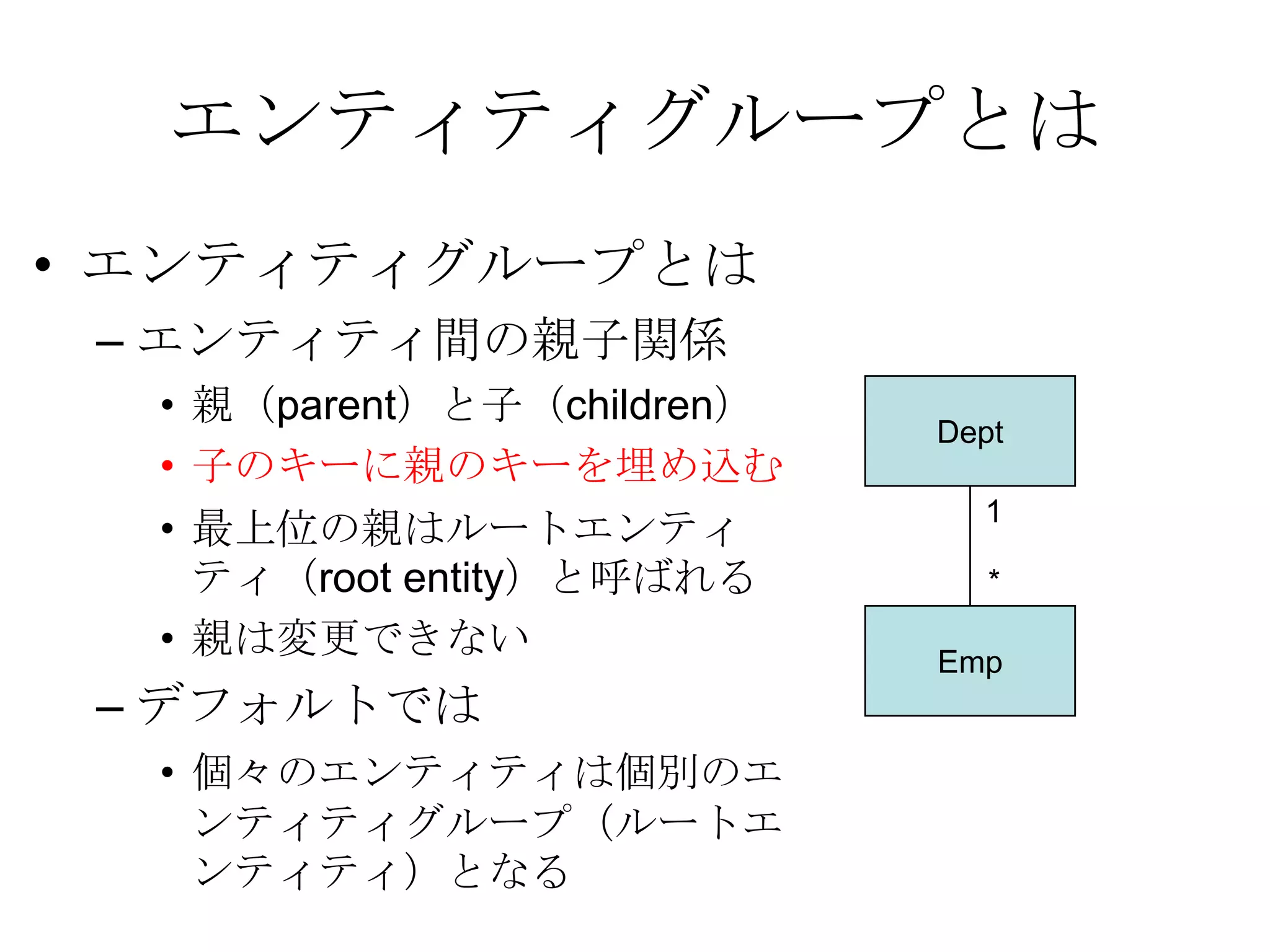
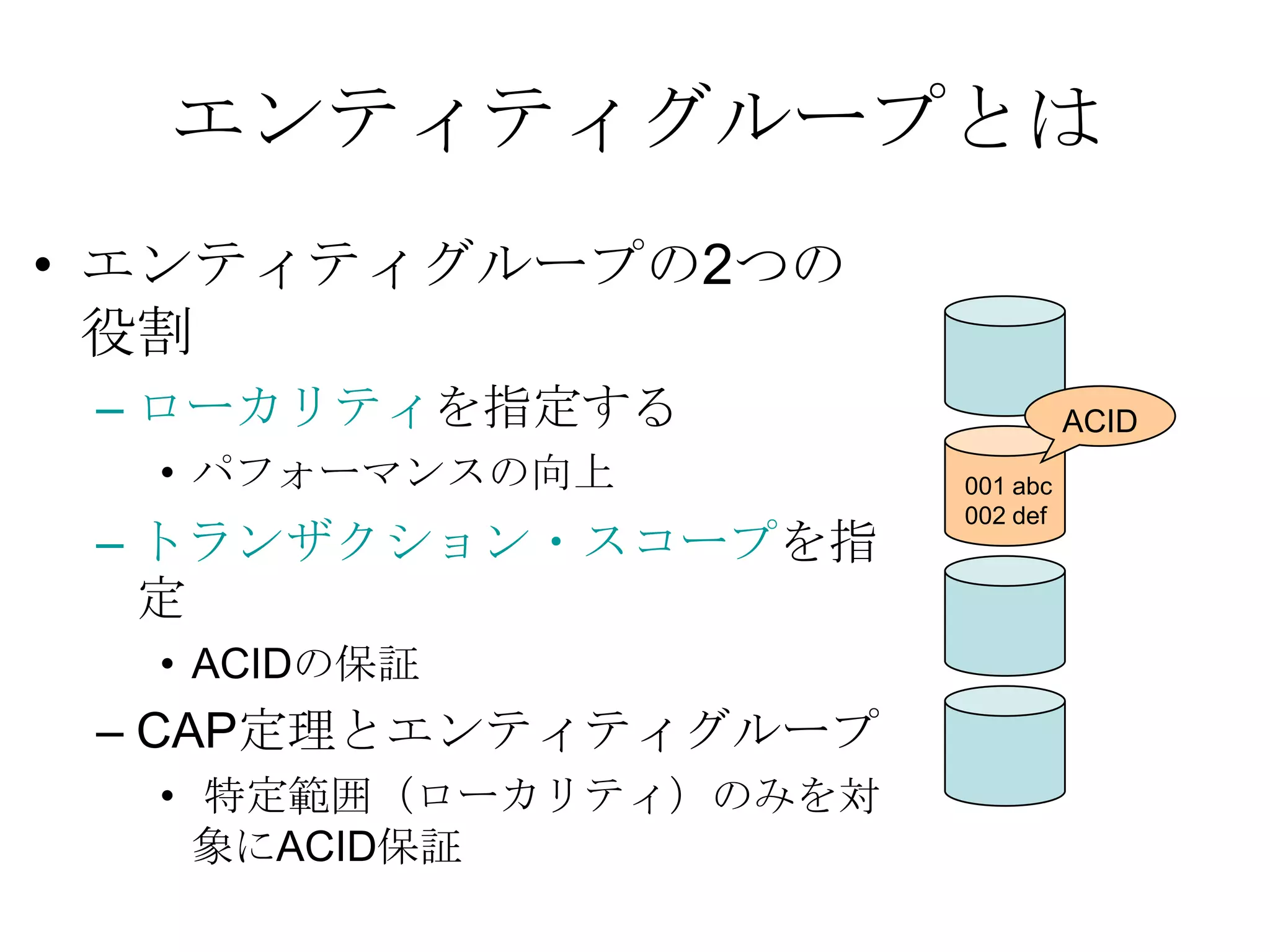
Recommended
PDF
メルカリアッテの実務で使えた、GAE/Goの開発を効率的にする方法
PPTX
PDF
【18-C-4】Google App Engine - 無限の彼方へ
PPT
PDF
Report of Google I/O 2013 Google Cloud Platform
PPT
PDF
PPT
PDF
デブサミ2011 LT大会【17-E-7】appengine ja night
PDF
Google Compute EngineとGAE Pipeline API
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
PDF
Presto As A Service - Treasure DataでのPresto運用事例
PPTX
ODP
PDF
PDF
Google App Engine Java 入門
PPT
KEY
Googleクラウドサービスを利用したシステム構築
PDF
Google Compute EngineとPipe API
PDF
PPT
PDF
Google App Engine for PHPとそのローカル開発環境について
PDF
A development journal of koremirudb1 cloud&nosql (1)
PDF
PPT
PDF
ODP
Google App Engineとその影響(補足)
PPTX
PDF
PPT
More Related Content
PDF
メルカリアッテの実務で使えた、GAE/Goの開発を効率的にする方法
PPTX
PDF
【18-C-4】Google App Engine - 無限の彼方へ
PPT
PDF
Report of Google I/O 2013 Google Cloud Platform
PPT
PDF
PPT
Similar to CBA Google App Engine 20101208
PDF
デブサミ2011 LT大会【17-E-7】appengine ja night
PDF
Google Compute EngineとGAE Pipeline API
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
PDF
Presto As A Service - Treasure DataでのPresto運用事例
PPTX
ODP
PDF
PDF
Google App Engine Java 入門
PPT
KEY
Googleクラウドサービスを利用したシステム構築
PDF
Google Compute EngineとPipe API
PDF
PPT
PDF
Google App Engine for PHPとそのローカル開発環境について
PDF
A development journal of koremirudb1 cloud&nosql (1)
PDF
PPT
PDF
ODP
Google App Engineとその影響(補足)
PPTX
More from Kazunori Sato
PDF
PPT
PDF
Moving computation to the data (1)
PPT
PPT
GDD2010 appengine ja night + Slim3
PPT
Doc management by Confluence+Jira
PPT
Arista @ HPC on Wall Street 2012
PPT