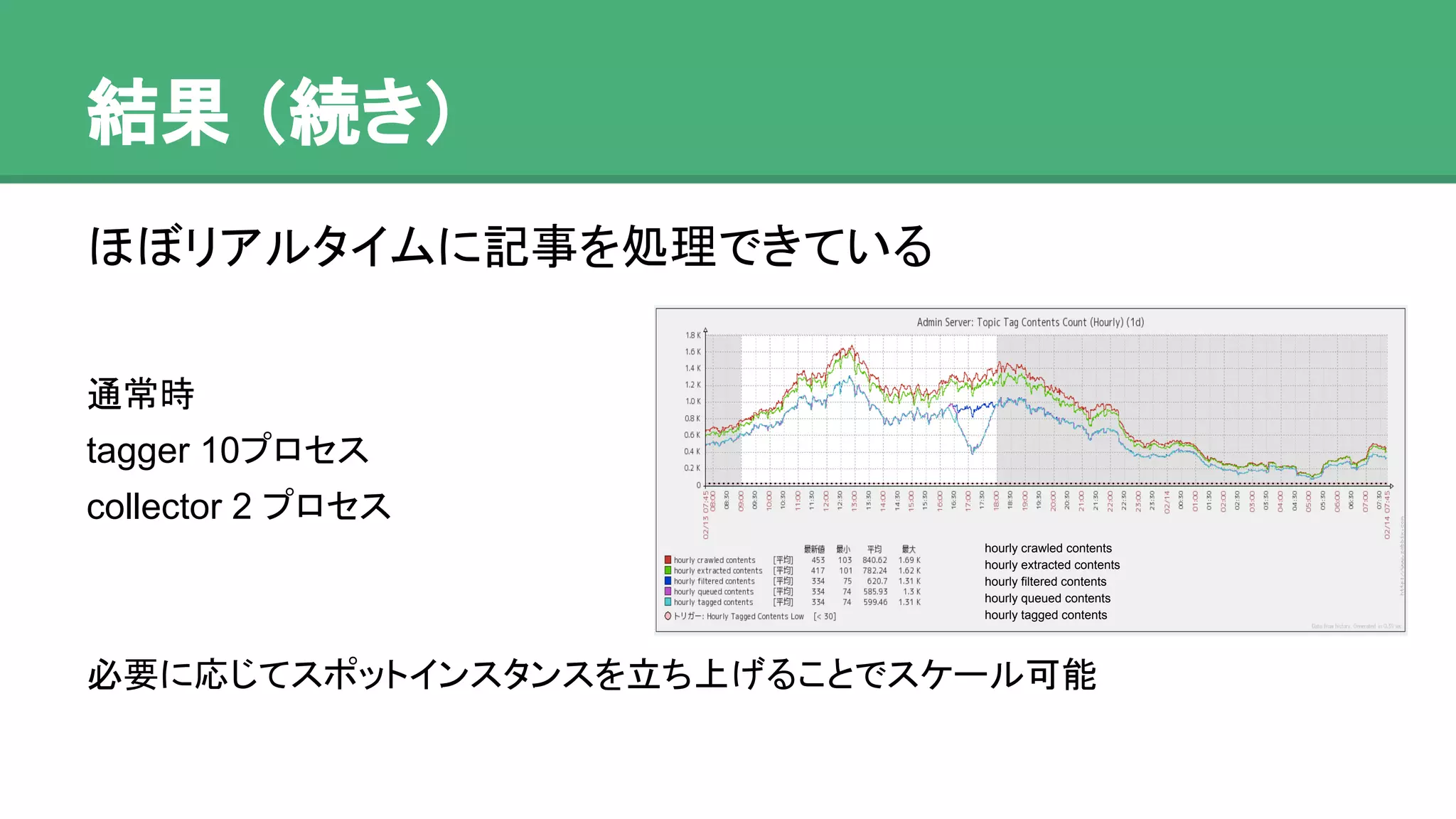
苦労したところ
● RabbitMQ ワーカーが安定しない
oライブラリ (pika) とマルチスレッドの相性が悪い
o heartbeat が途切れるとサーバが勝手に接続を切る
o 最終的には詰まっていることを検知して自動再起動
するようにした(運用でカバー)
28.
なぜ Python か
●高速化したいなら C++ や Go の方が Python
より 100 倍高速では?
● Python を使った理由
o 構文解析のような複雑な処理を、なるべくバグを出
さずにかつ素早く書けること
o コードオブジェクトのシリアライズができること
o pypy は使っているライブラリが対応していなかった













![ast
● Python の抽象構文木を扱うためのモジュール
● compile() 関数を使って Python コードに変換できる
>>> print ast.dump(ast.parse("1 + 2 * x"))
Module(body=[
Expr(value=BinOp(op=Add(),
left=Num(n=1),
right=BinOp(op=Mult(),
left=Num(n=2),
right=Name(id='x', ctx=Load()))))
])](https://image.slidesharecdn.com/python-150327030131-conversion-gate01/75/Python-20-2048.jpg)
![クエリから Python コードへの変換
#weight(3.0 #syn(カメリオ kamelio) 1.0 白ヤギ)
#weight
3.0 1.0 白ヤギ
カメリオ
def func(log_p, p):
return 0.75 * log(p("カメリオ", "kamelio")) + 0.25 * log_p["白ヤギ"]
+
* *
0.75 0.25log() []
p()
カメリ
オ
kamelio
白ヤギlog_p
クエリのパース
ast の生成
コンパイル
kamelio
#syn](https://image.slidesharecdn.com/python-150327030131-conversion-gate01/75/Python-22-2048.jpg)