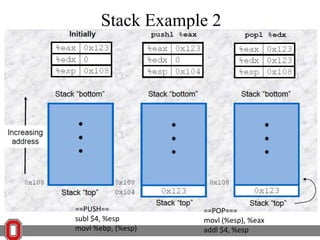
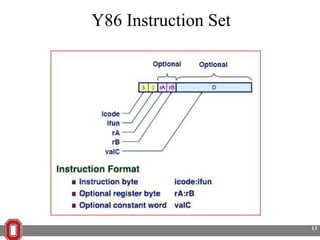
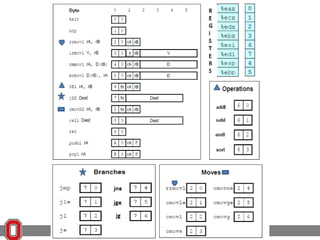
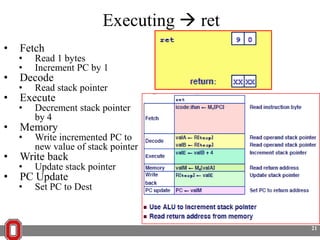
The Y86 architecture has 8 32-bit registers, 3 condition codes (ZF, SF, OF), a program counter (PC), and up to 4GB of memory. It supports normal, register, and displacement addressing modes. Instructions include arithmetic, logical operations, jumps, calls, returns, and memory load/store. The execution cycle fetches, decodes, executes, and updates the PC for each instruction. Condition codes track the results of arithmetic operations for conditional jumps.





![Simple Addressing Modes
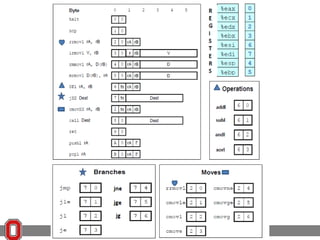
• Normal = (R) = Mem[Reg[R]]
• Register Reg specifies memory address
• denoted by a register in ( )
• Example
value
0x120
0x11
0x121
0x22
0x122
0x33
0x123
ecx = 0x00000120
addr
0x44
movl (%ecx),%eax
move the value that is at the address in ecx into
eax
Moves 0x11223344 into eax
5](https://image.slidesharecdn.com/17-131106121332-phpapp02/85/17-5-320.jpg)
![Simple Addressing Modes
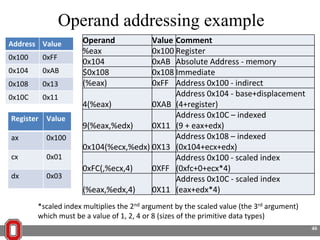
• Displacement = D(R) = Mem[Reg[R]+D]
• Register R specifies start of memory address
• Constant displacement D specifies offset
• In bytes
loads 0x33445566 into edx
value
0x120
0x11
0x121
0x22
0x122
0x33
0x123
0x44
0x124
• Denoted by displacement(register)
ebp = 0x120
movl 2(%ebp),%edx
move the value at ebp (0x120) + 2 into edx
addr
0x55
0x125
0x66
6](https://image.slidesharecdn.com/17-131106121332-phpapp02/85/17-6-320.jpg)






































![x86 Instructions
<reg32>
Any 32-bit register (EAX, EBX, ECX,
EDX, ESI, EDI, ESP, or EBP)
<reg16> Any 16-bit register (AX, BX, CX, or
DX)
<reg8> Any 8-bit register (AH, BH, CH, DH,
AL, BL, CL, or DL)
<reg> Any register
<mem> A memory address (e.g., [eax], [var +
4], or dword ptr [eax+ebx])
<con32> Any 32-bit constant
<con16> Any 16-bit constant
<con8> Any 8-bit constant
<con> Any 8-, 16-, or 32-bit constant](https://image.slidesharecdn.com/17-131106121332-phpapp02/85/17-51-320.jpg)














![[FT-11][suhorng] “Poor Man's” Undergraduate Compilers](https://cdn.slidesharecdn.com/ss_thumbnails/poormansundergraduatecompilers-140421081114-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2012 CodeEngn Conference 06] pwn3r - Secuinside 2012 CTF 예선 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/20126thcodeengnpwn3rsecuinside2012ctf-130525233500-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







![Ilfak Guilfanov - Decompiler internals: Microcode [rooted2018]](https://cdn.slidesharecdn.com/ss_thumbnails/ilfak-keynote-180312223906-thumbnail.jpg?width=640&height=640&fit=bounds)












![reductio [ad absurdum]](https://cdn.slidesharecdn.com/ss_thumbnails/taualywhssudecboubib-signature-40f4714a7511dbefb3f8b81978ee26a52b8bc17a56b46da771a1d673a5b4d7df-poli-170804175449-thumbnail.jpg?width=640&height=640&fit=bounds)




























