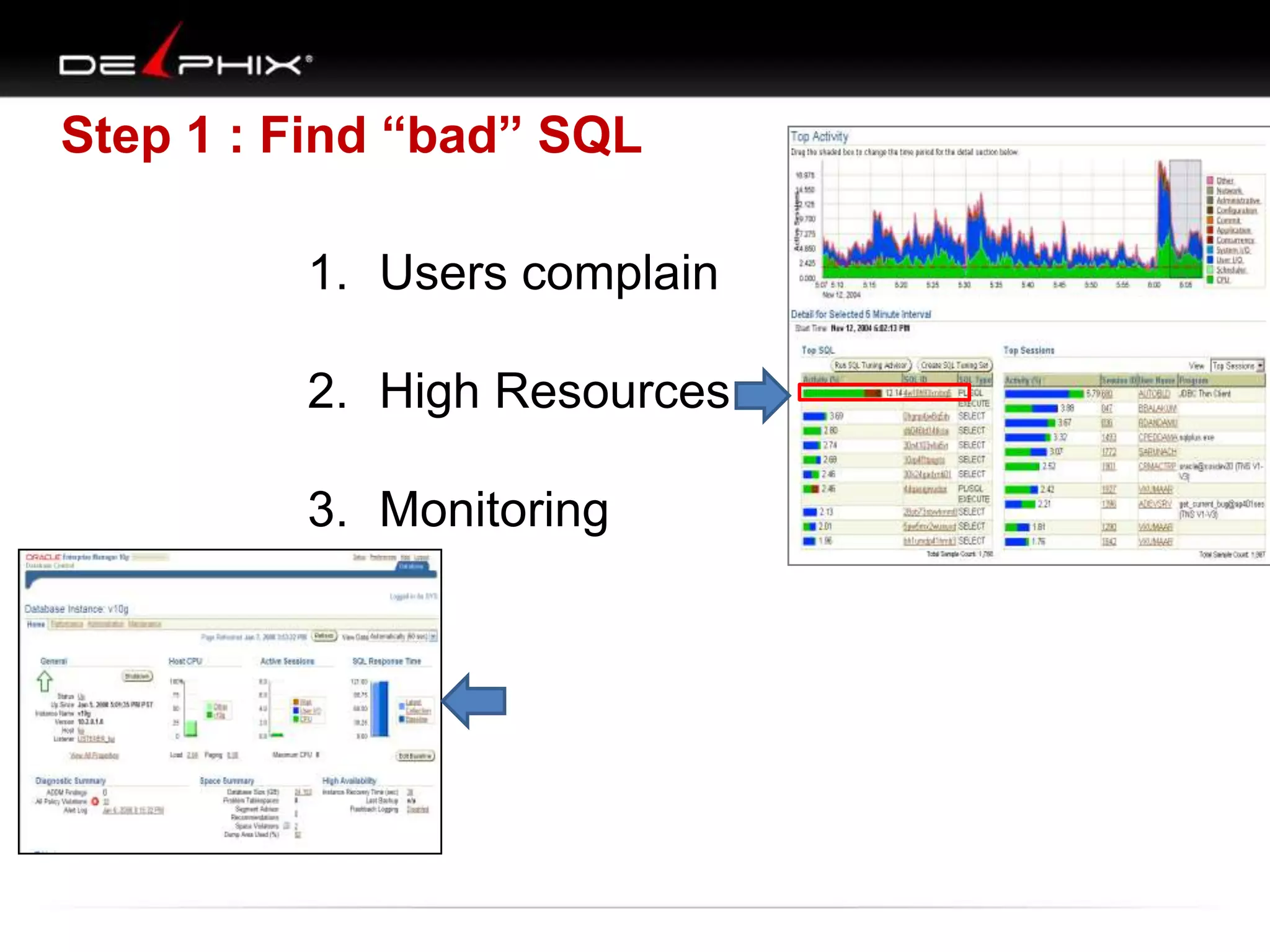
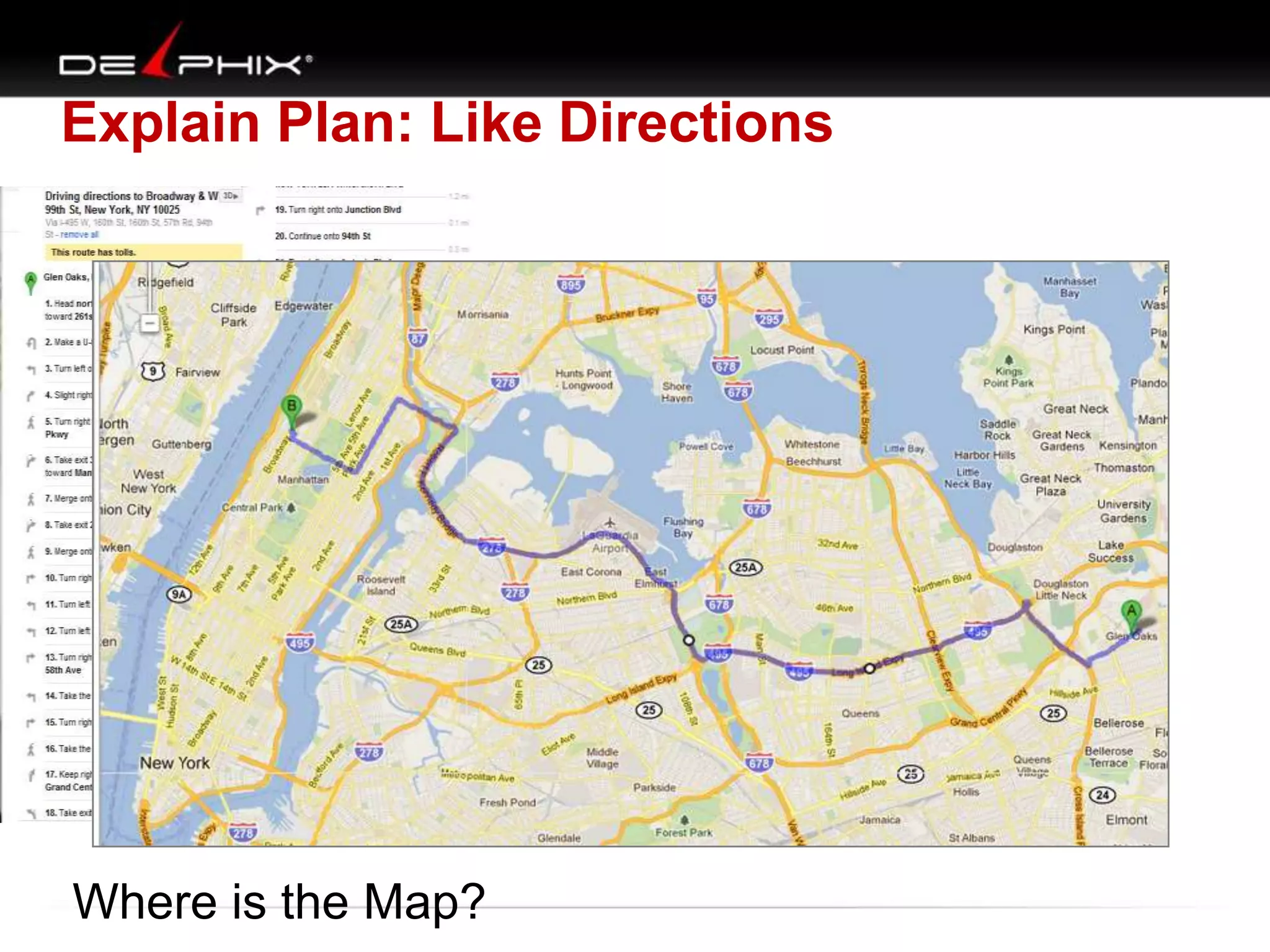
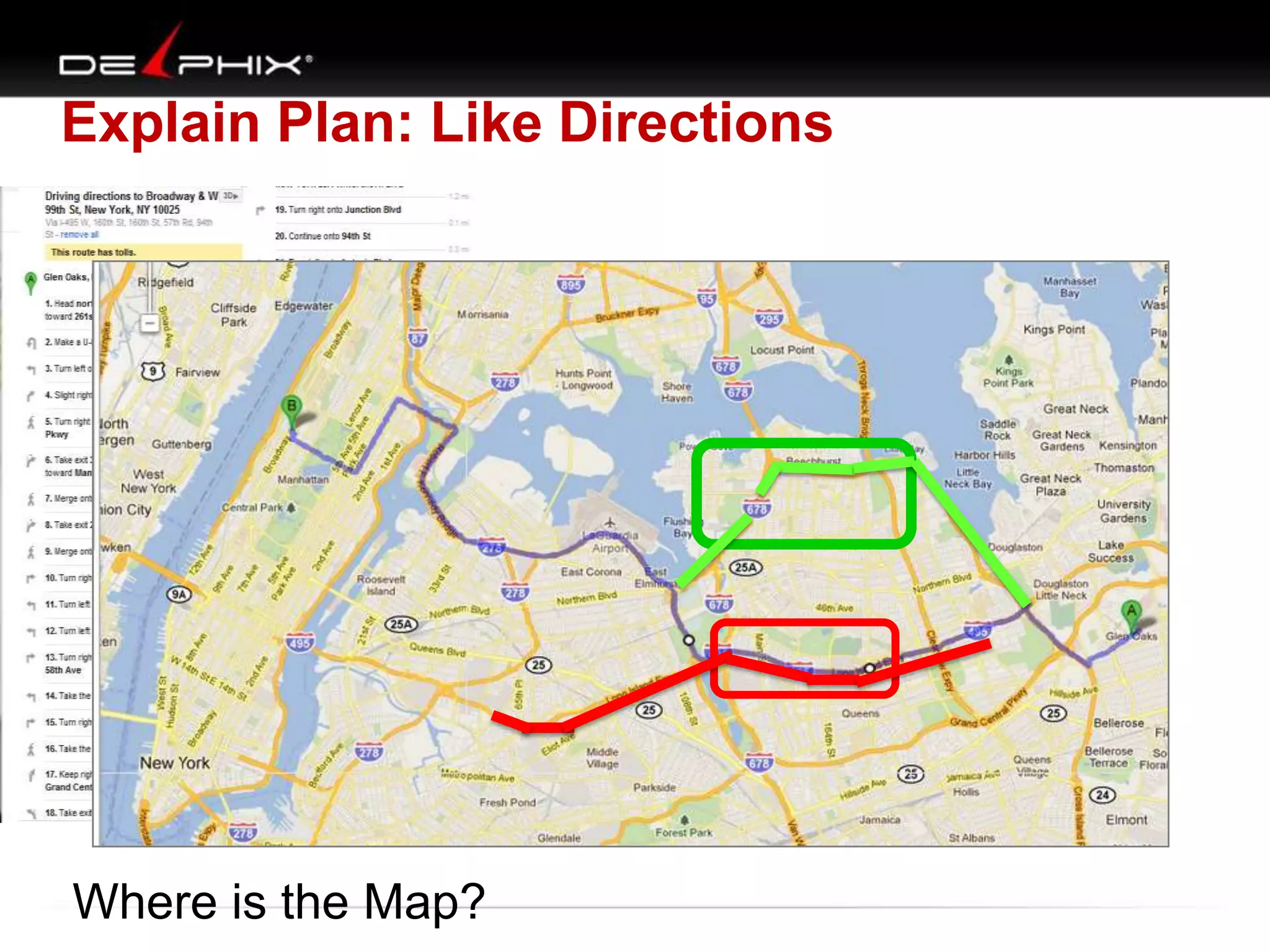
Downloaded 79 times



















![10053
B
C
$: 4
#: 1
$: 5428
#: 59999
A
$: 92
#: 999
B A C
B C A
C A B
C B A
A C B
A B C
Table: A Alias: A
Best:: AccessPath: TableScan
Cost: 92.18 Degree: 1
Resp: 92.18 Card: 999.00
Best:: AccessPath: IndexRange
Index: B_V2
Cost: 4.00 Degree: 1
Resp: 4.00 Card: 1.00
Best:: AccessPath: IndexFFS
Index: C_PK_CON
Cost: 35.57 Degree: 1
Resp: 35.57 Card: 59999.00
Join order[1]: B[B]#0 A[A]#1 C[C]#2
***************
Now joining: A[A]#1
***************
Best:: JoinMethod: NestedLoop
Cost: 6.00 Degree: 1 Resp: 6.00 Card: 1.00 Bytes: 16
***************
Now joining: C[C]#2
***************
Best:: JoinMethod: NestedLoop
Cost: 6.00 Degree: 1 Resp: 6.00 Card: 1.00 Bytes: 21
***********************
Best so far: Table#: 0 cost: 4.0020 card: 1.0000 bytes: 12
Table#: 1 cost: 6.0031 card: 1.0000 bytes: 16
Table#: 2 cost: 6.0032 card: 1.0000 bytes: 21
alter session set events='10053 trace name context forever';](https://image.slidesharecdn.com/12bsqltuningvst-130622132835-phpapp01/75/SQL-Tuning-and-VST-66-2048.jpg)
![No Unique Constraint
A
$: 75
#: 999
B A C
NL: $: 10
#: 1
B A
C
$: 6$: 4
#: 1
$: 8
NL:$: 18
#: 1
B C A
NL: $: 10
#: 1
B C
A
$: 6.01$: 4
#: 1
$: 8
C A B
C B A A C B A B C
A
$: 75
#: 999
C
$: 5428
#: 59999
C
$: 5428
#: 59999
A
B C B
Join order[6]: C[C]#2 A[A]#1 B[B]#0
Join order aborted: cost > best plan cost
$
HJ: $: 10
#: 1](https://image.slidesharecdn.com/12bsqltuningvst-130622132835-phpapp01/75/SQL-Tuning-and-VST-67-2048.jpg)
![Unique Constraint
A
$: 75
#: 999
B A C
NL: $: 10
#: 1
B A
C
$: 6$: 4
#: 1
$: 8
NL:$: 18
#: 1
B C A
NL: $: 10
#: 1
B C
A
$: 5$: 4
#: 1
$: 7
C A B
C B A A C B A B C
A
$: 75
#: 999
C
$: 5428
#: 59999
C
$: 5428
#: 59999
A
B C B
Join order[6]: C[C]#2 A[A]#1 B[B]#0
Join order aborted: cost > best plan cost
$
HJ: $: 10
#: 1
NL:$: 16
#: 1](https://image.slidesharecdn.com/12bsqltuningvst-130622132835-phpapp01/75/SQL-Tuning-and-VST-68-2048.jpg)
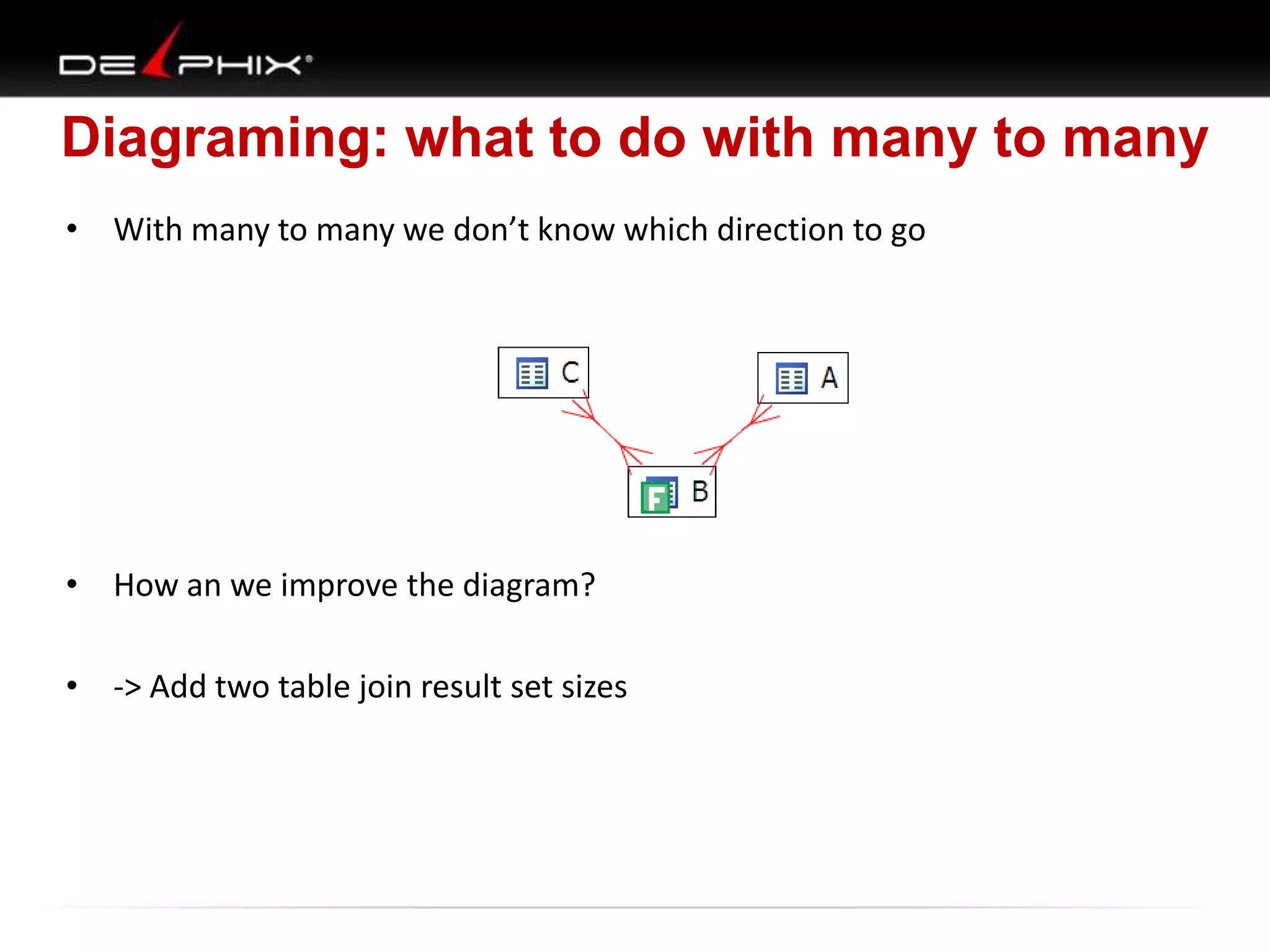
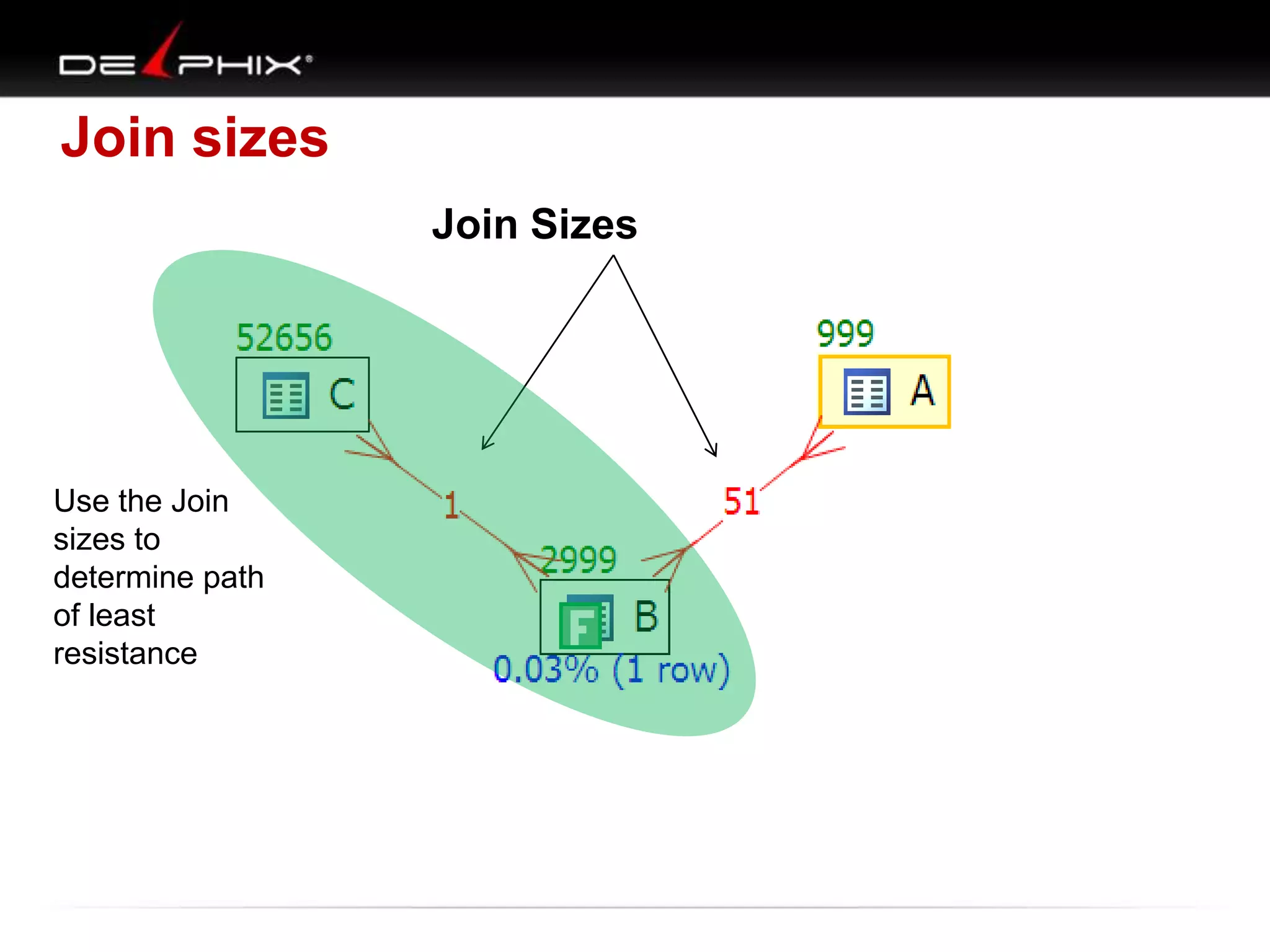

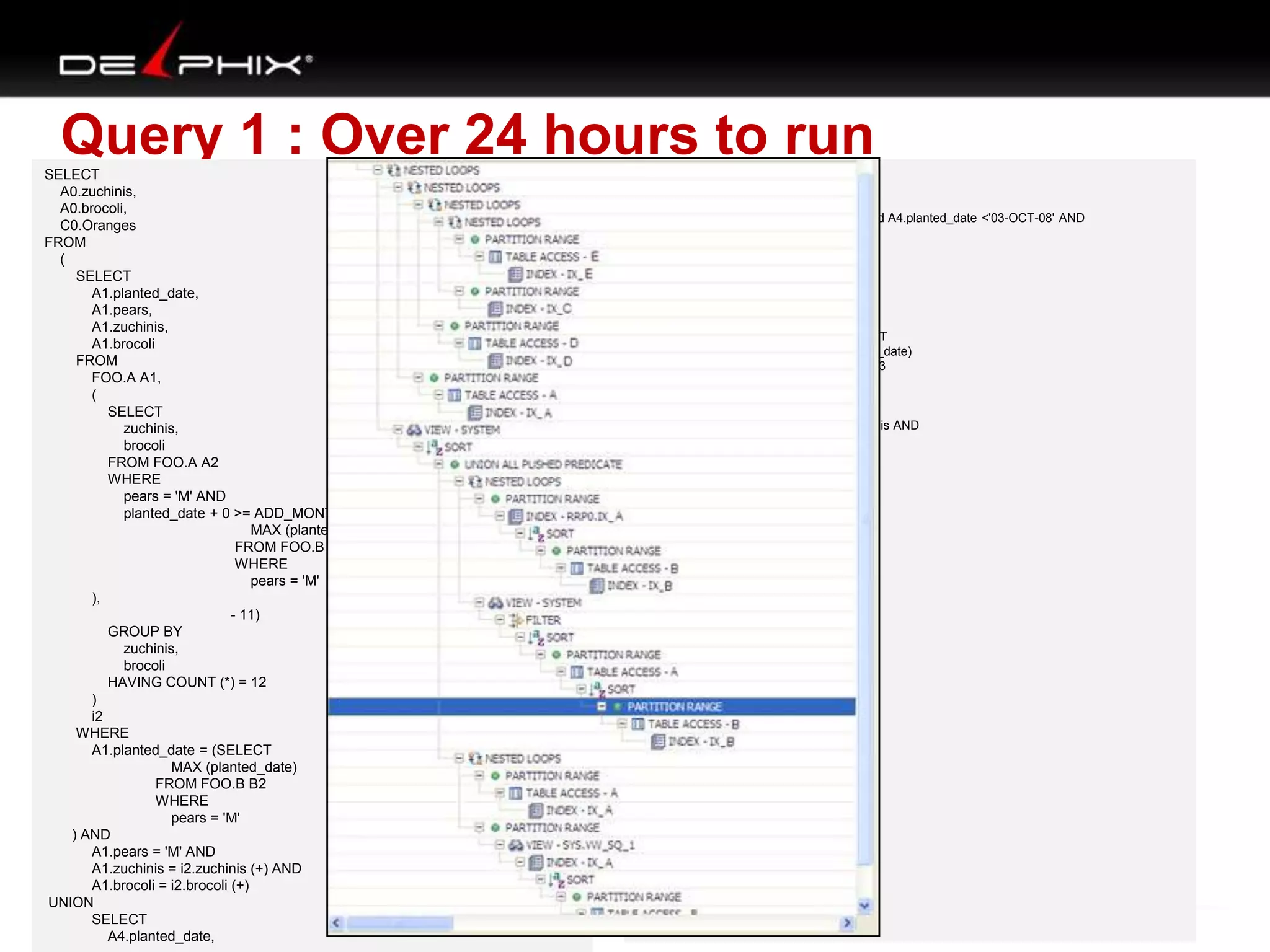
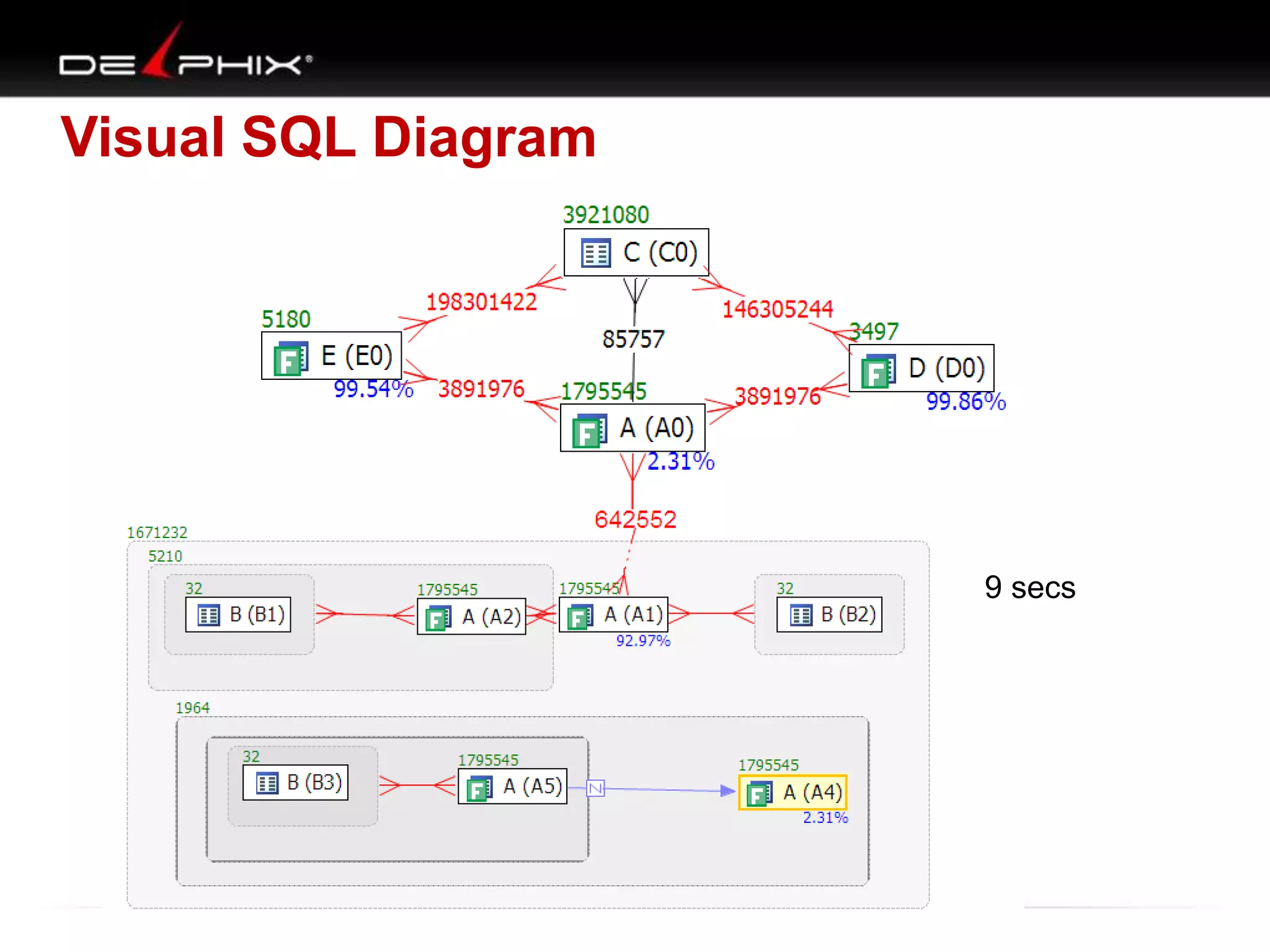
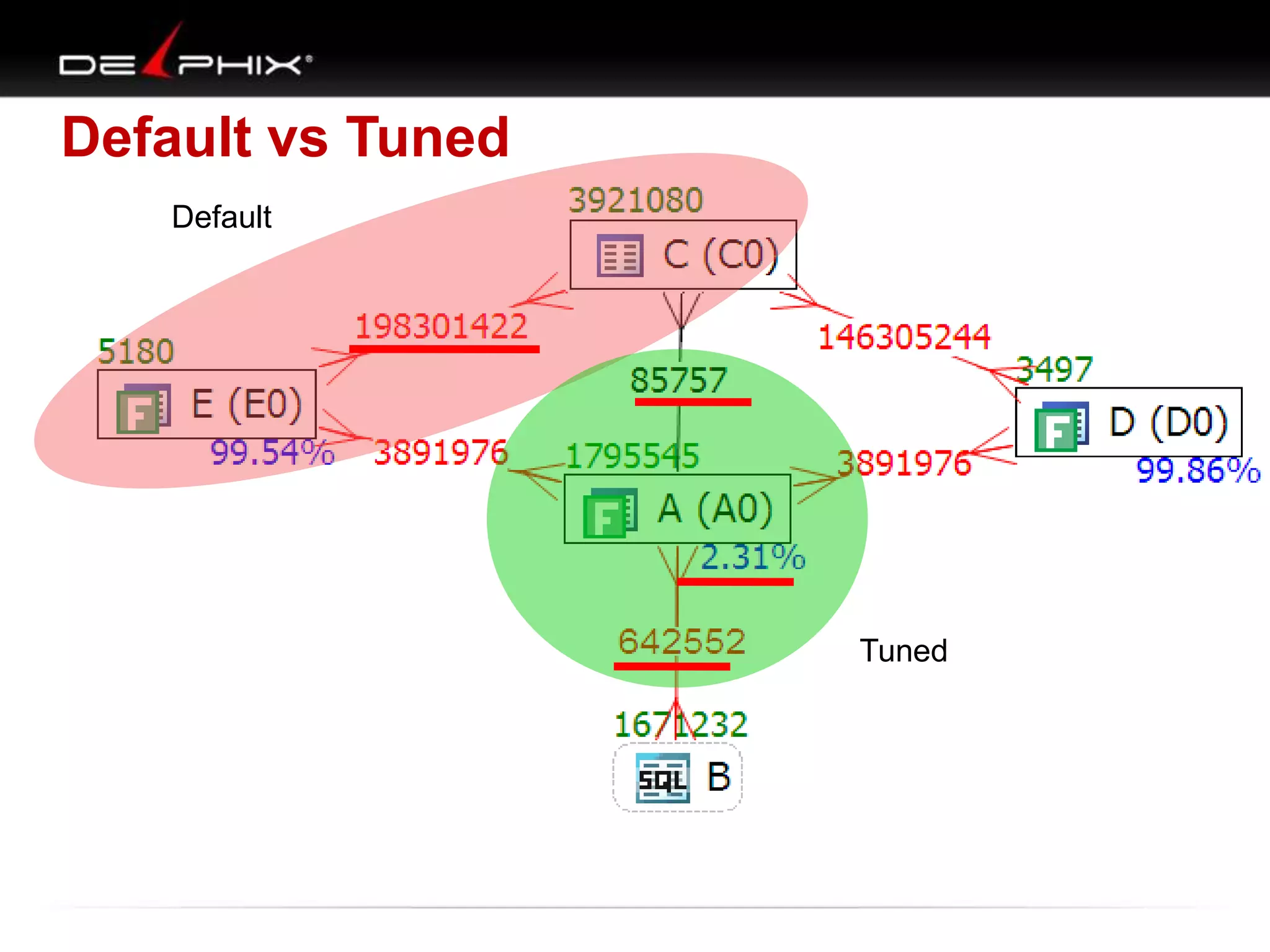
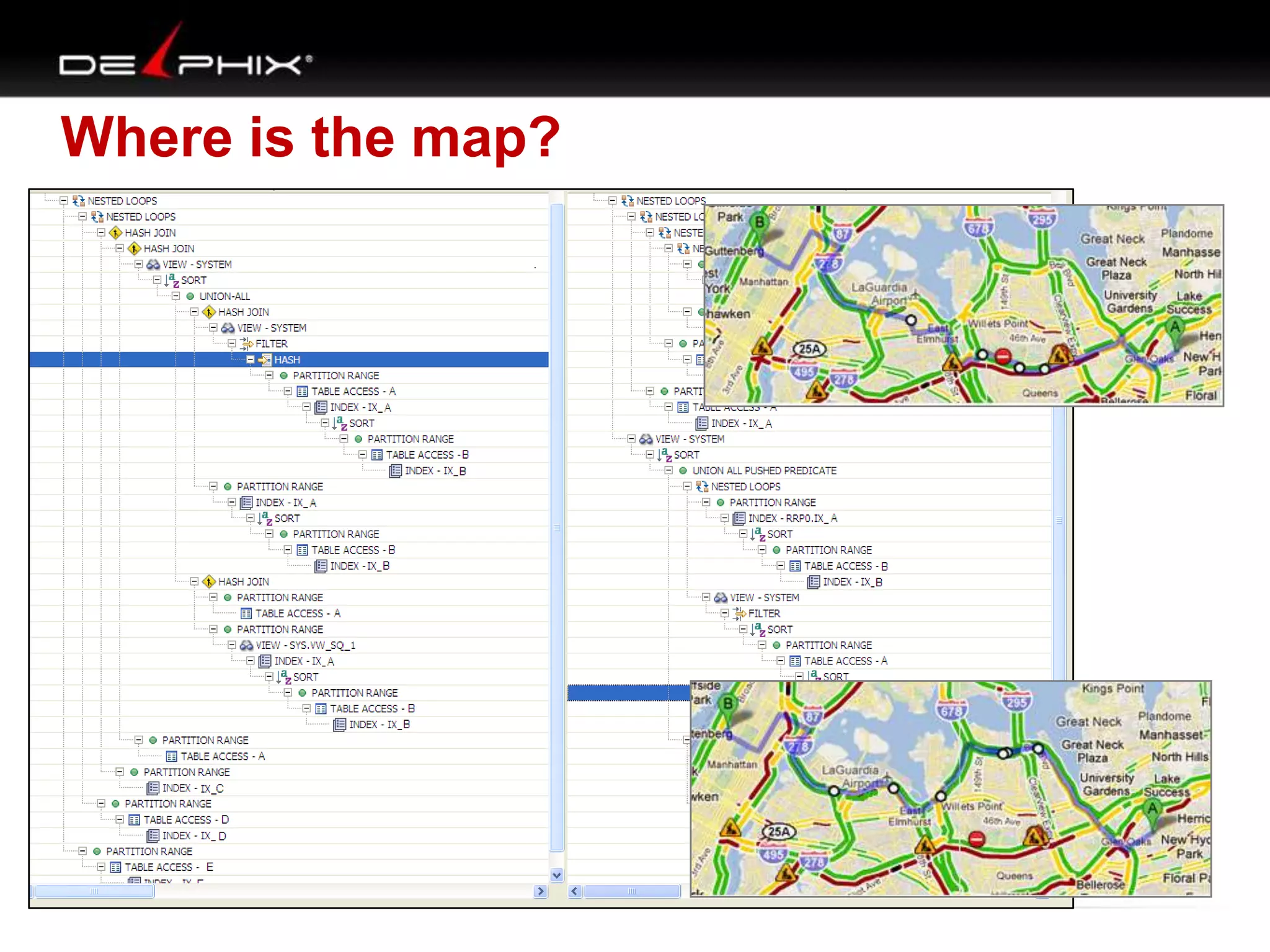
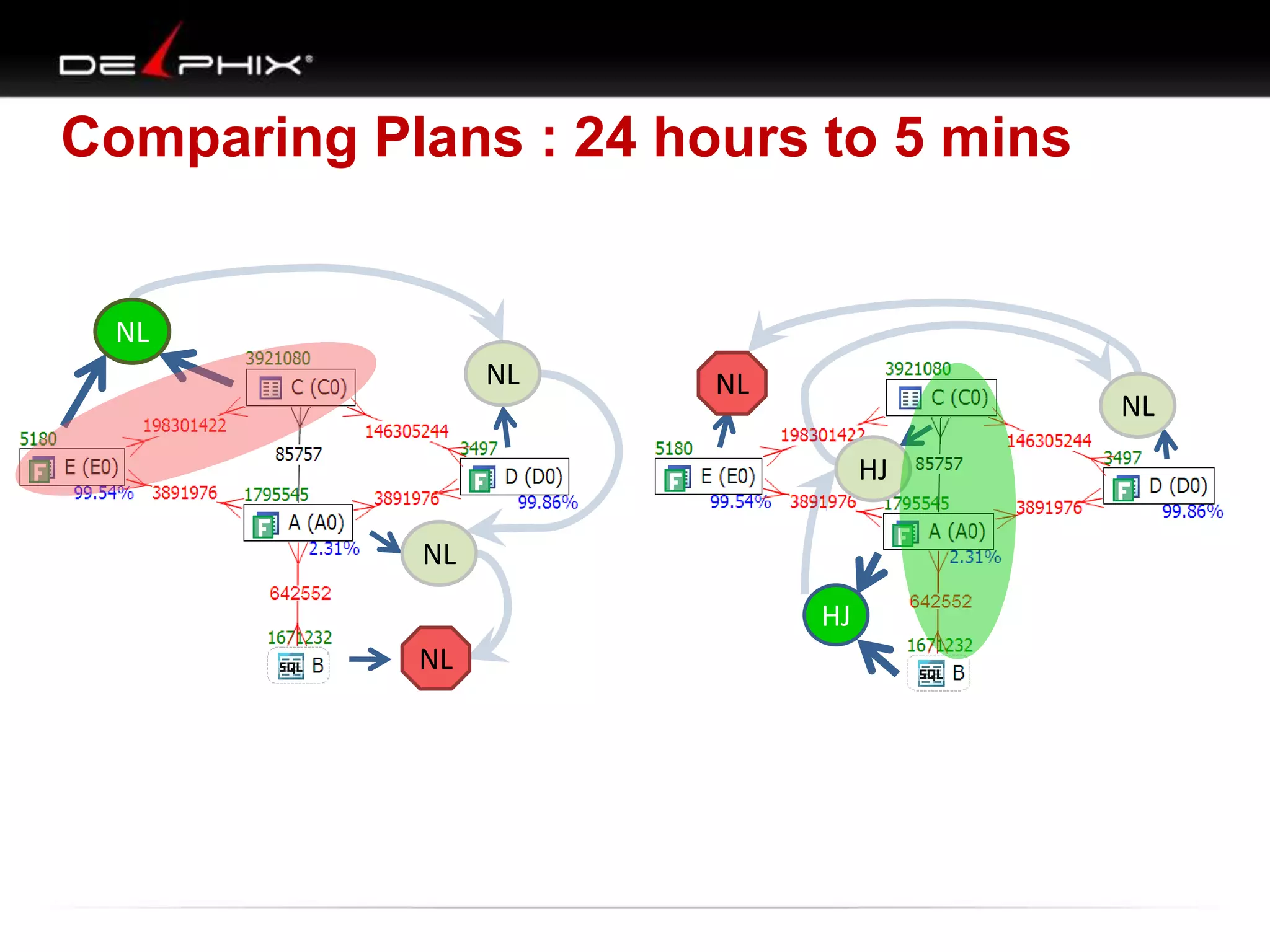
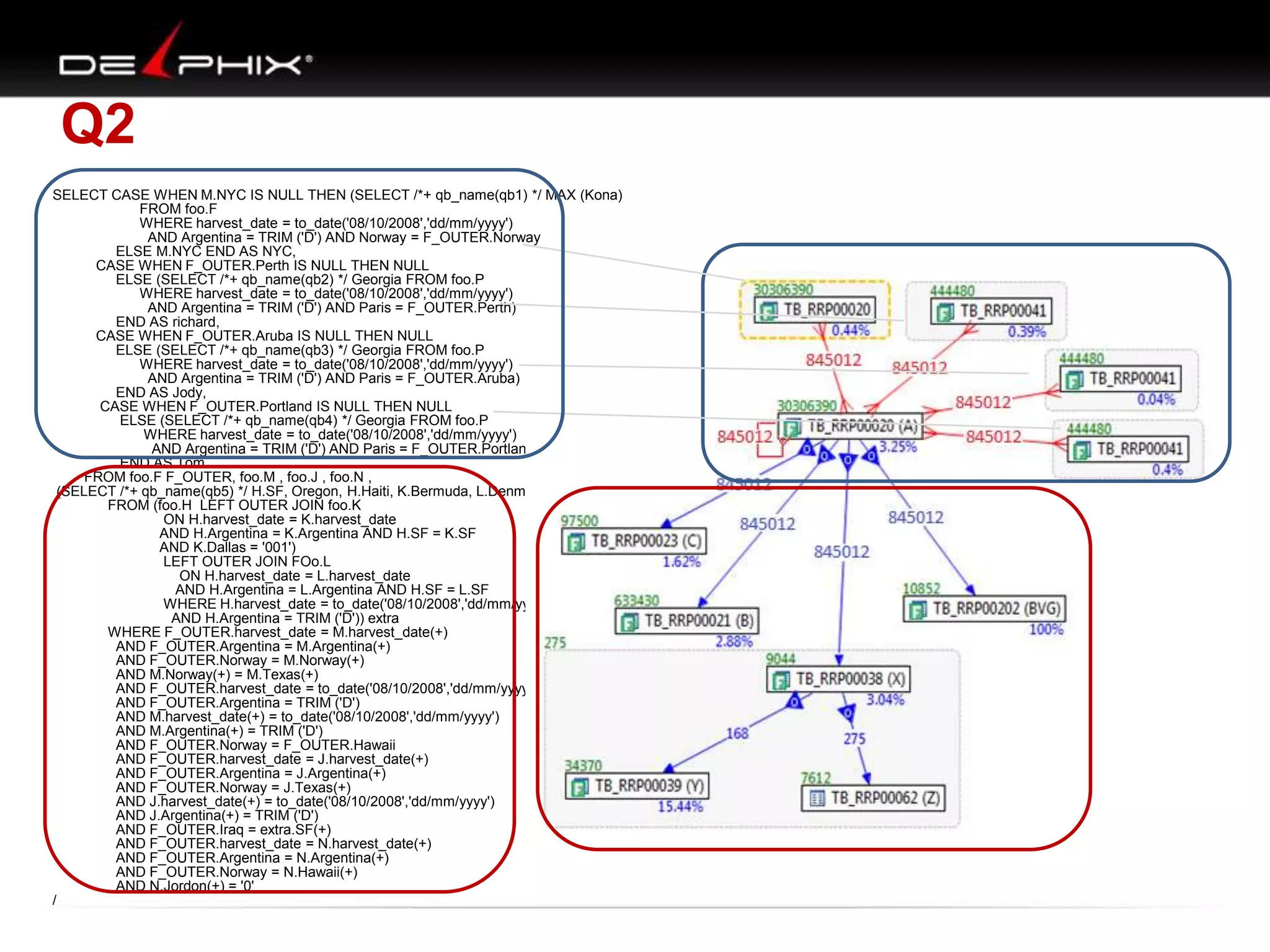
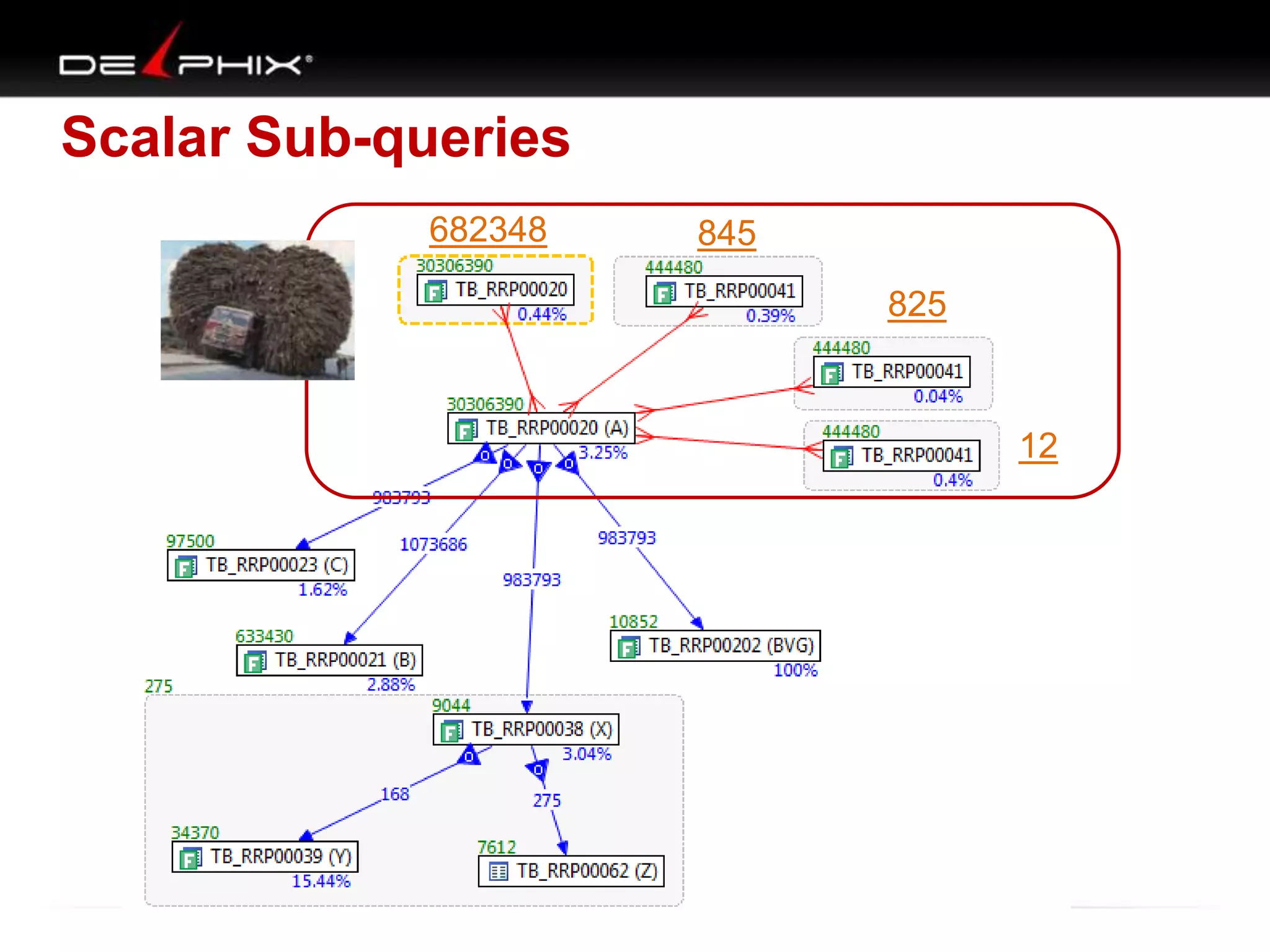

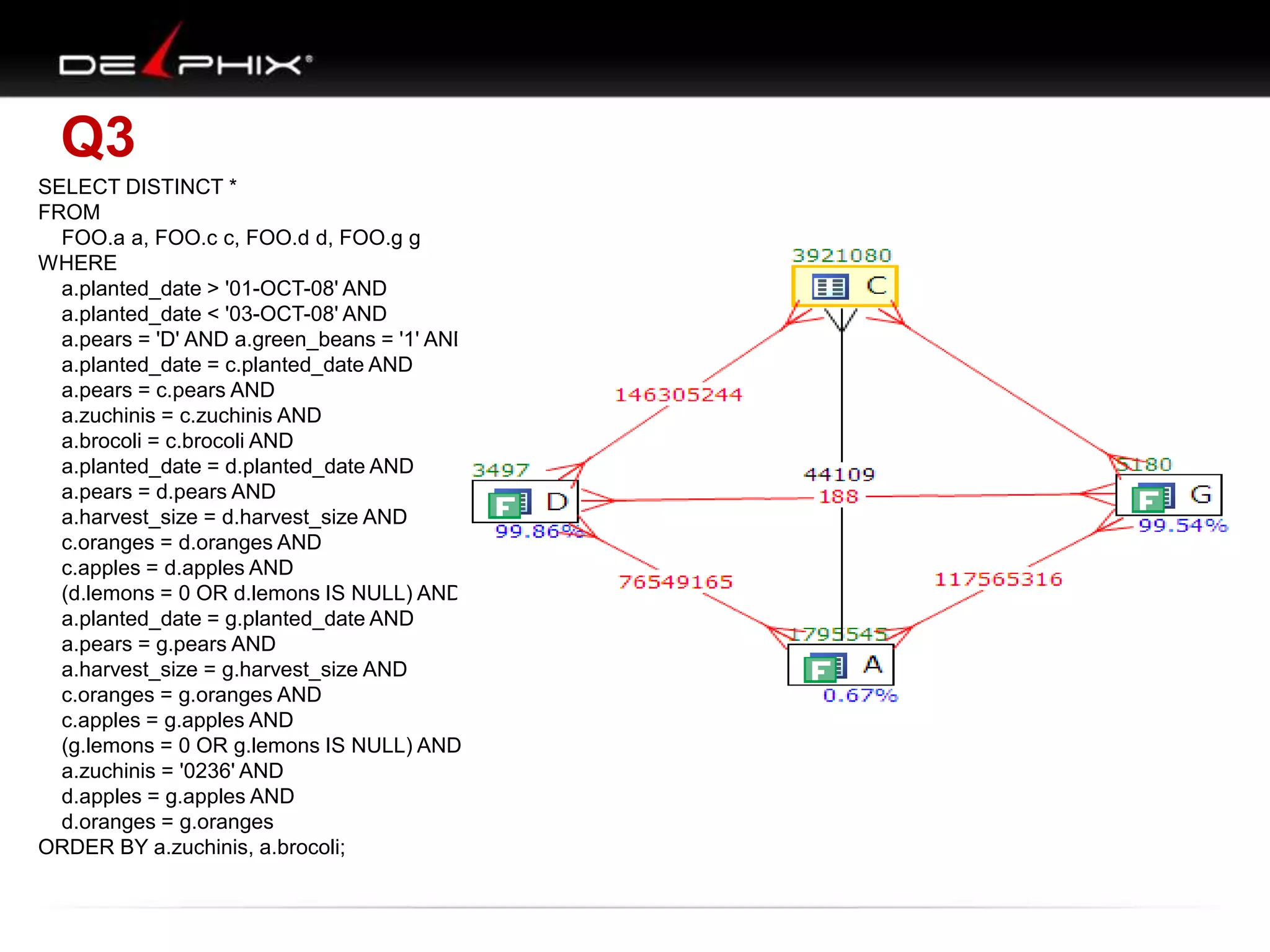
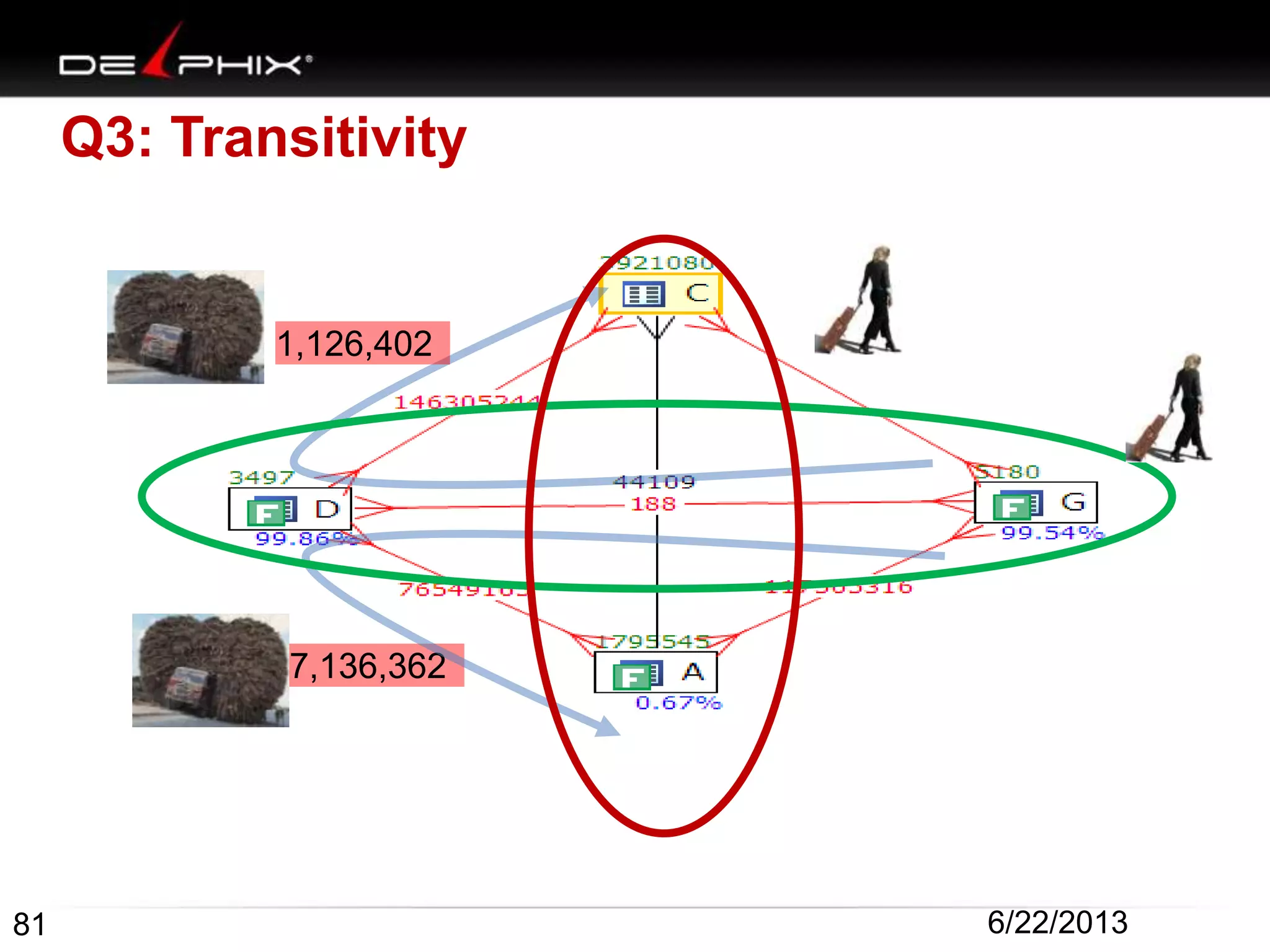

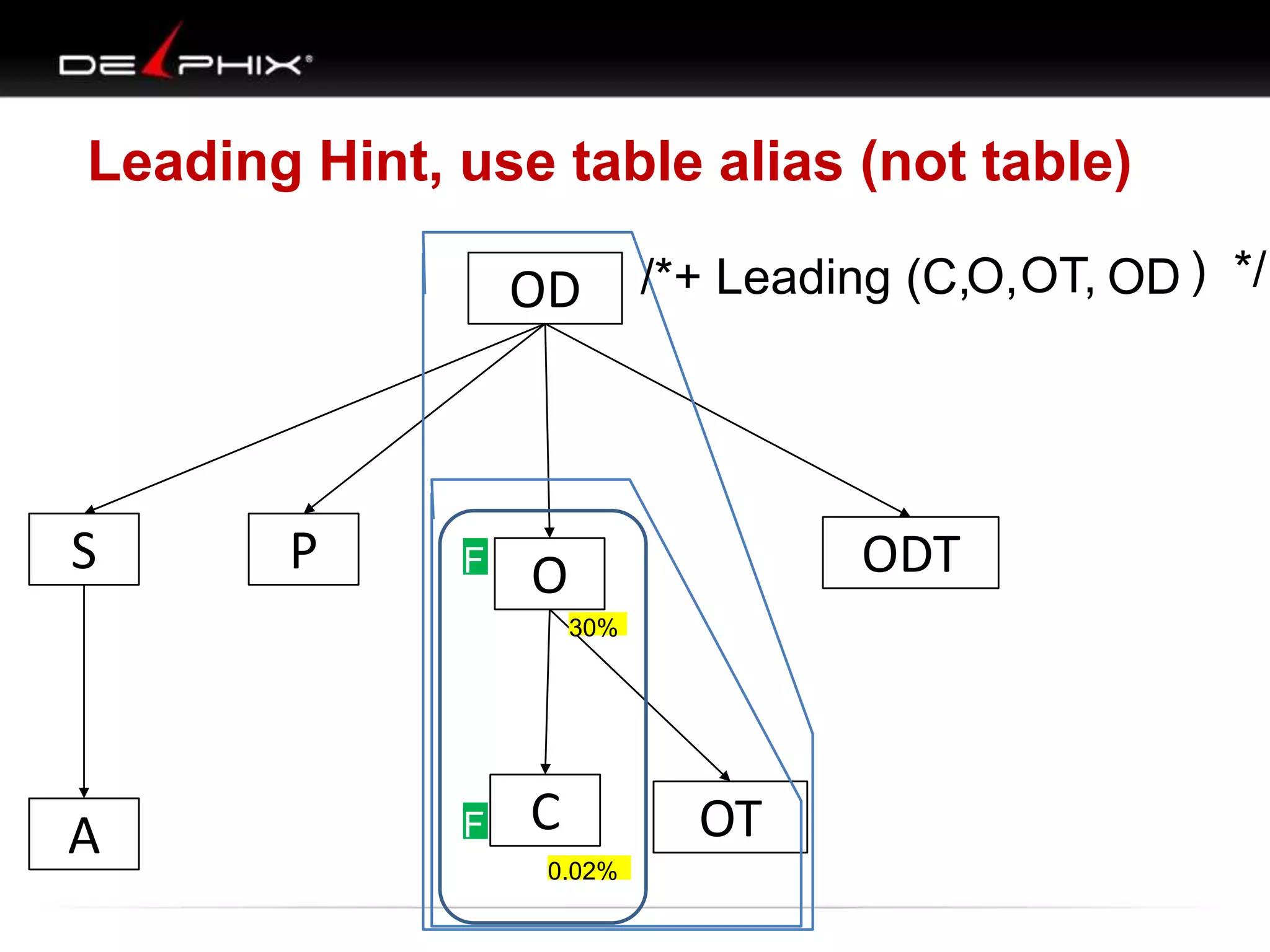
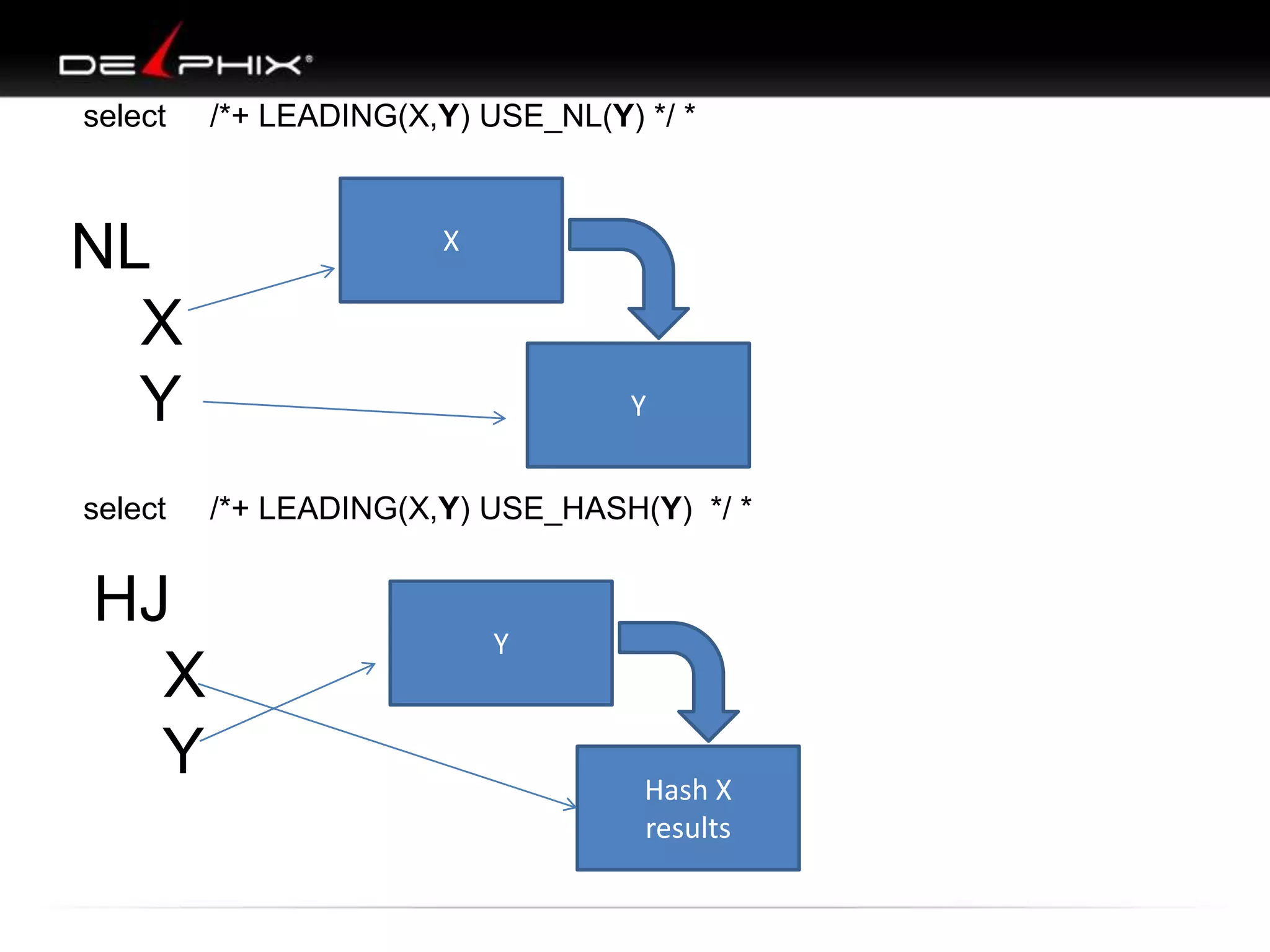

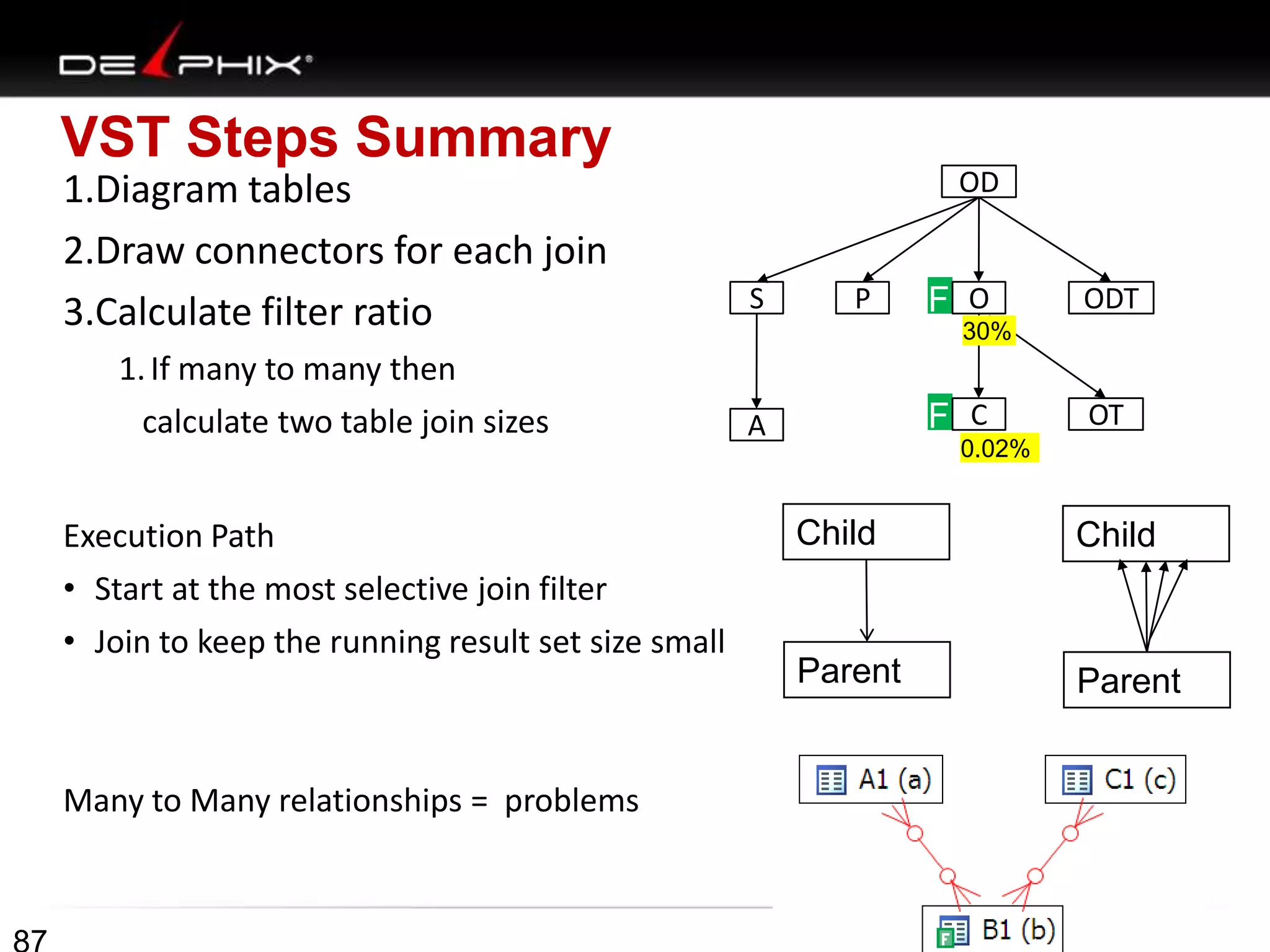
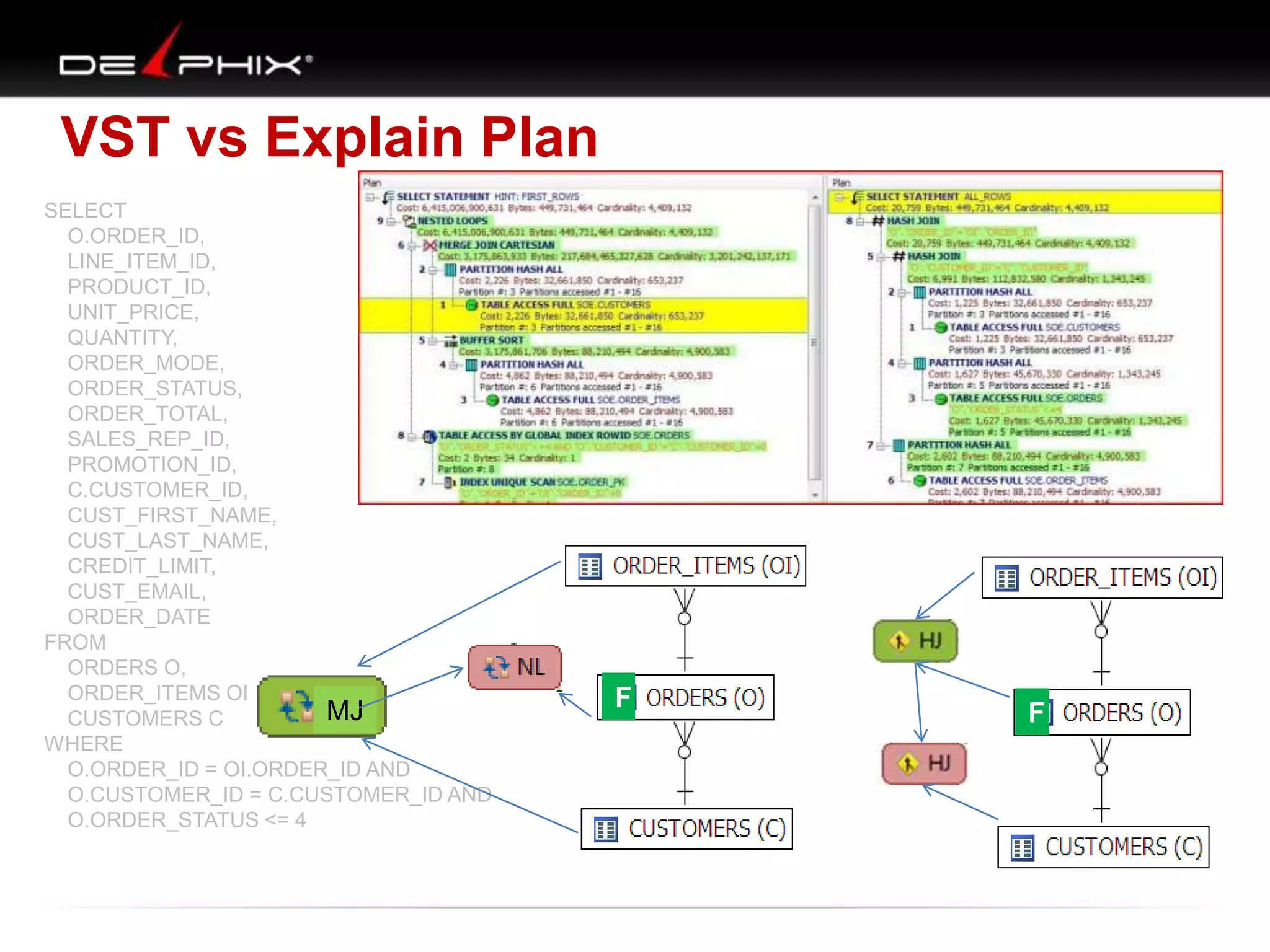
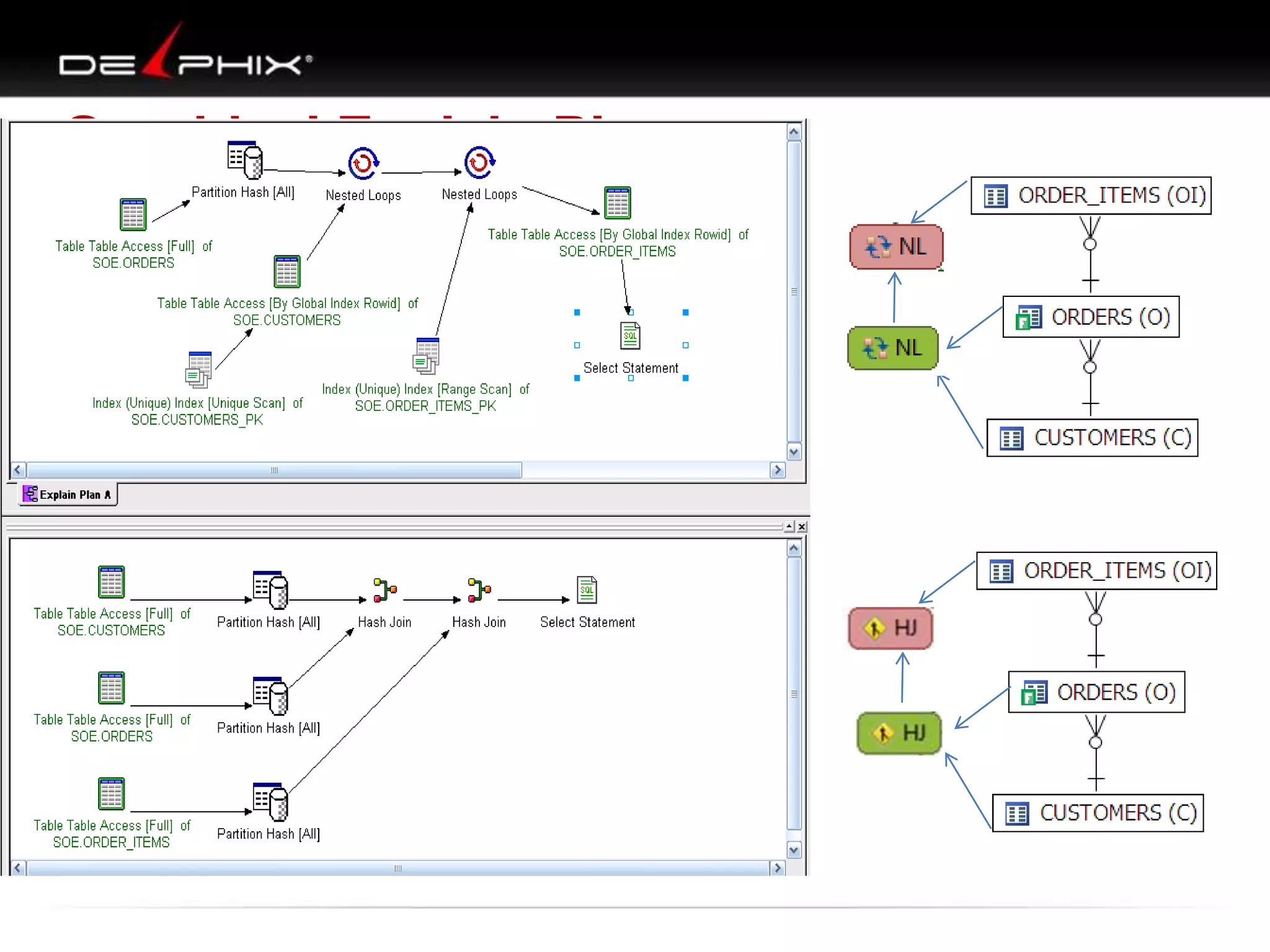
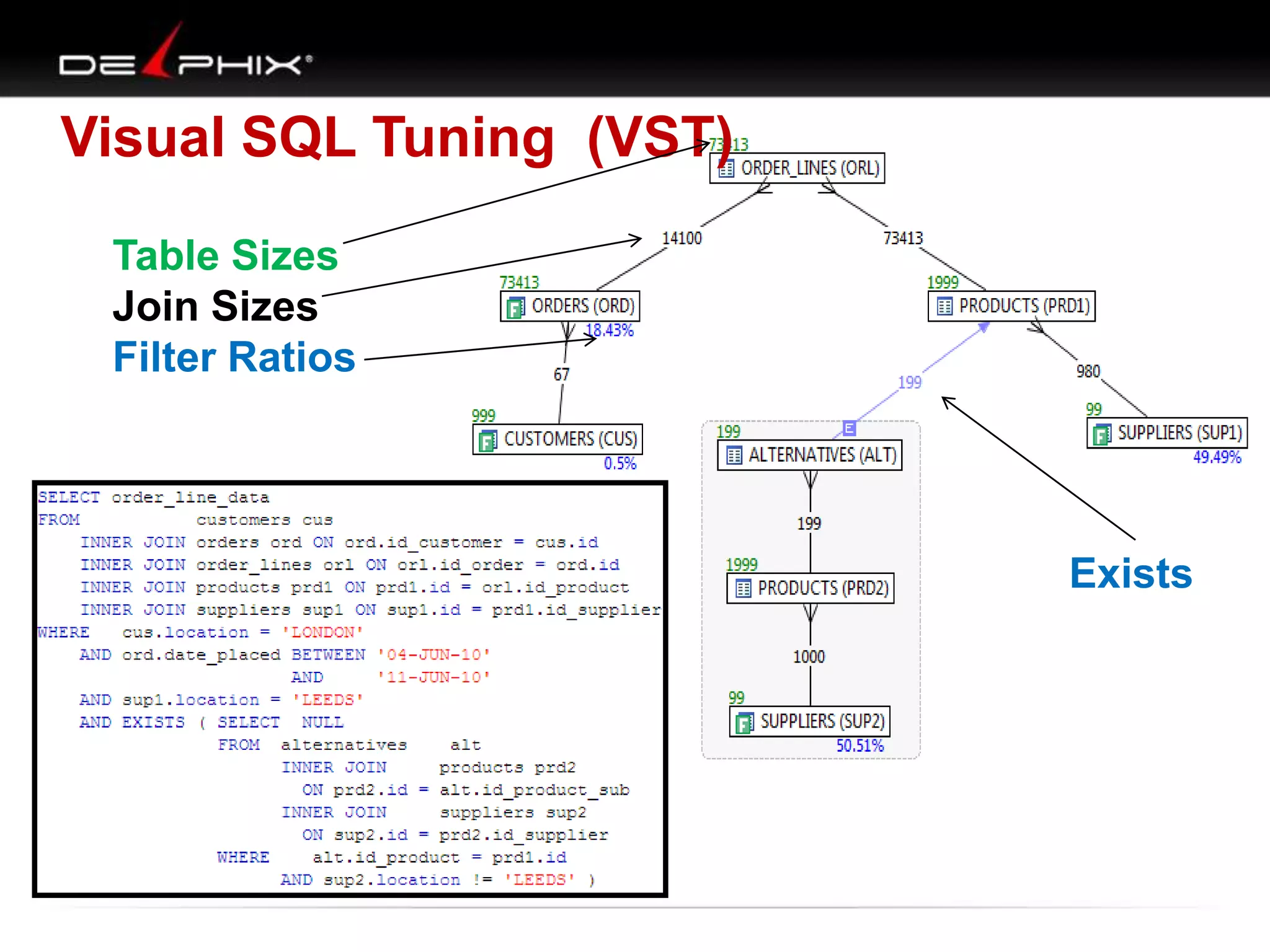
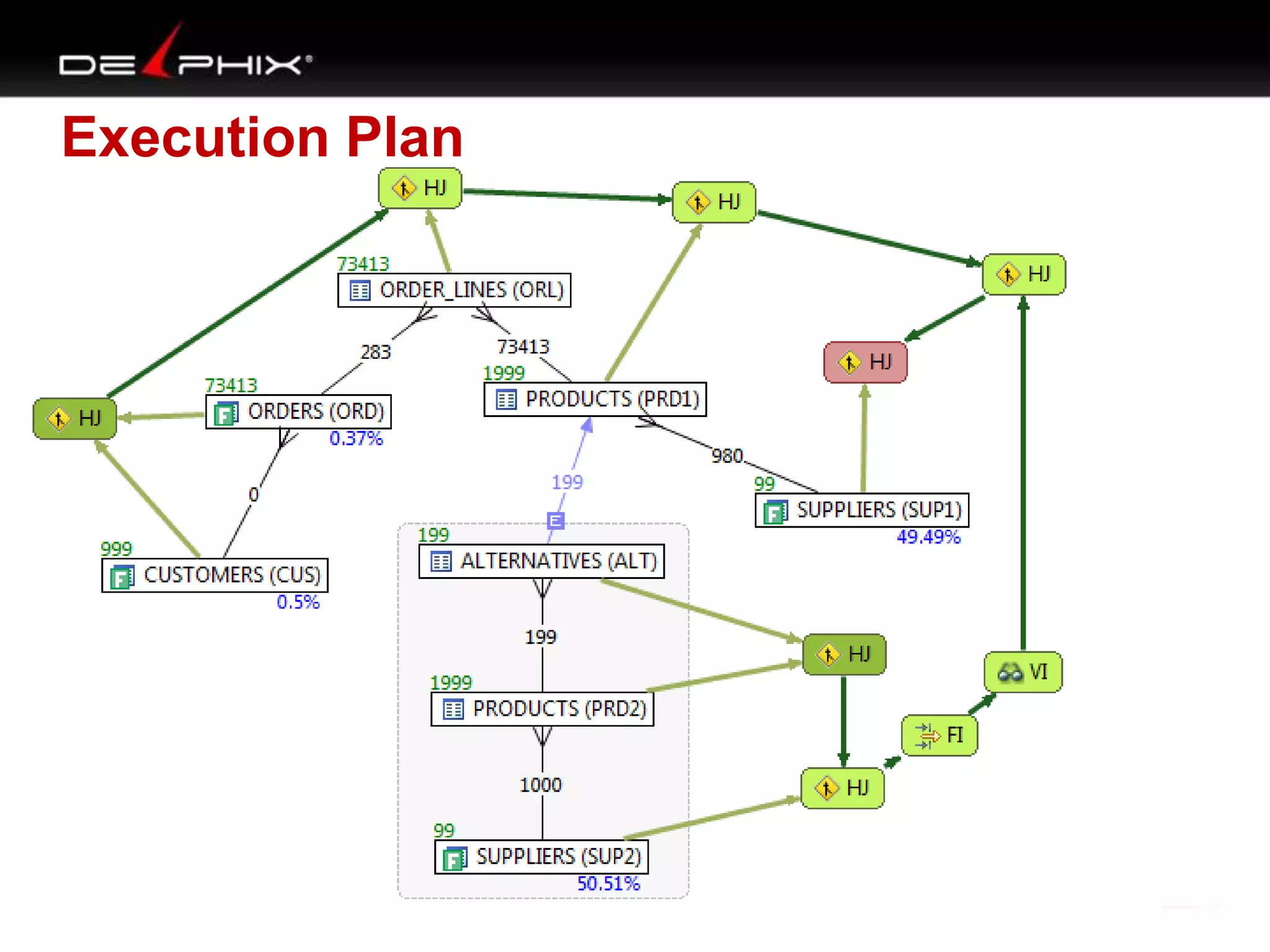

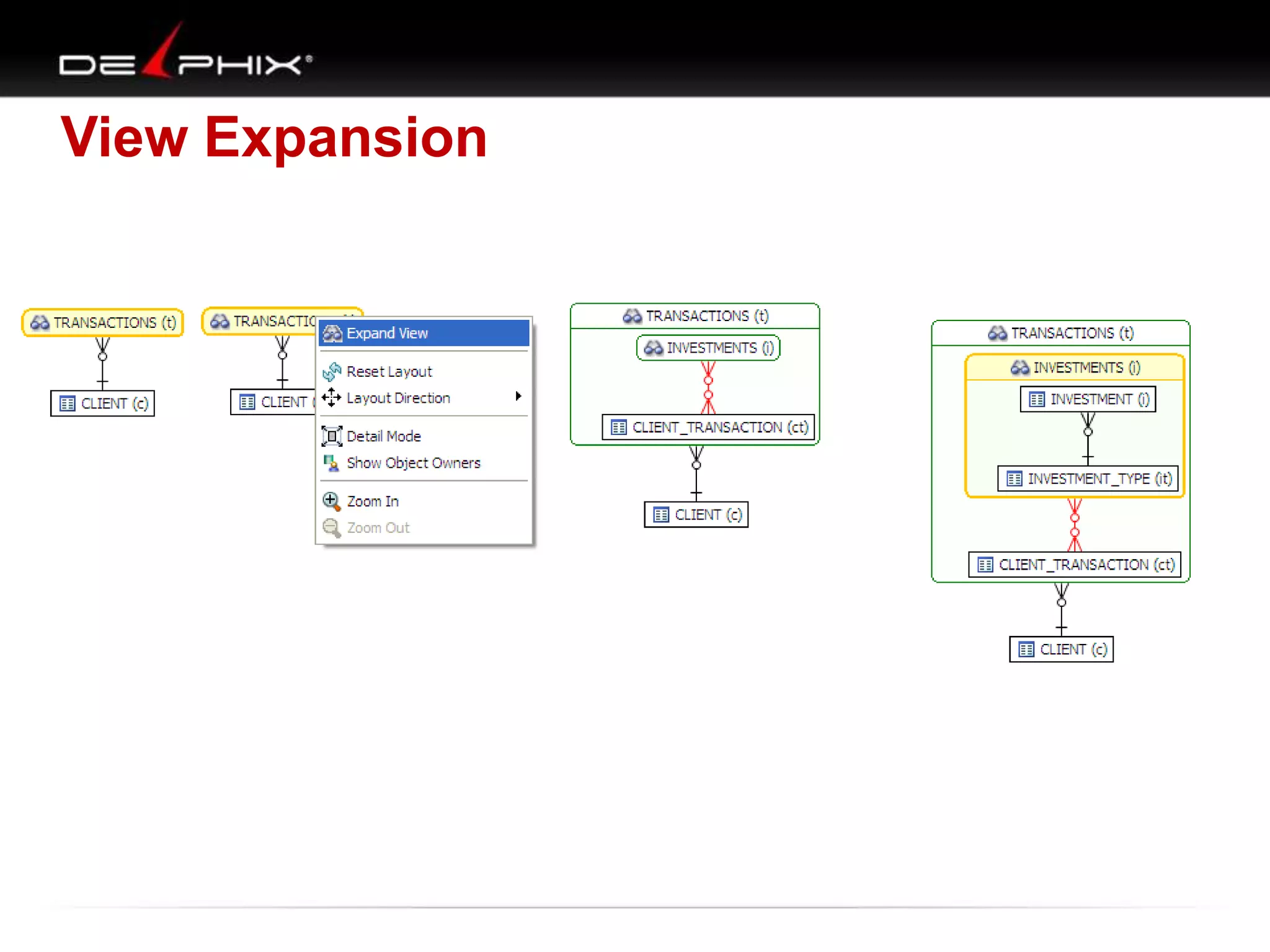
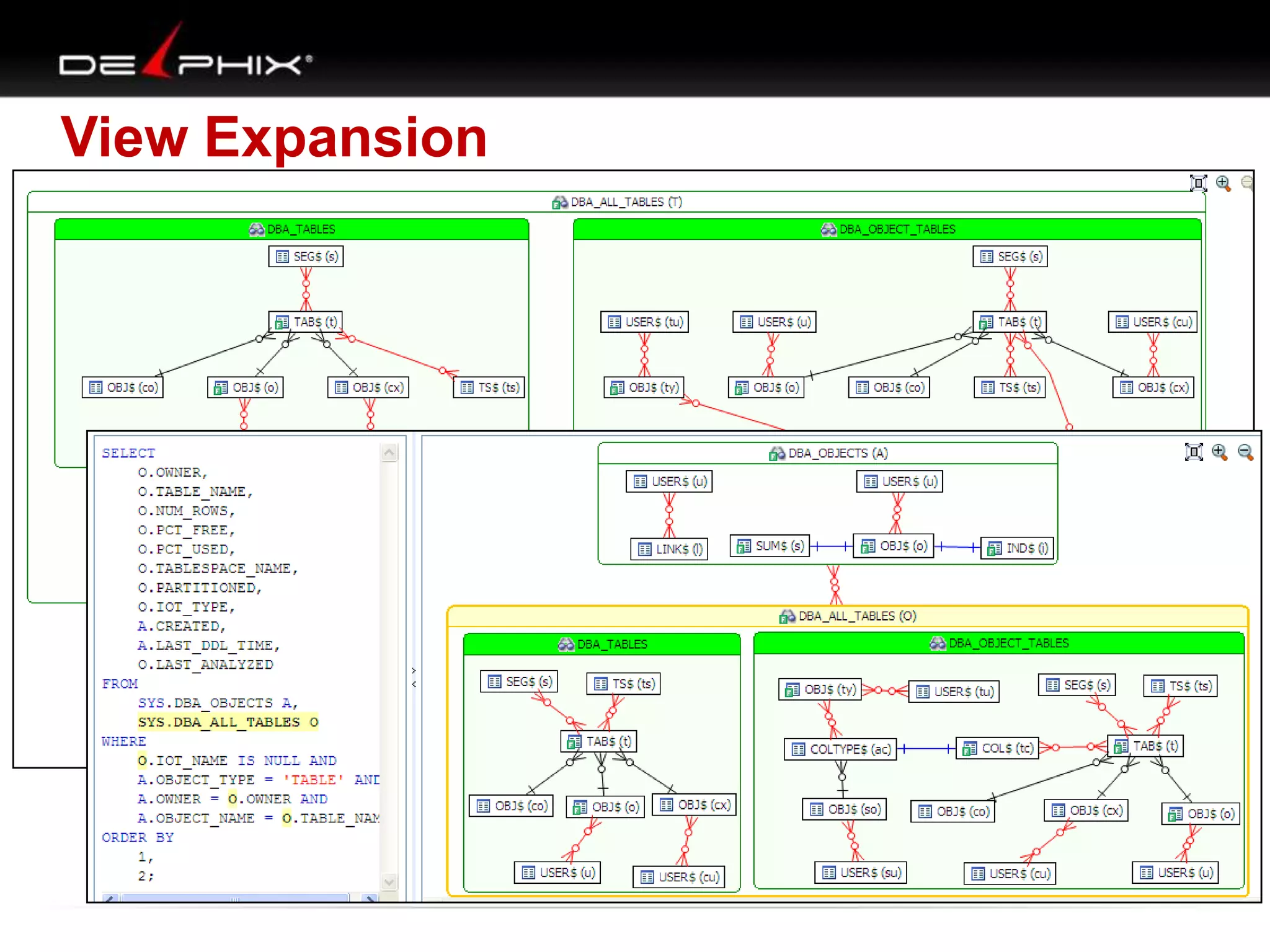

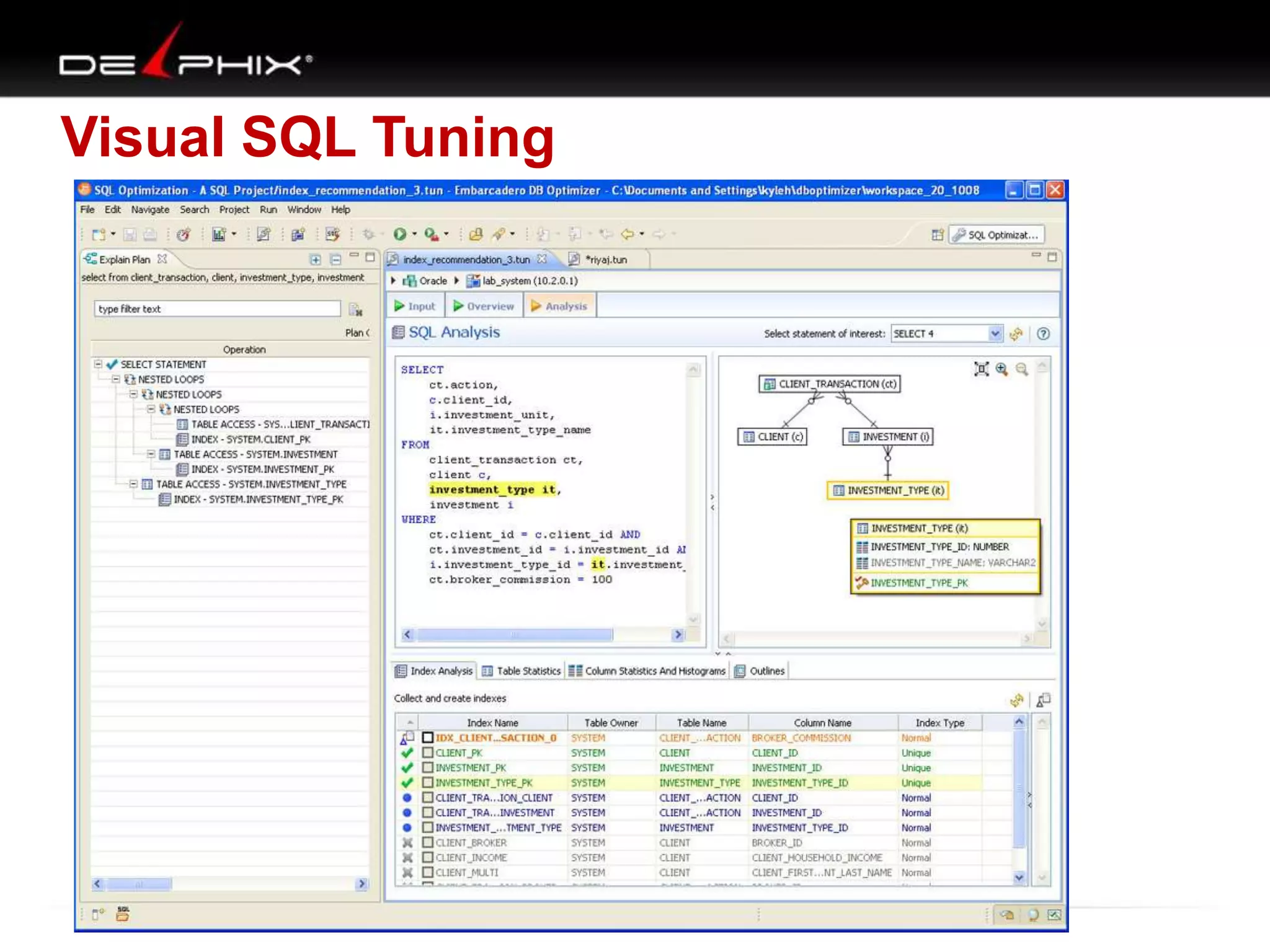
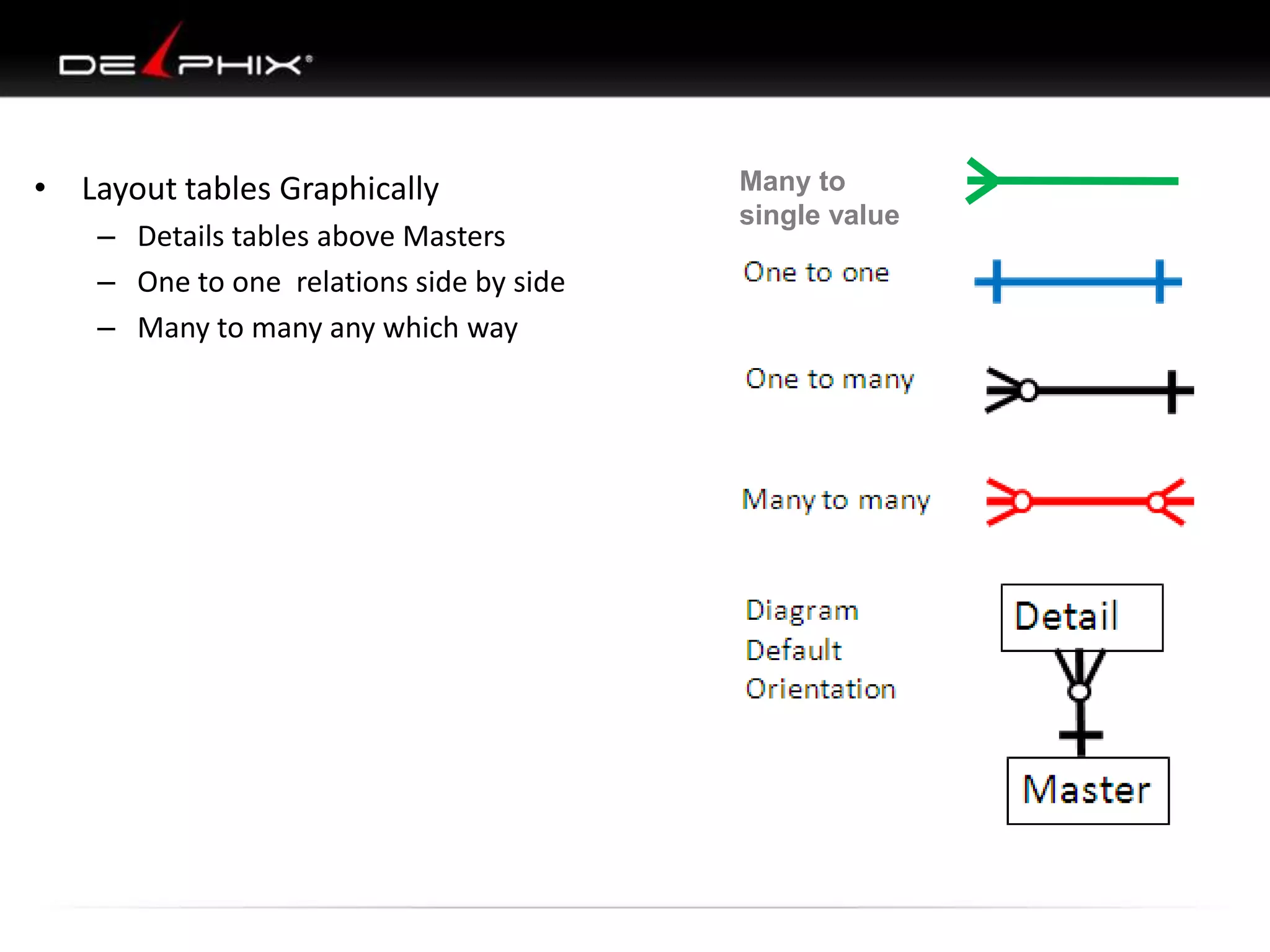
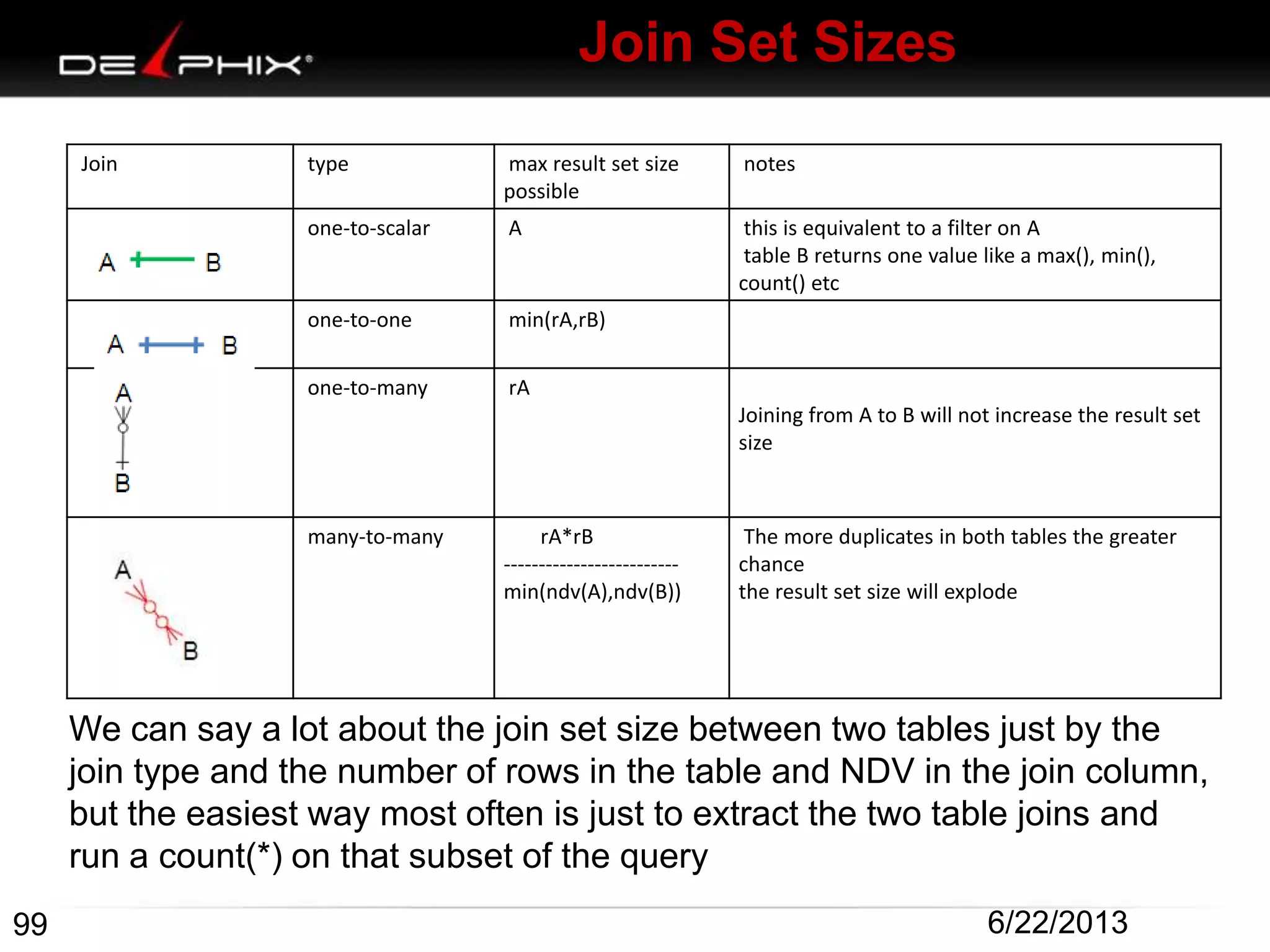

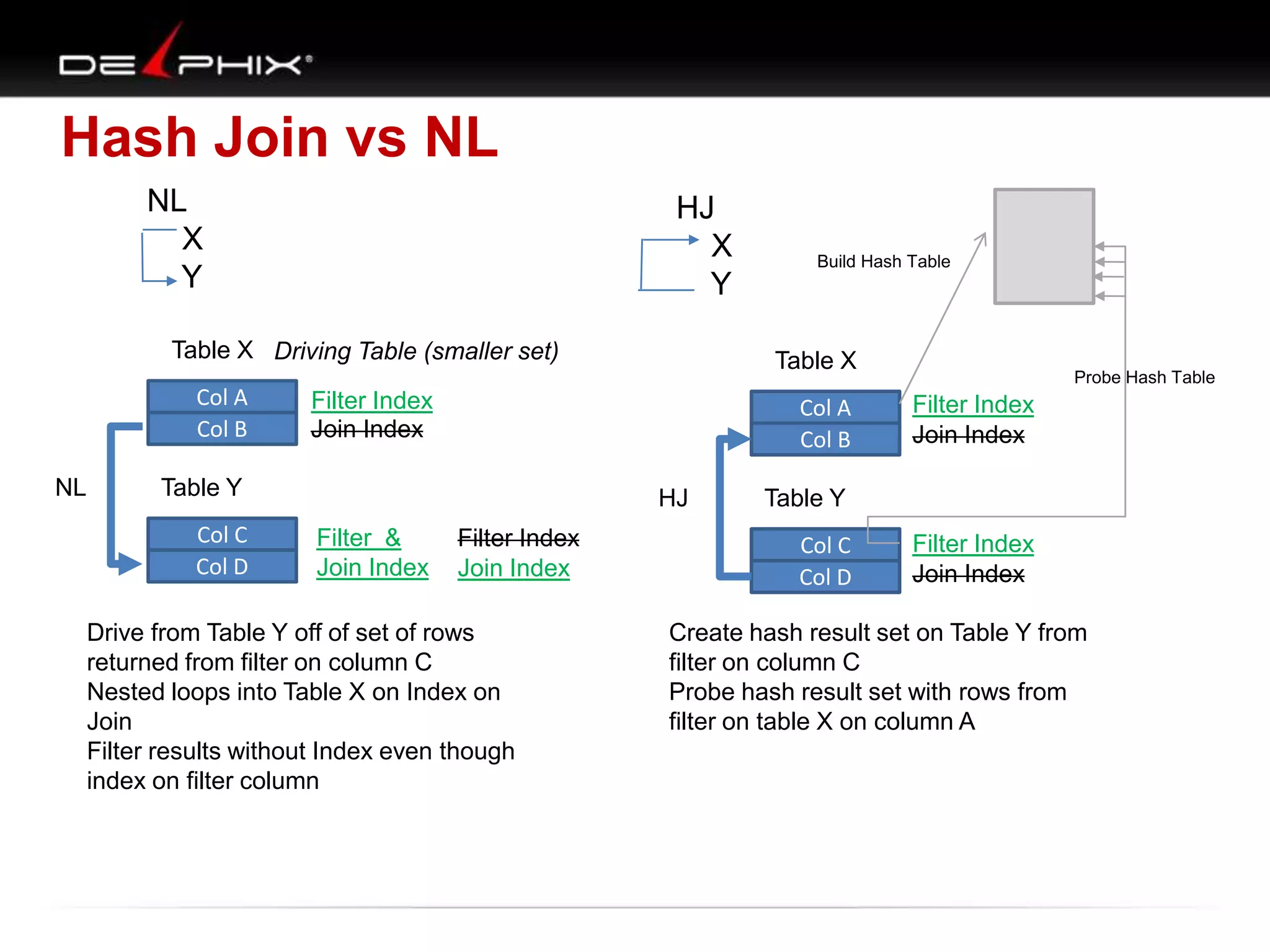
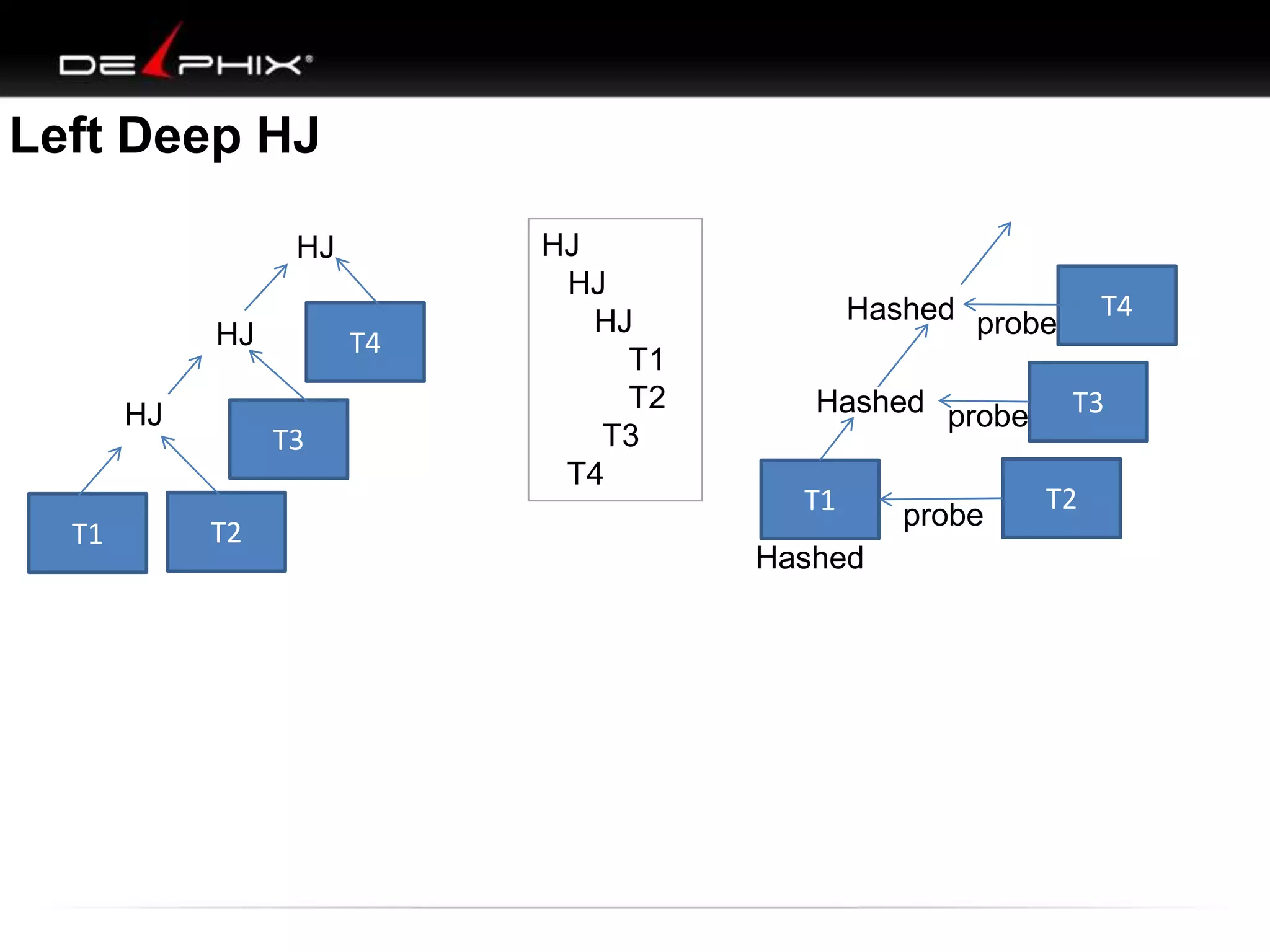
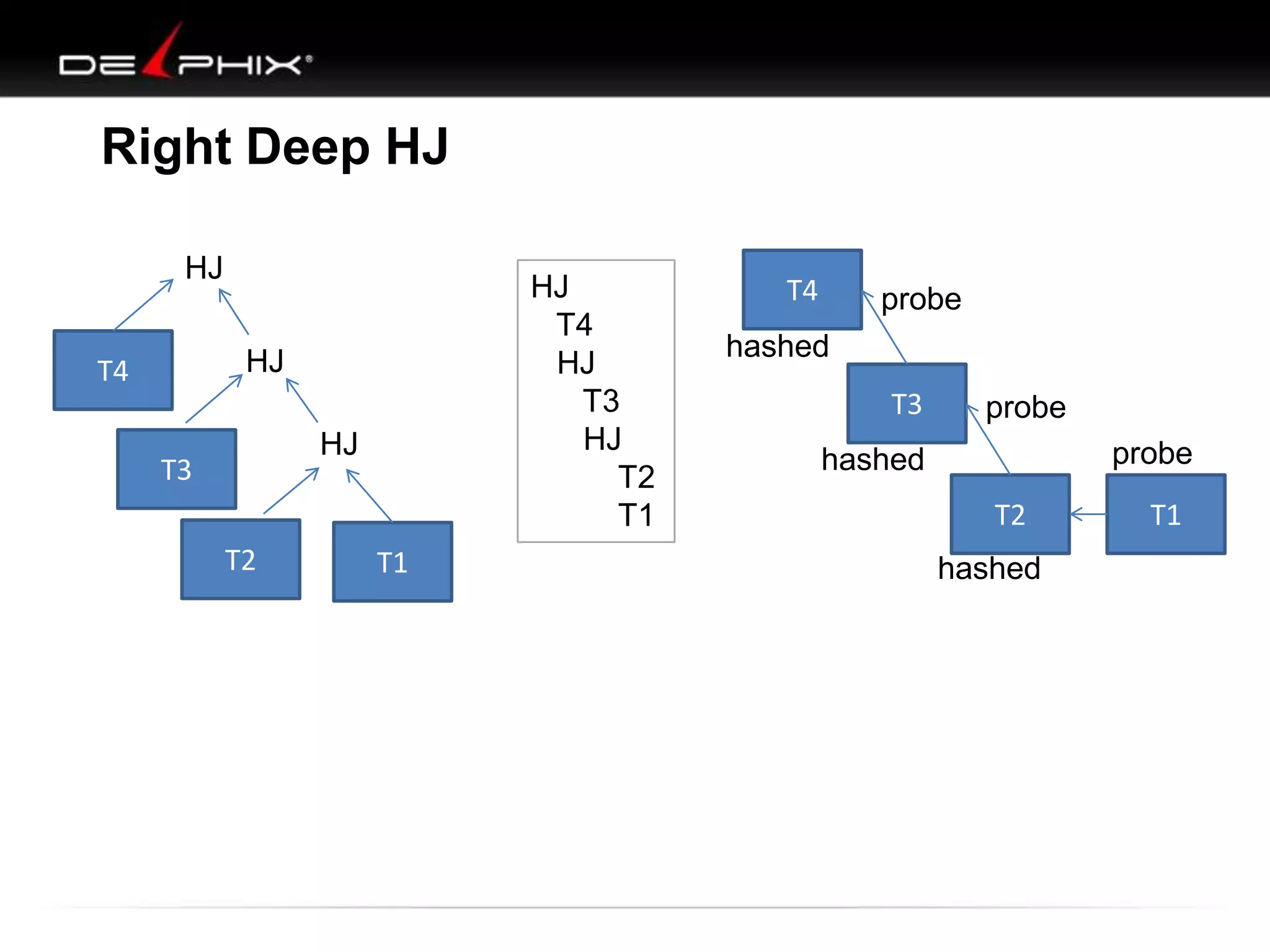



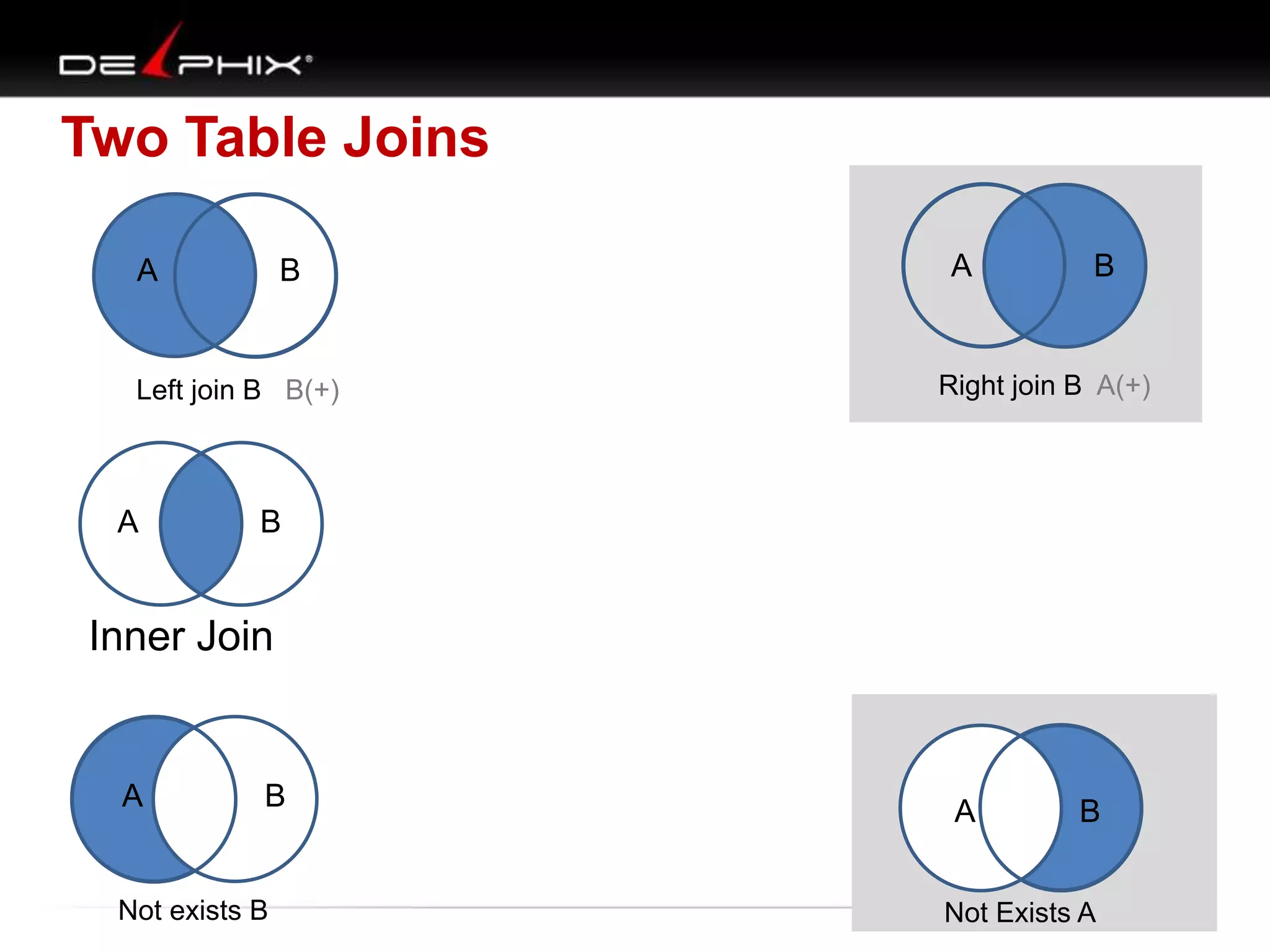
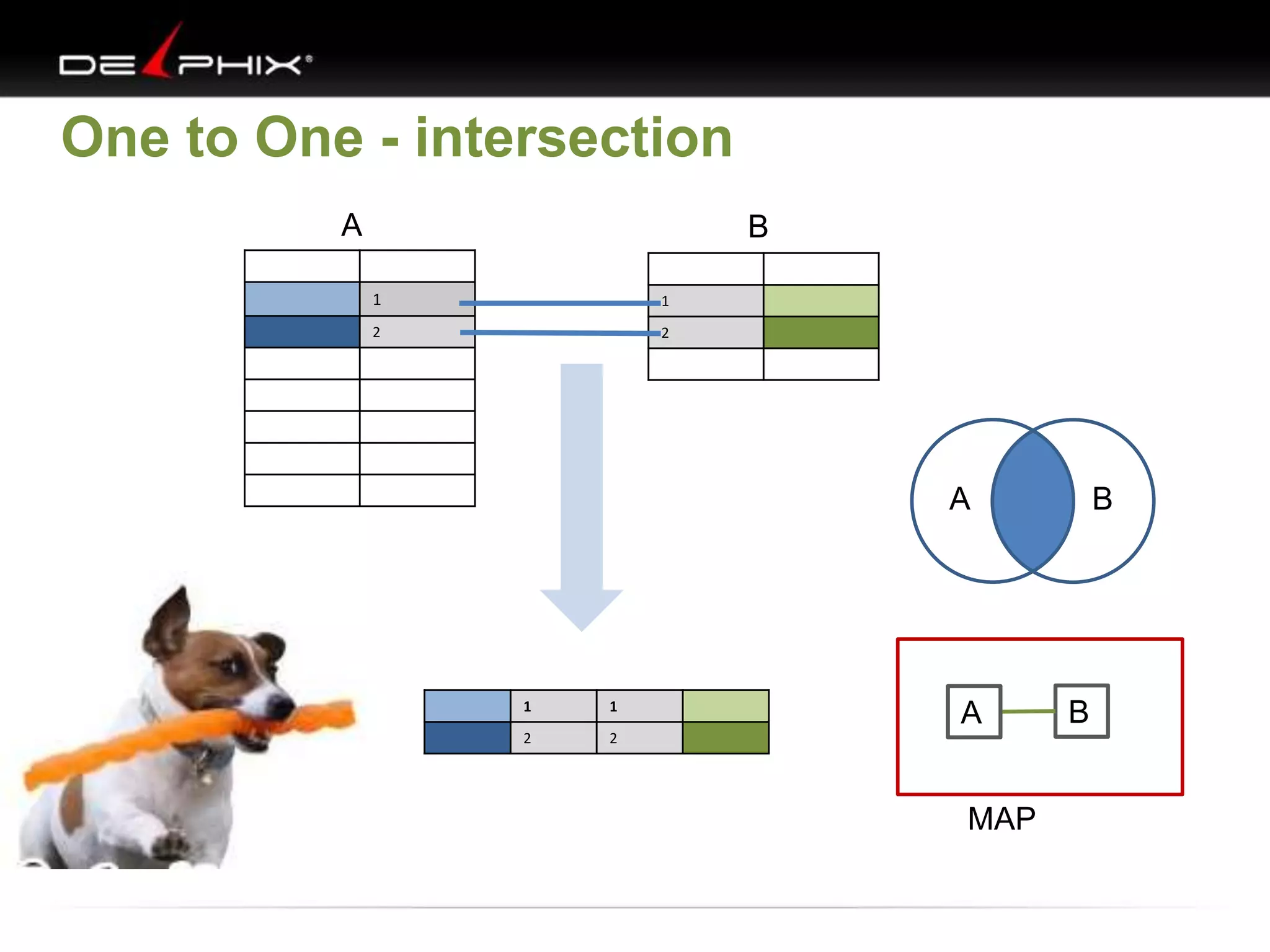
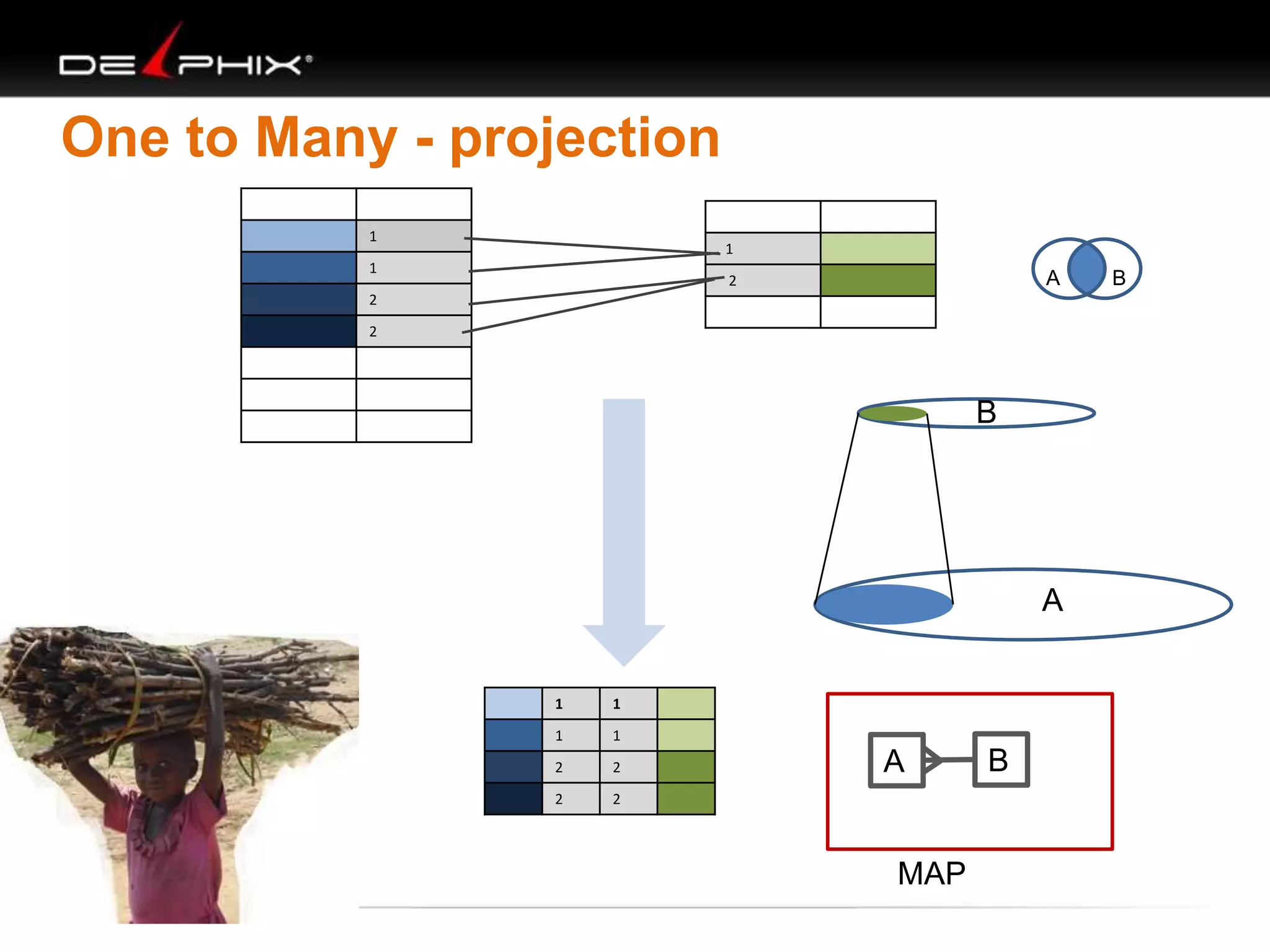
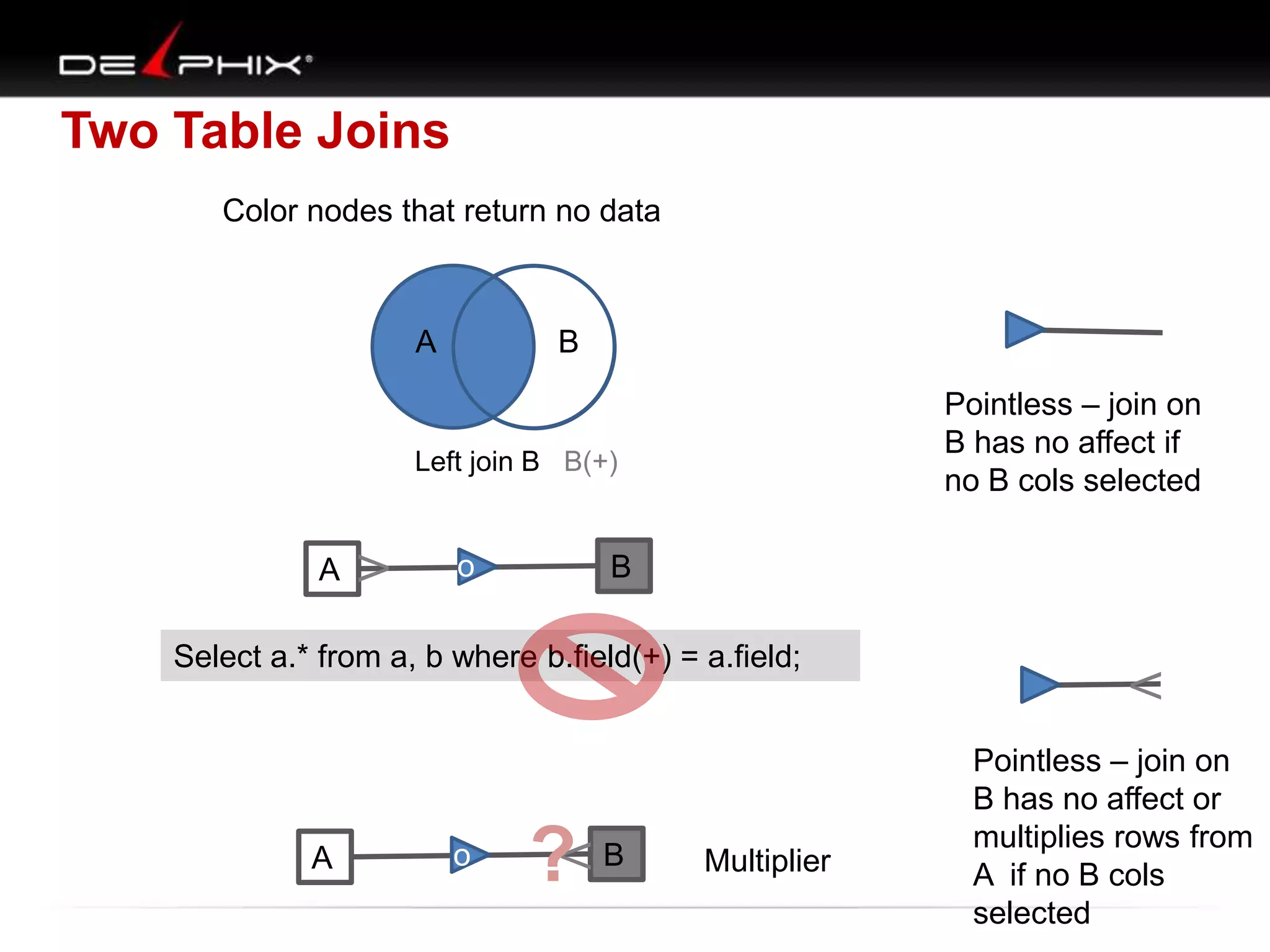
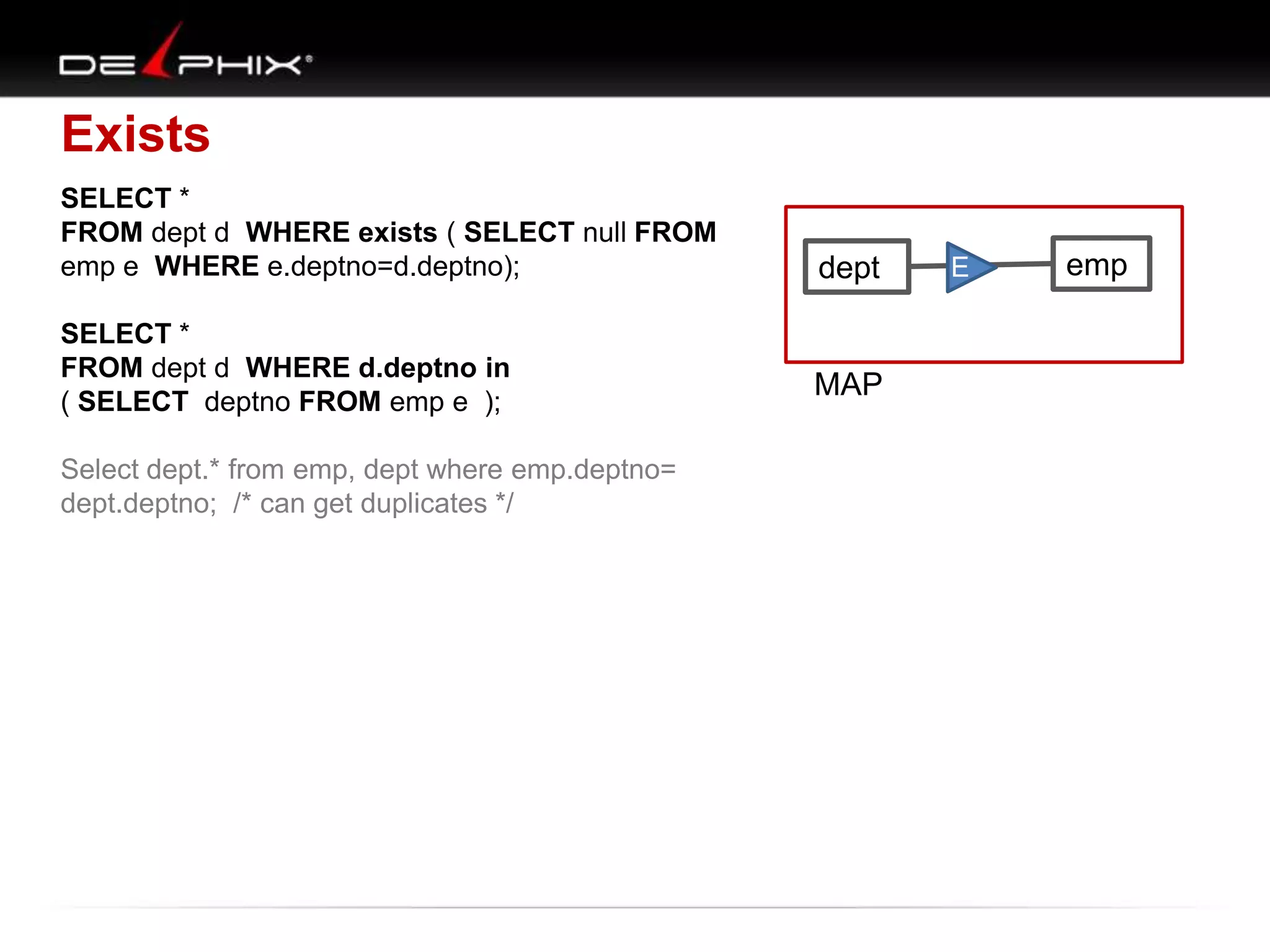
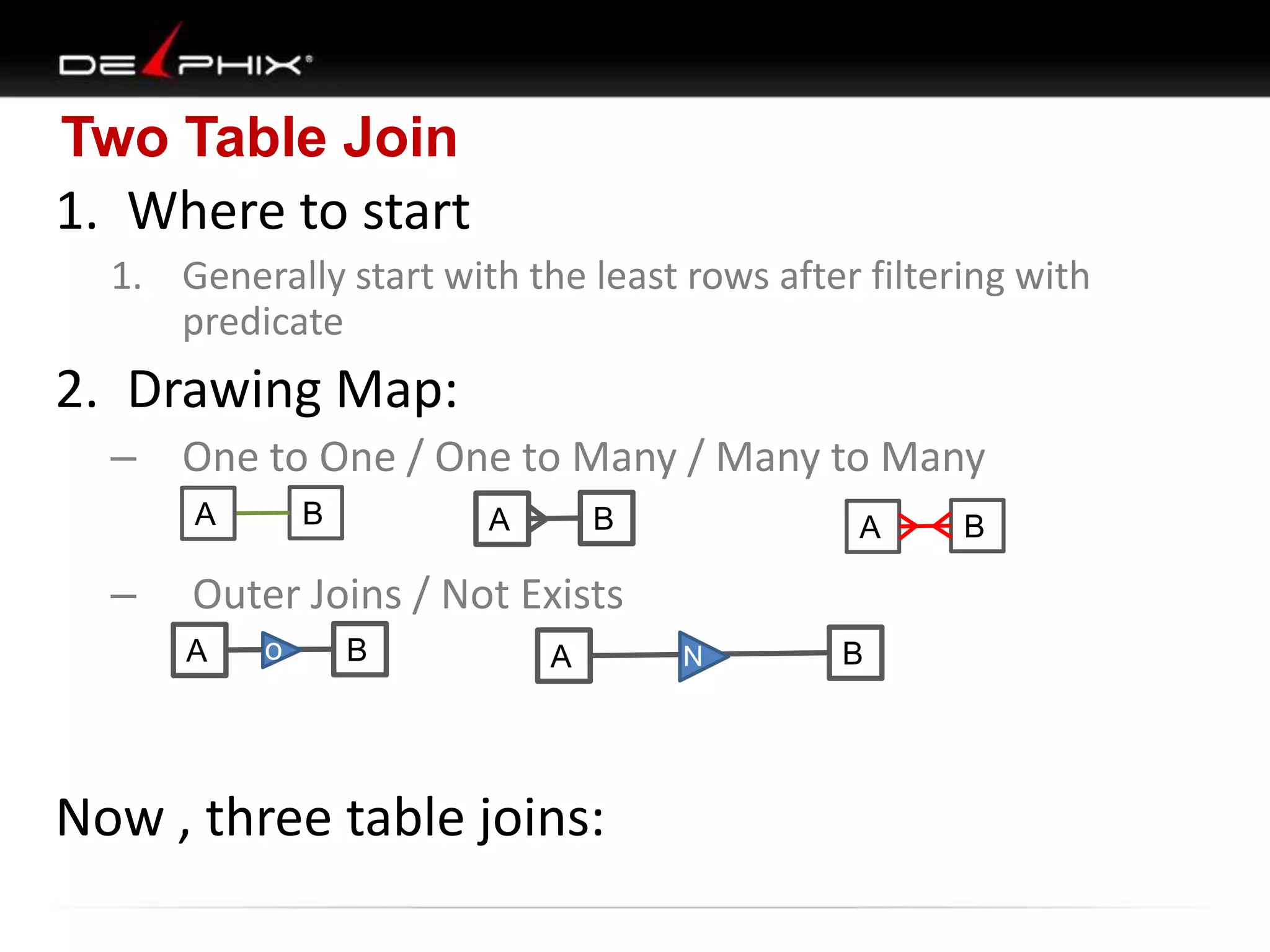
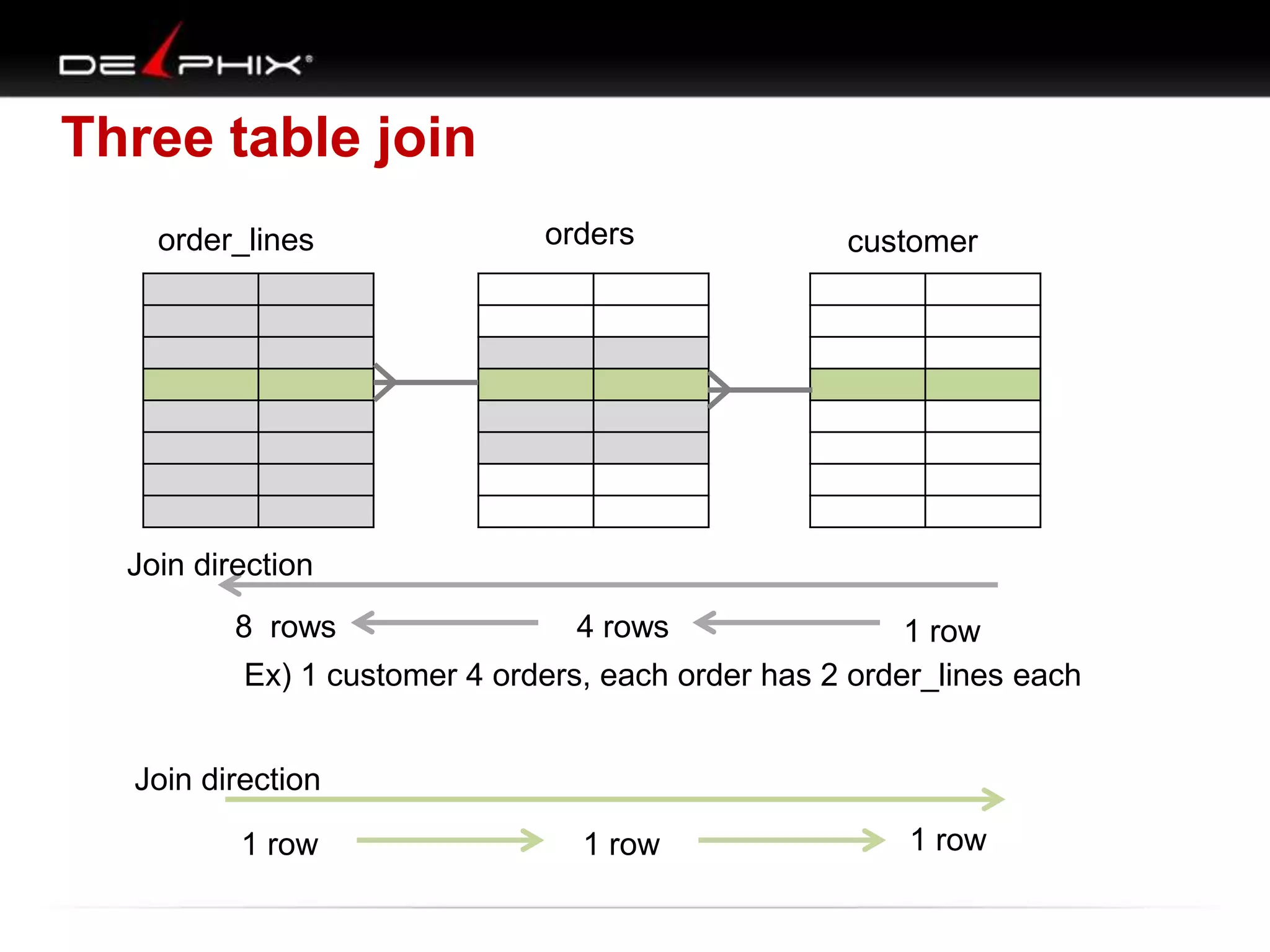
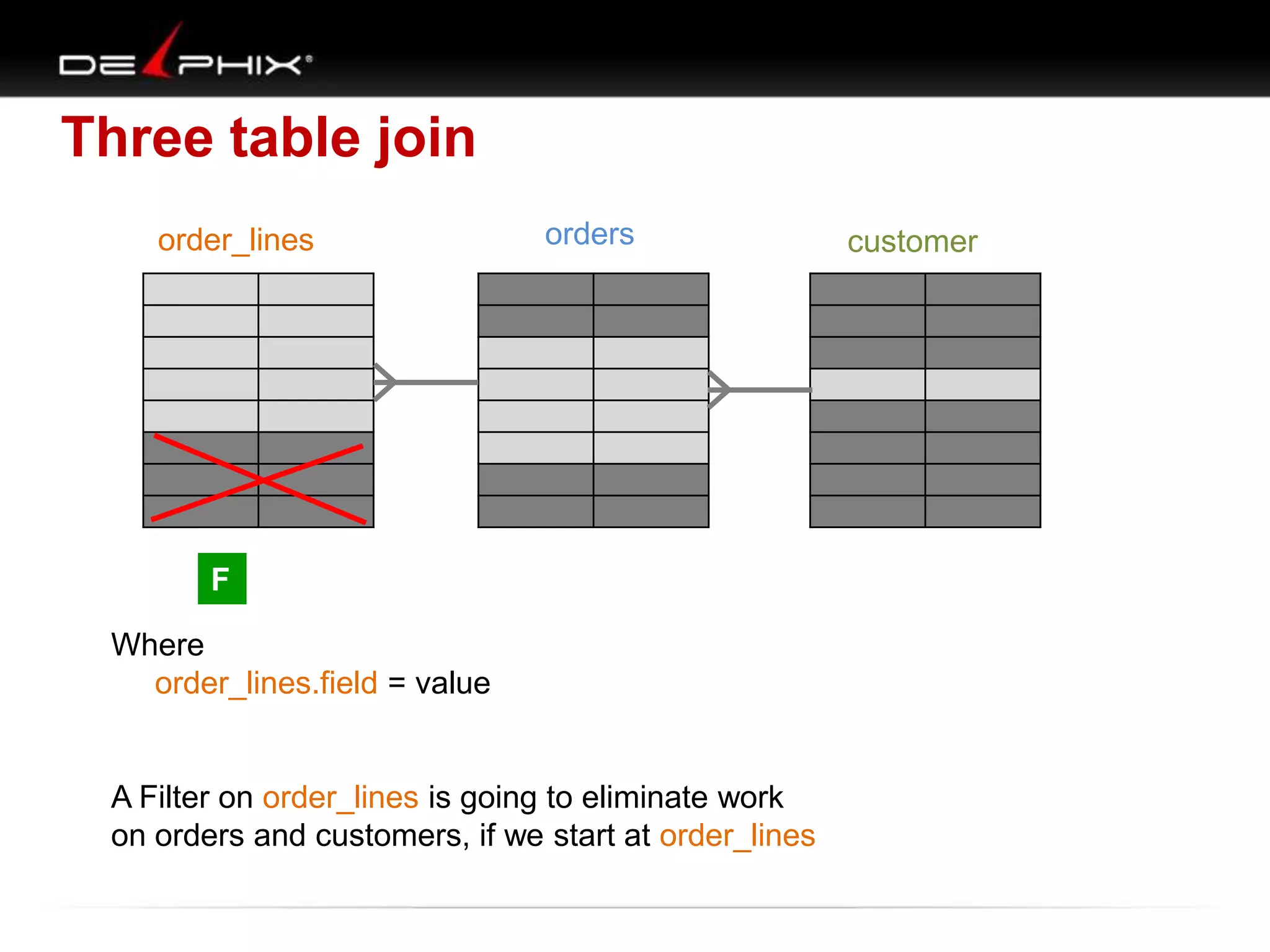
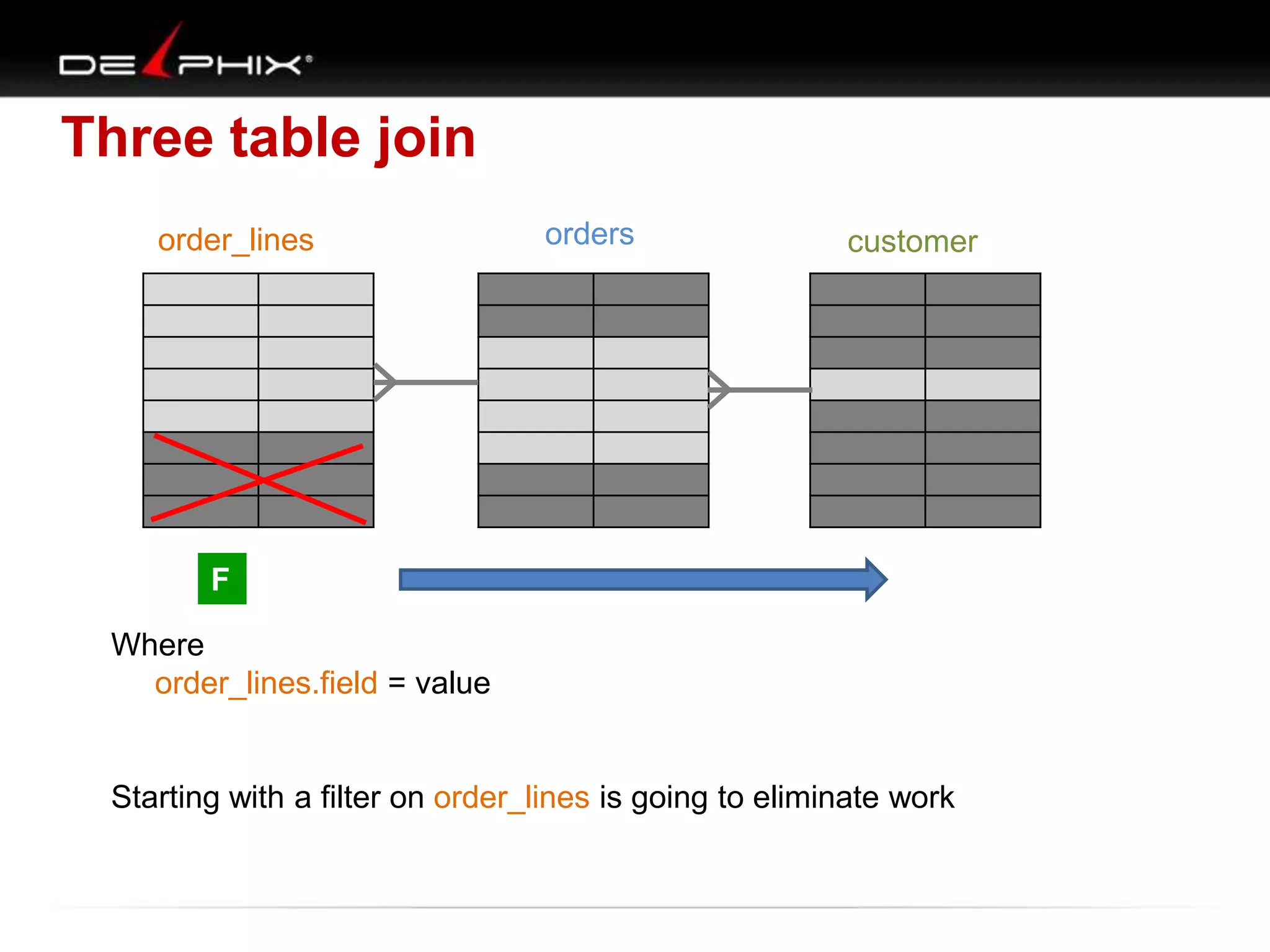
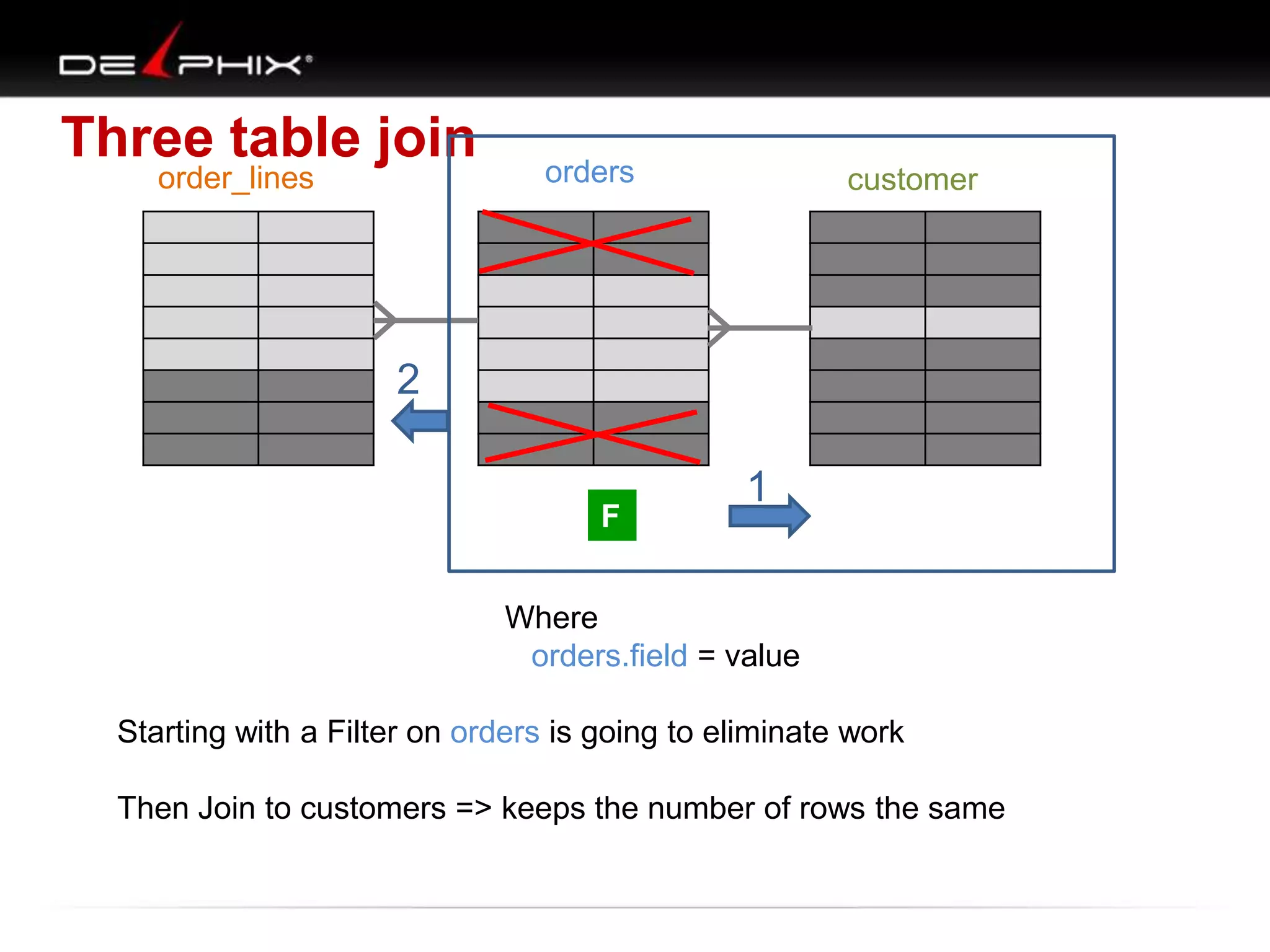
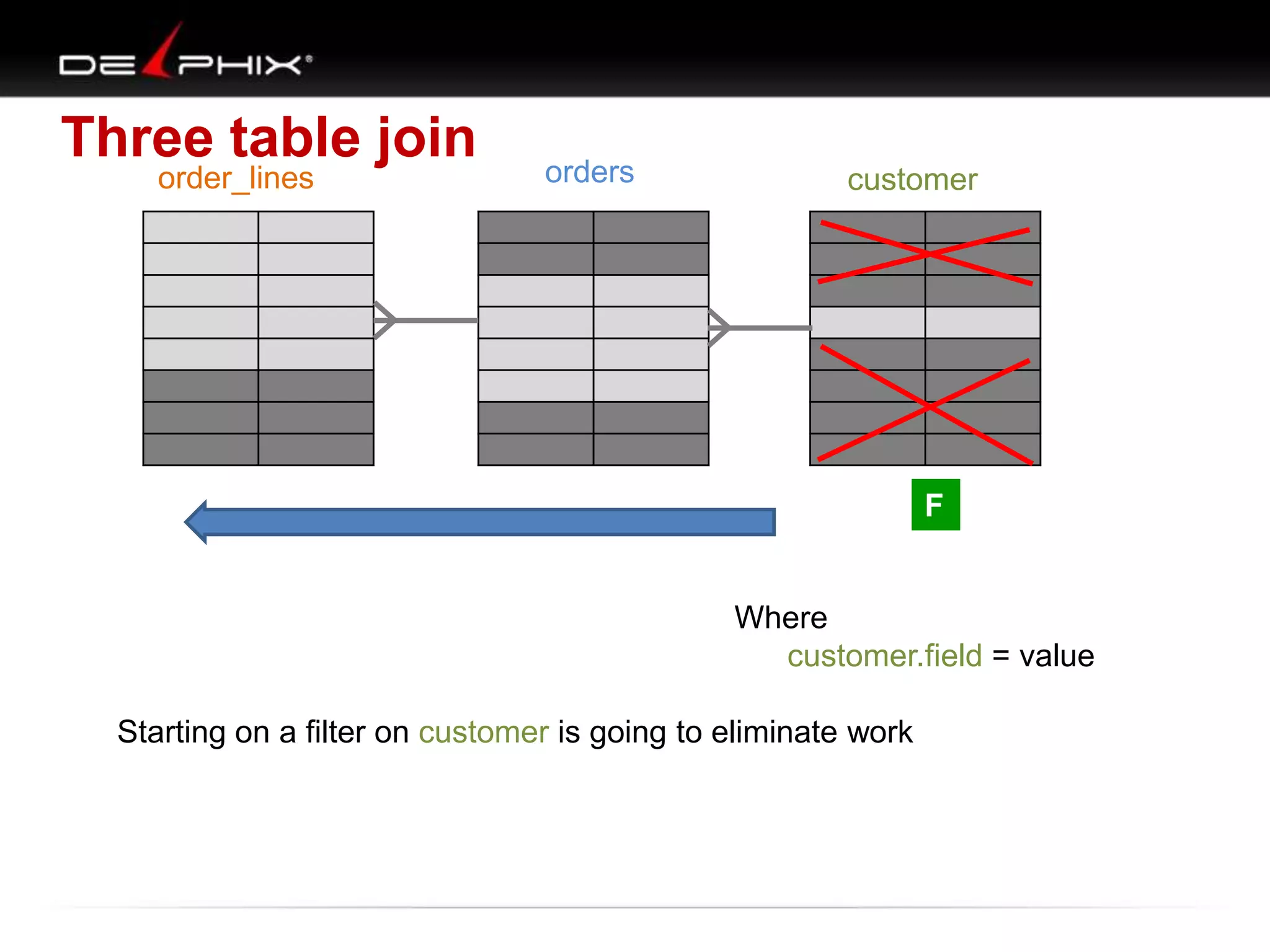
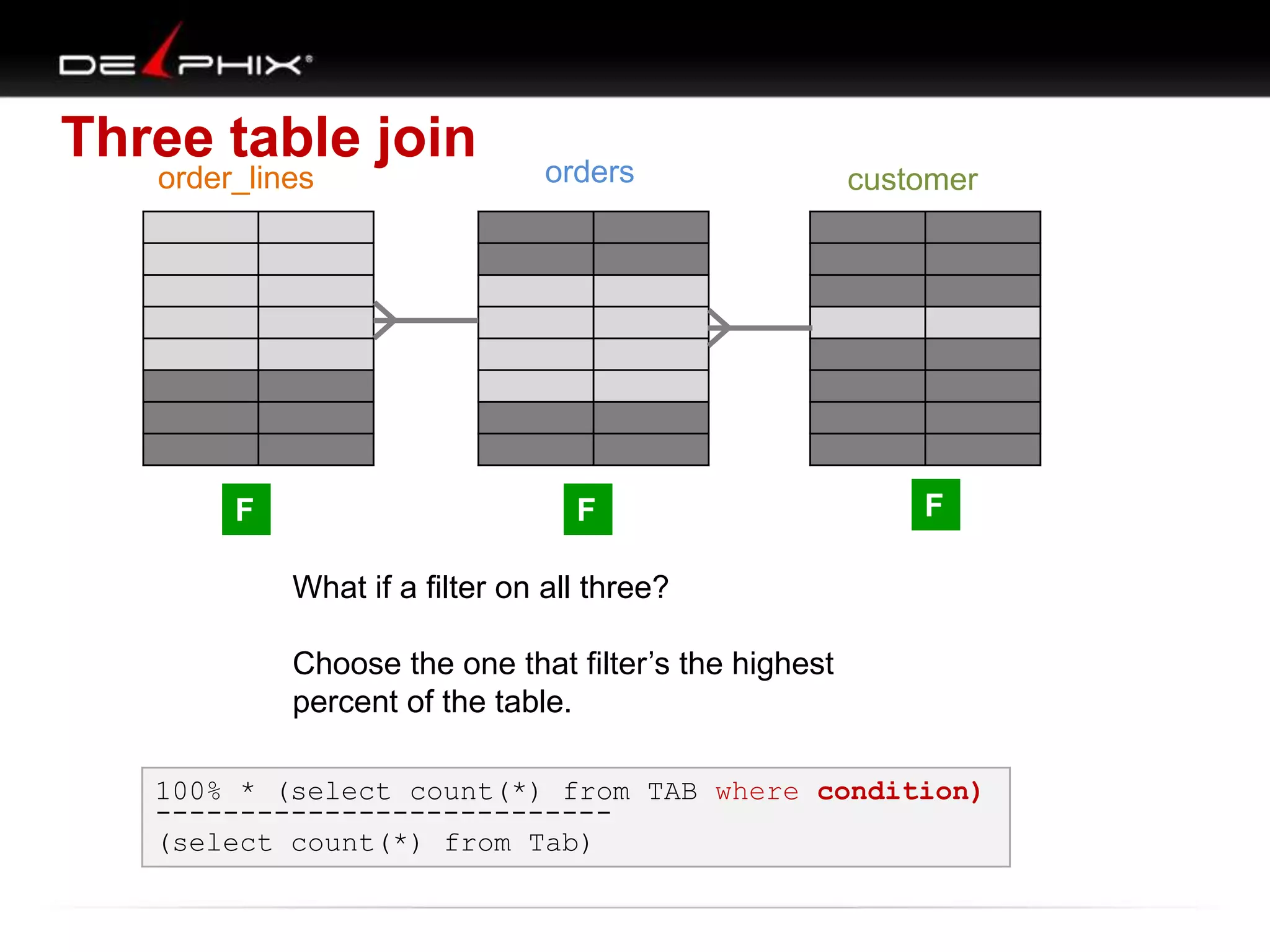
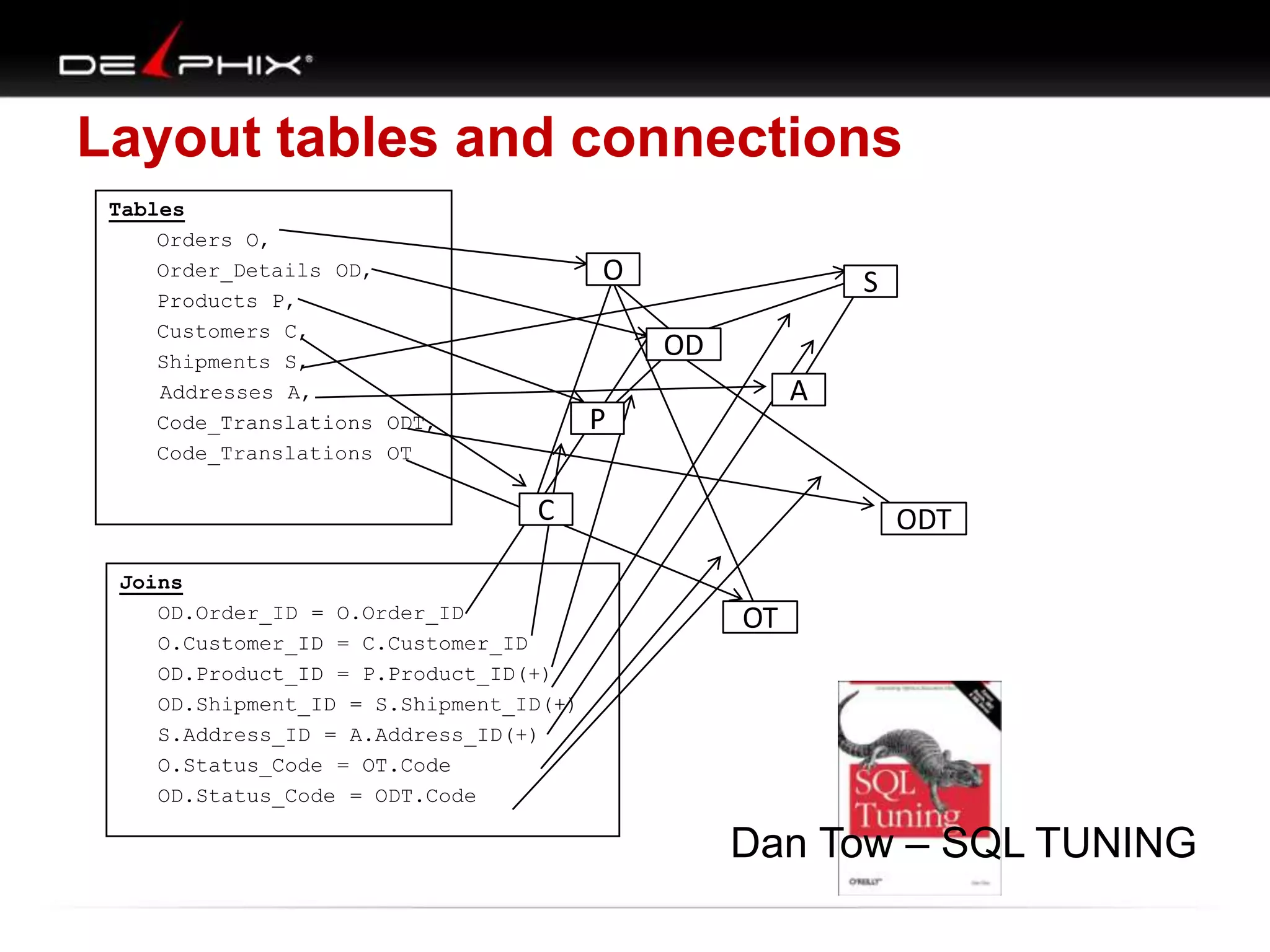
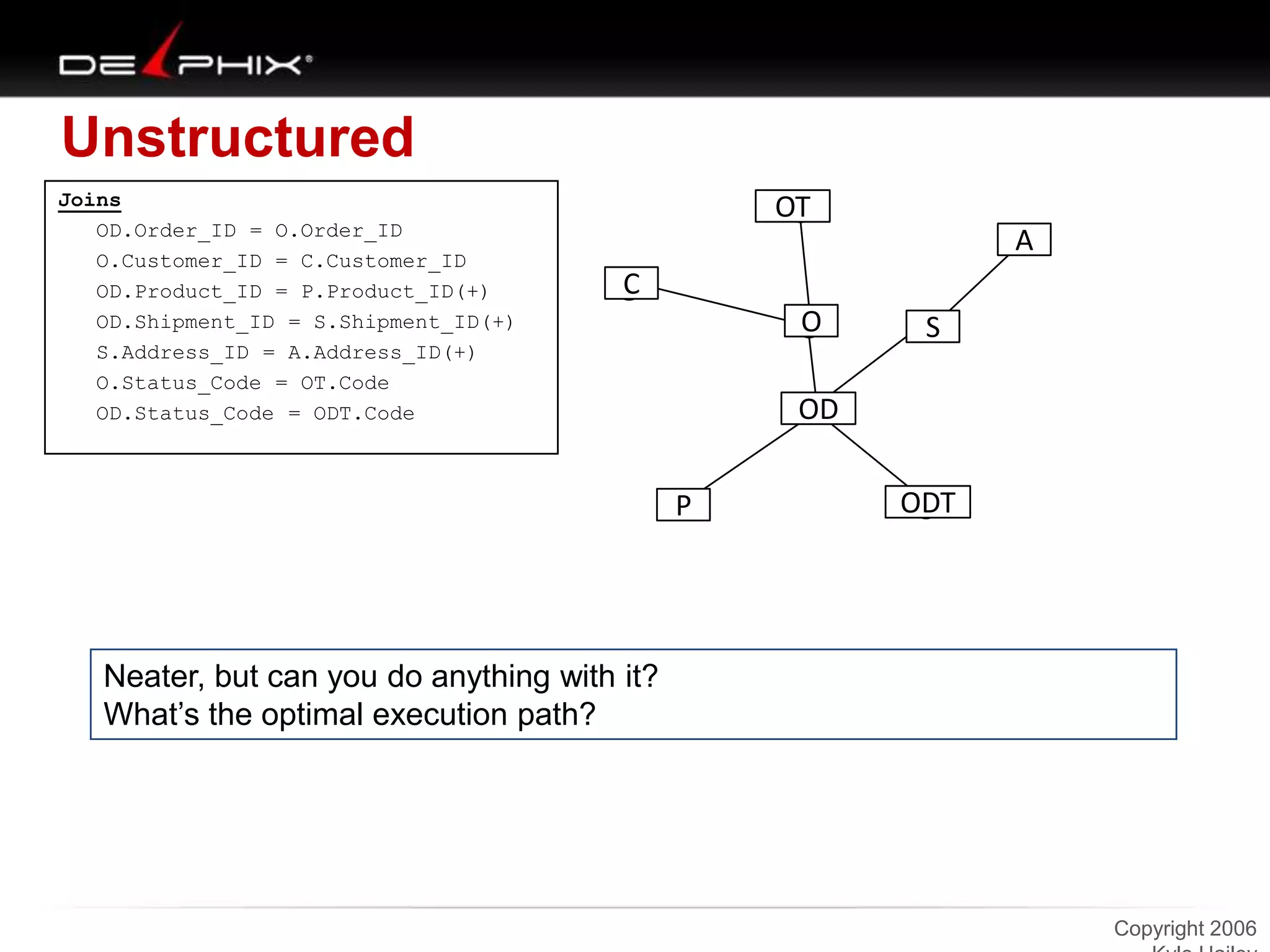
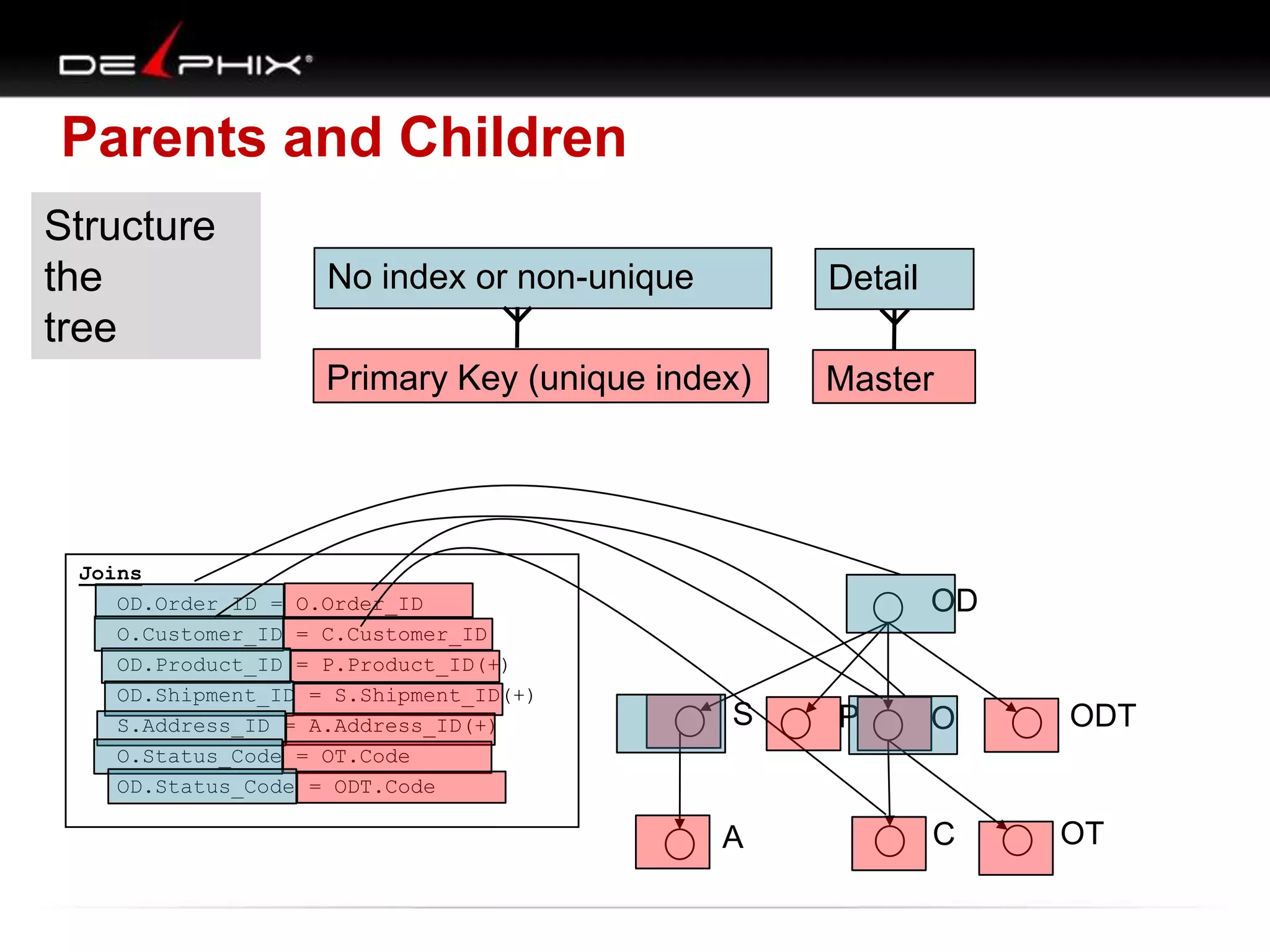
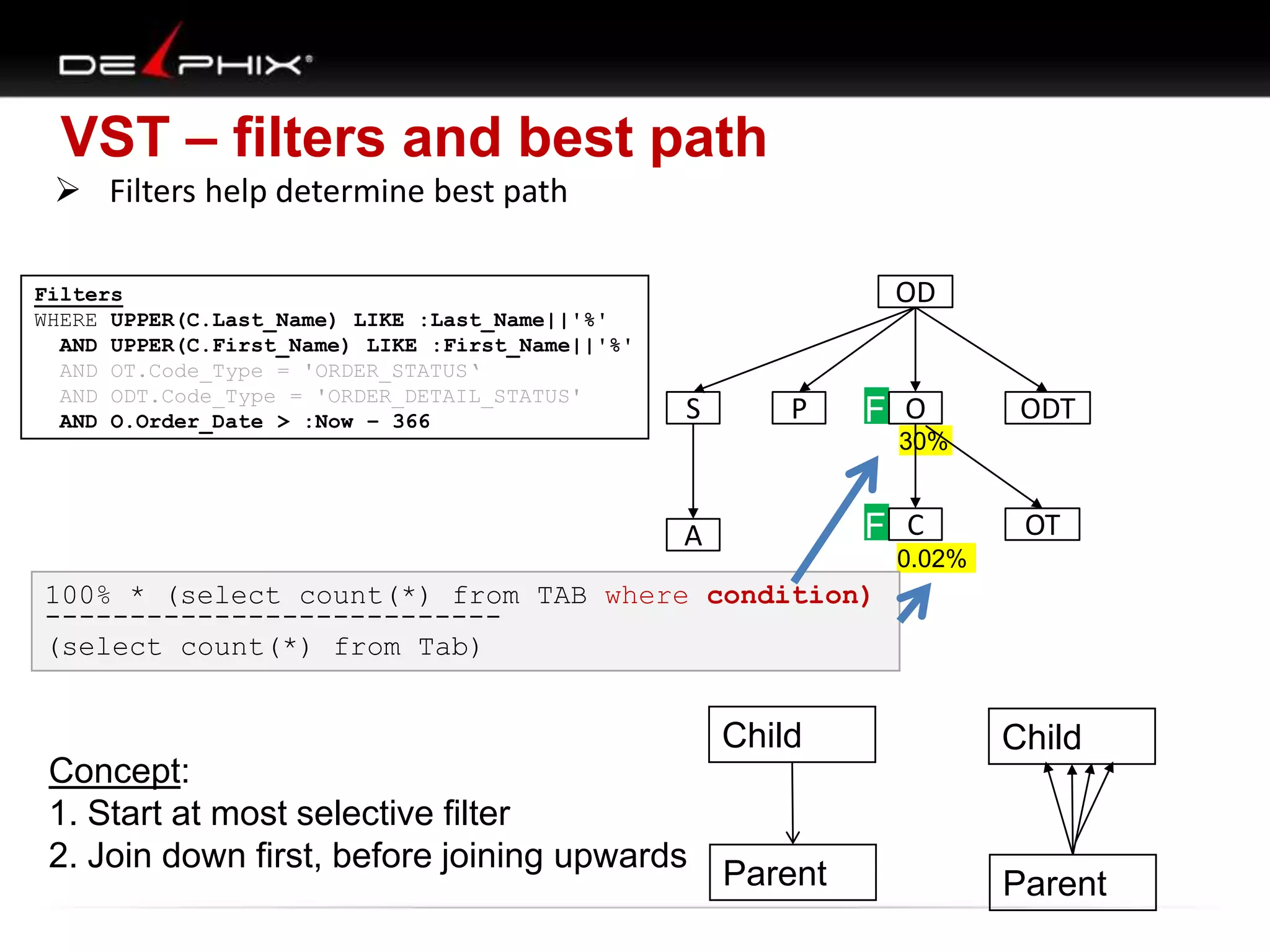
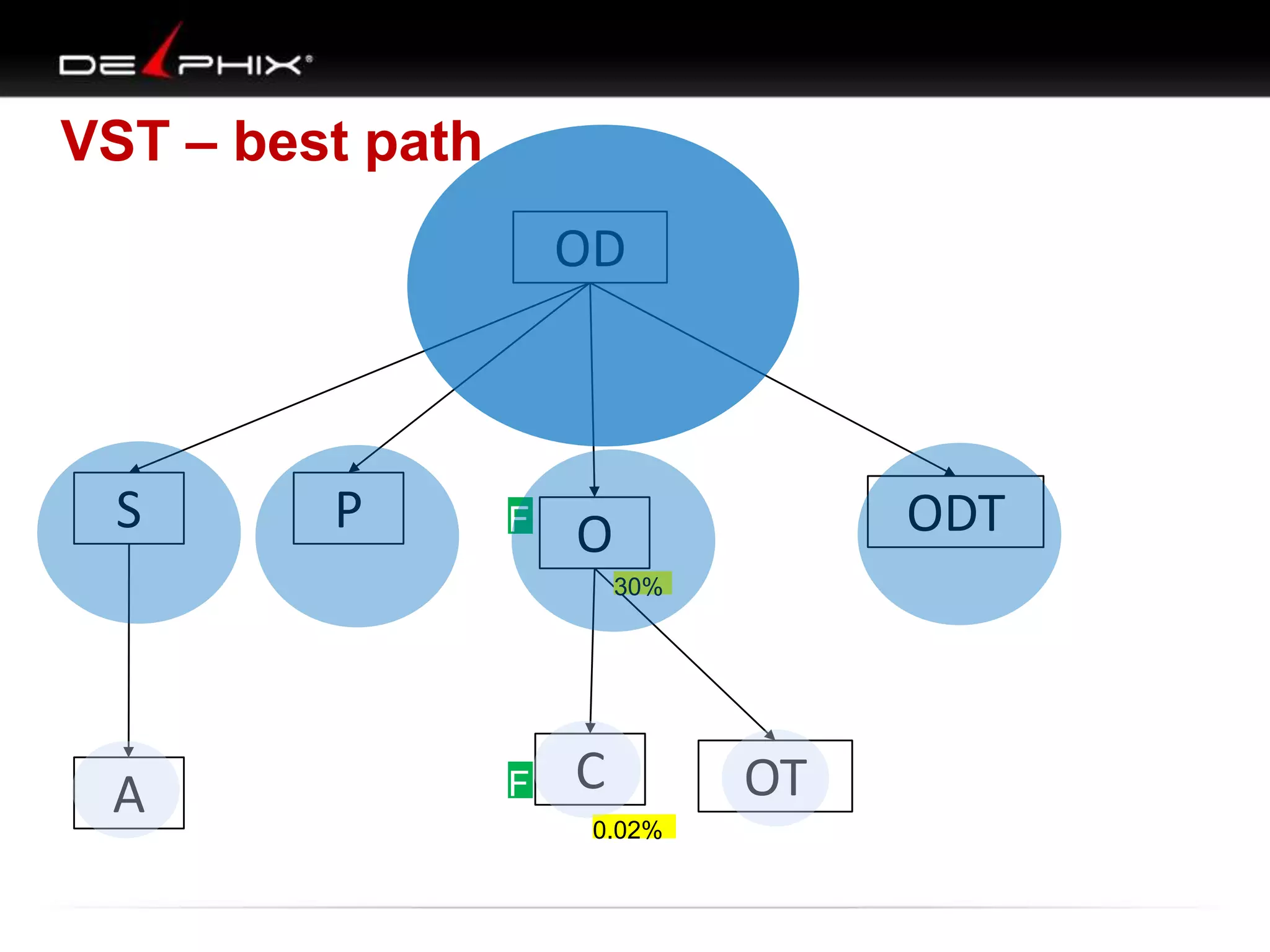
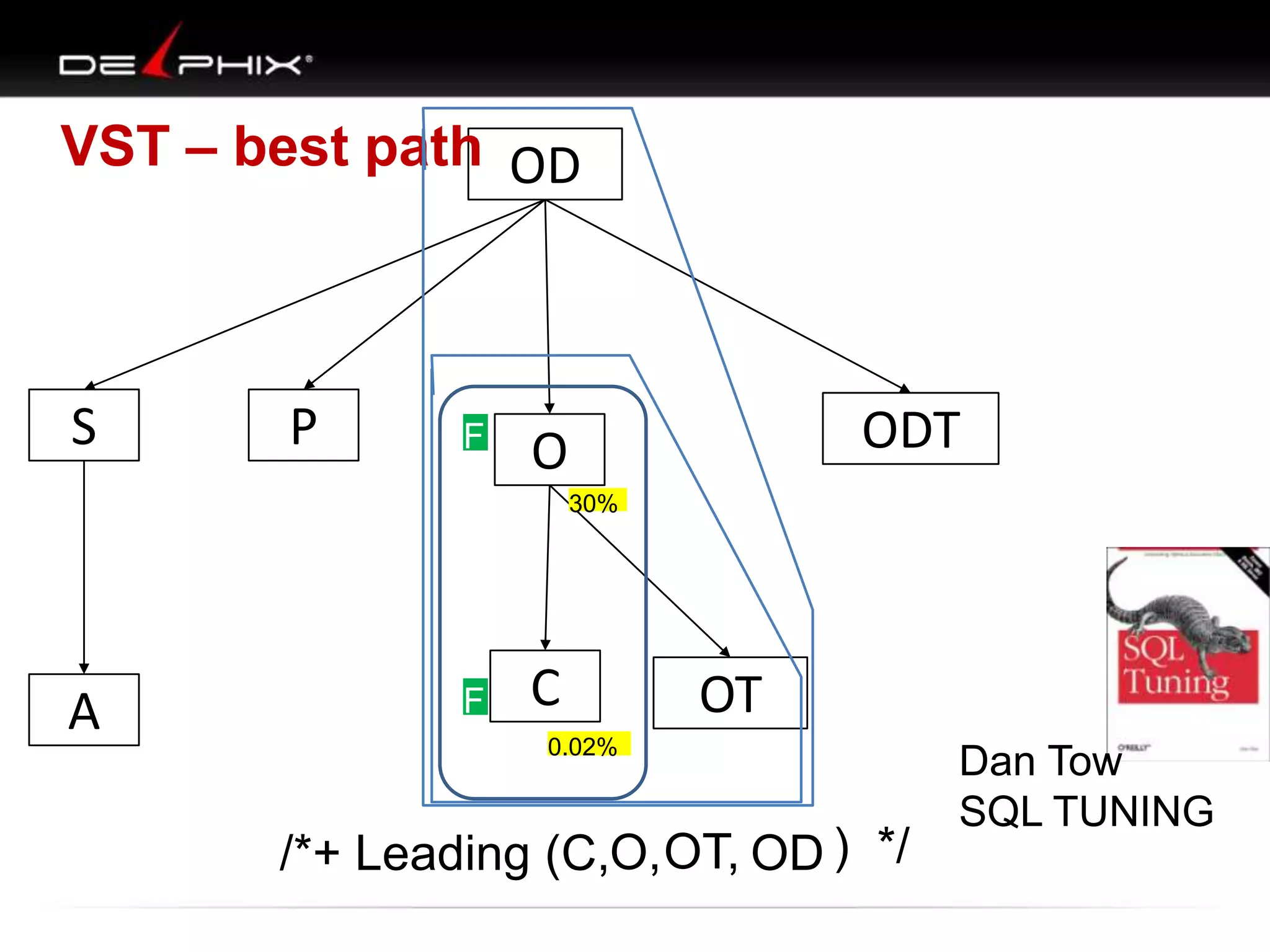
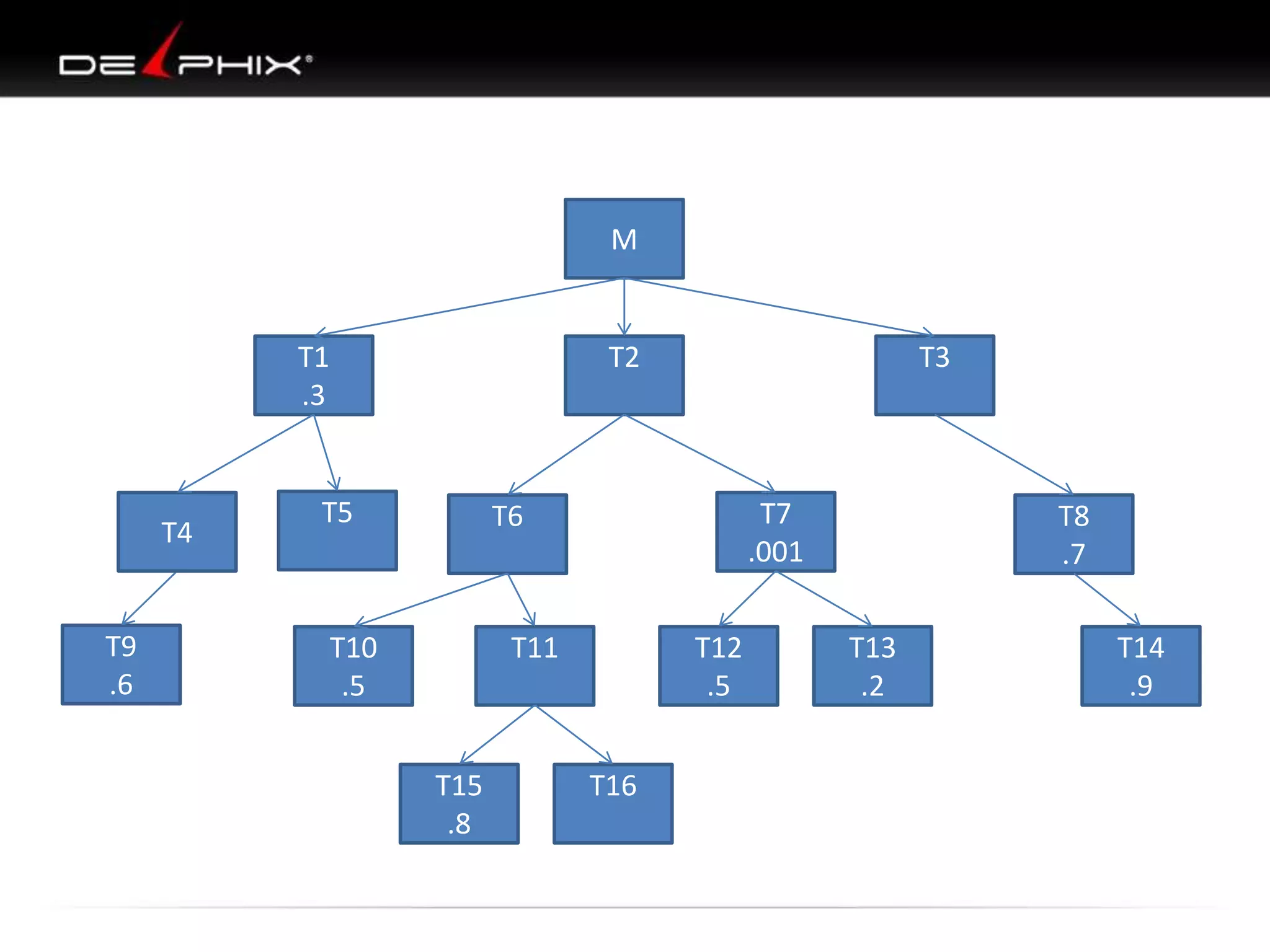
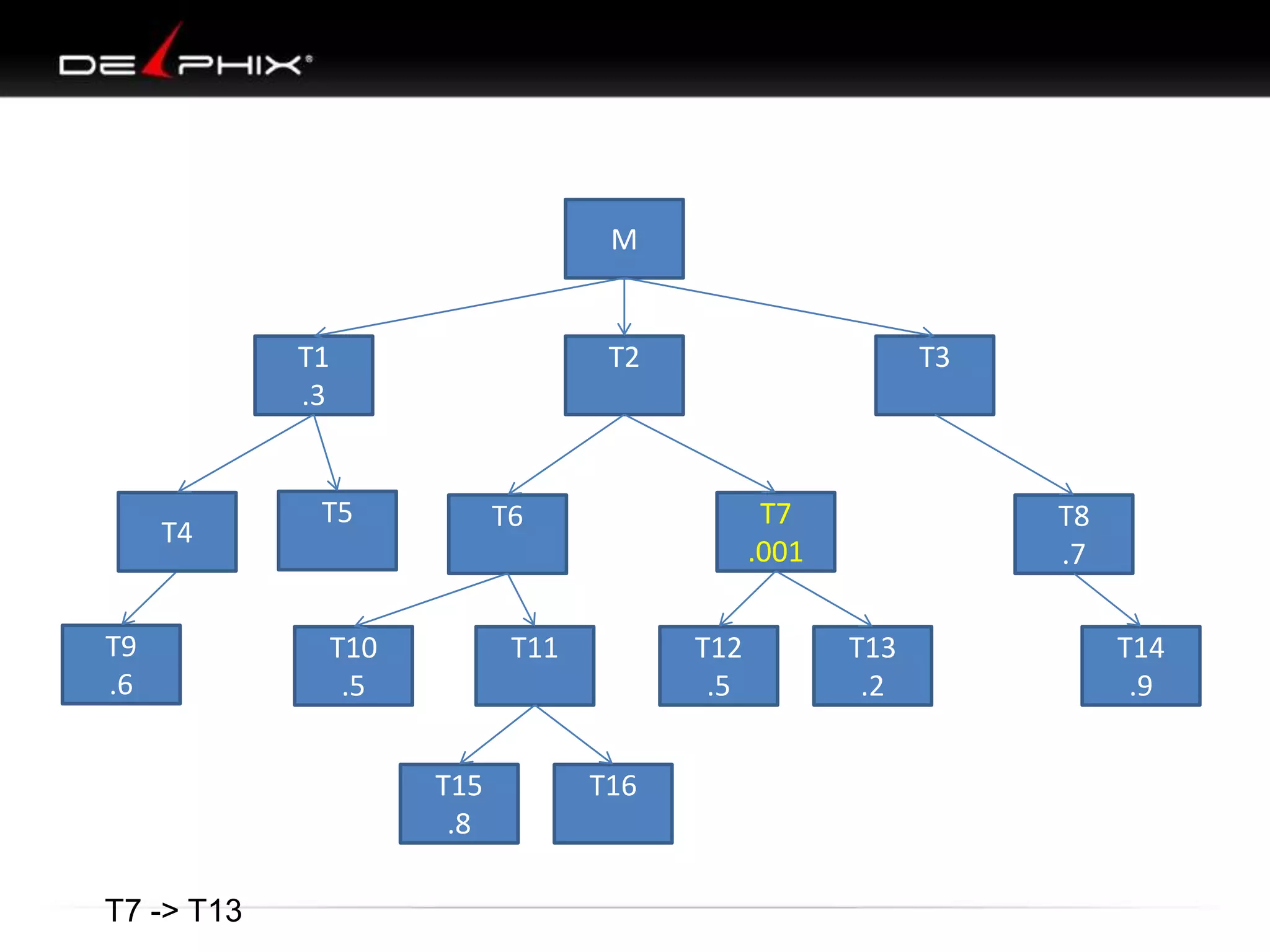
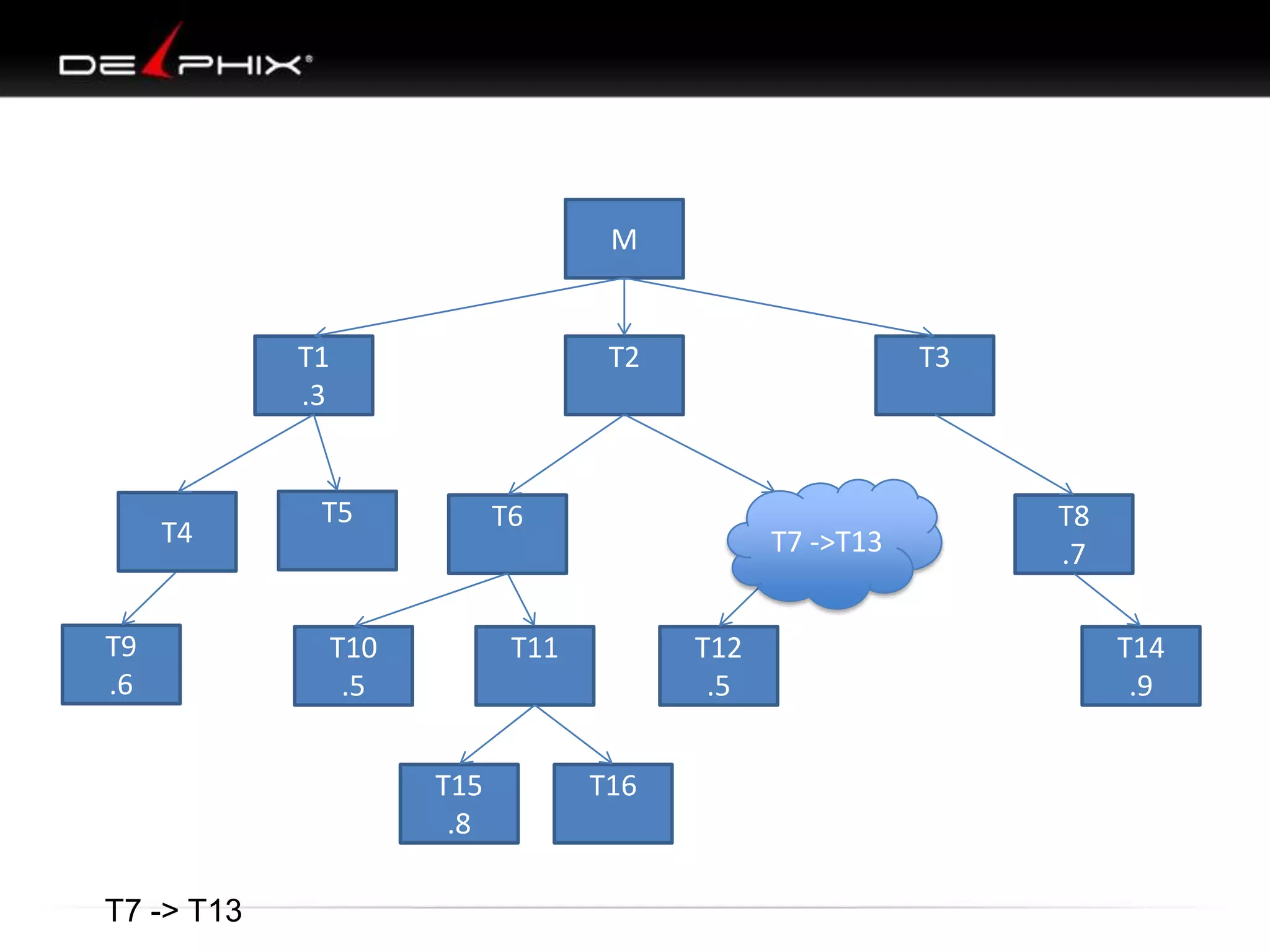
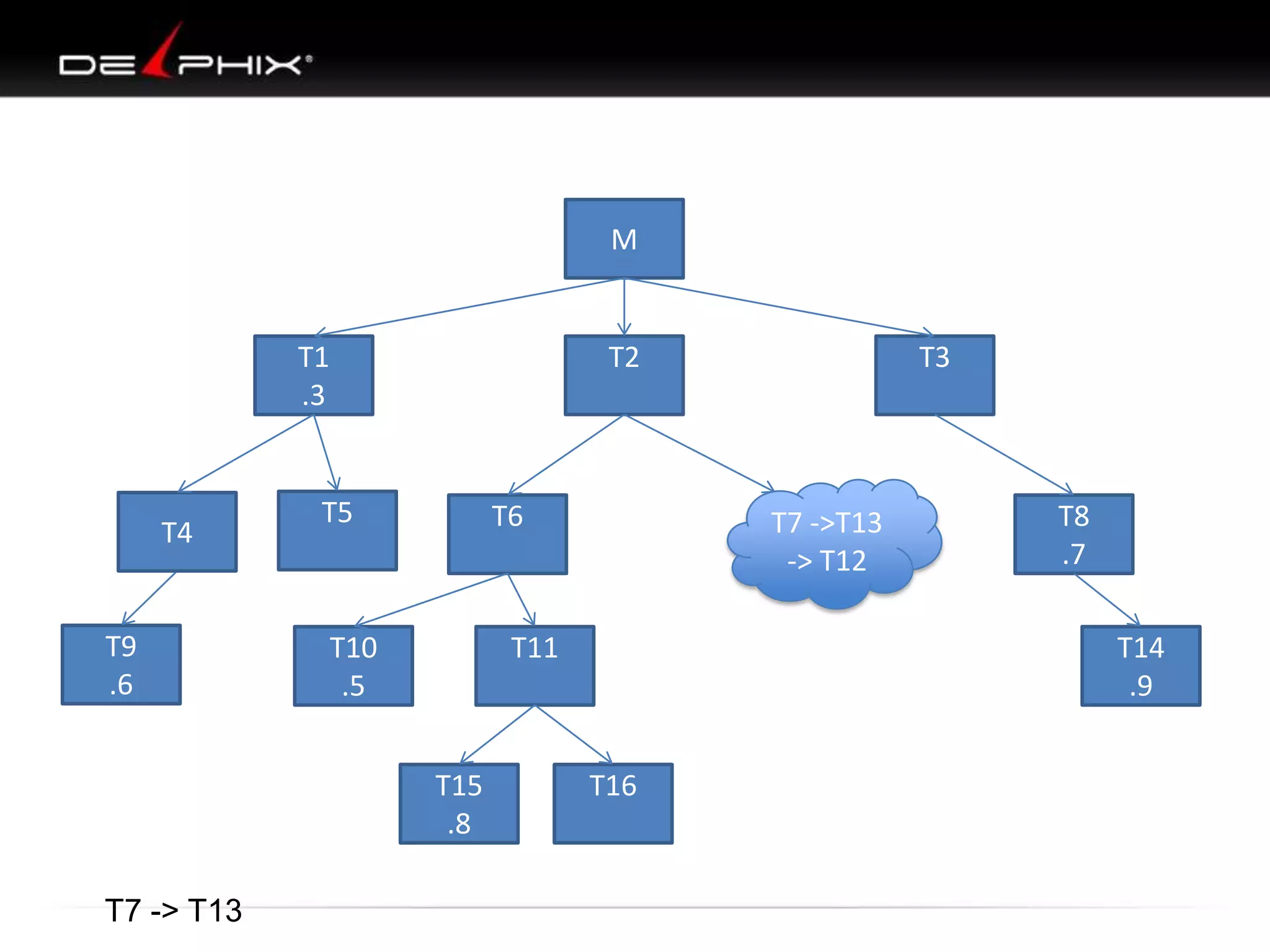
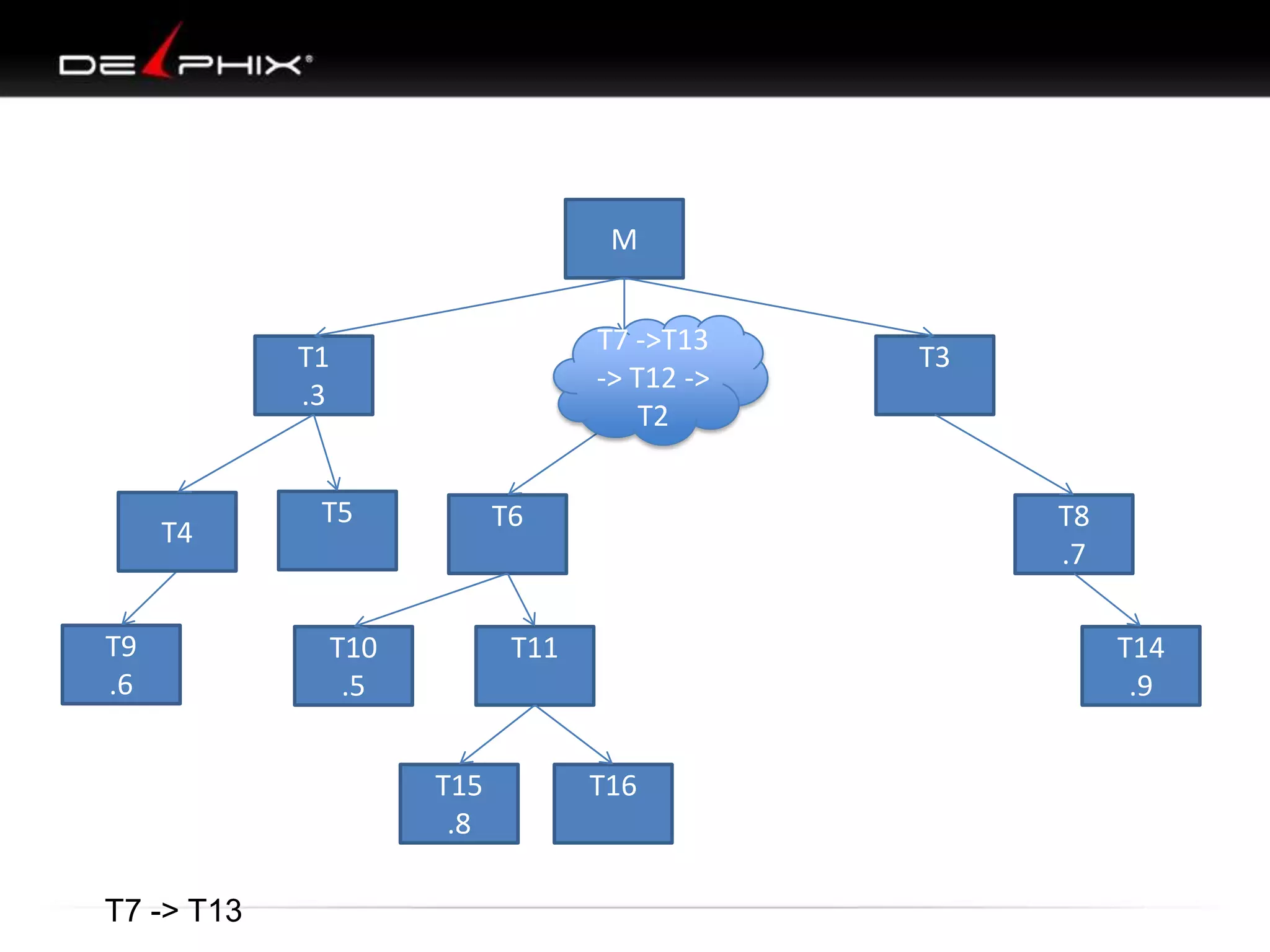
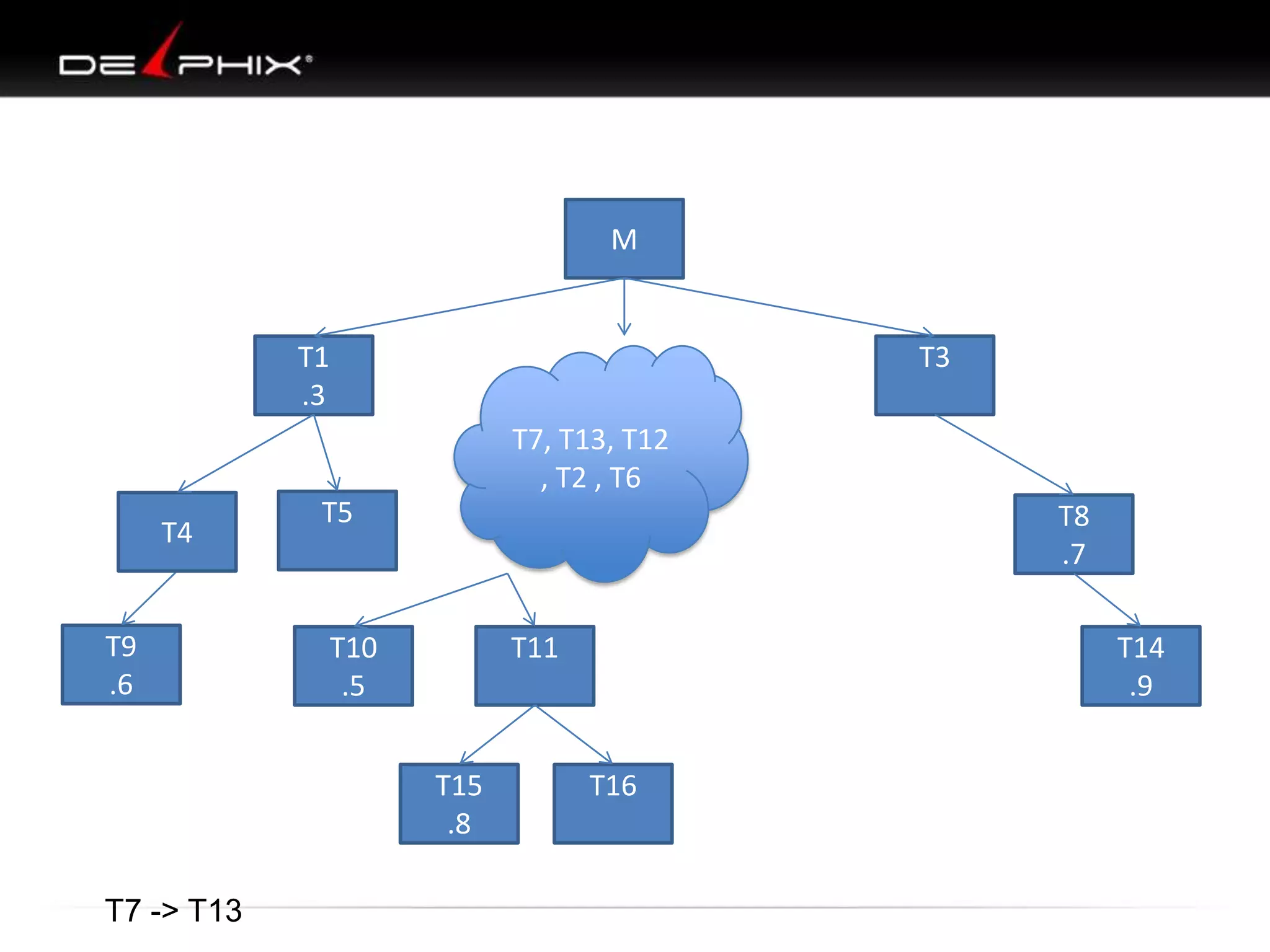
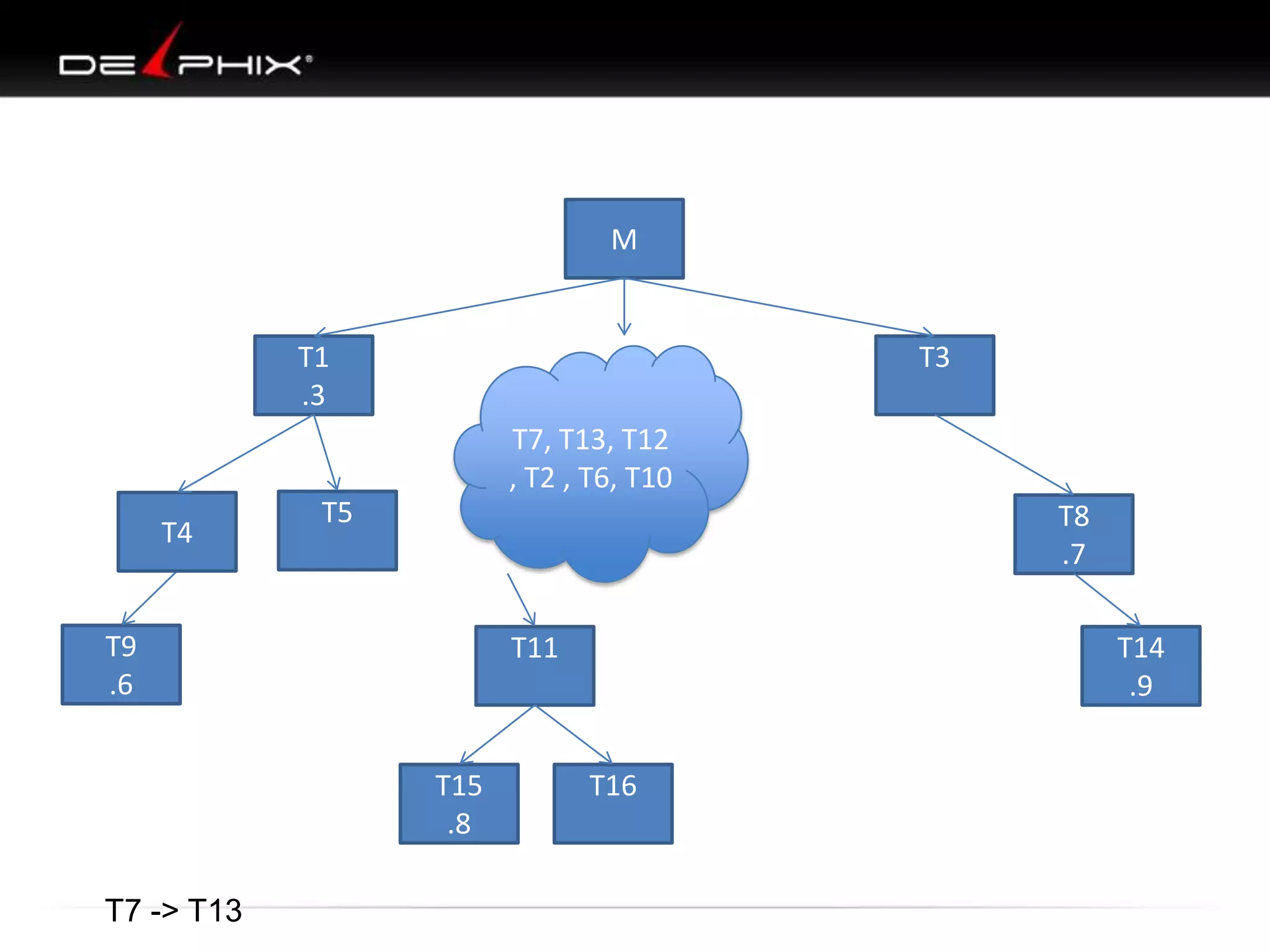
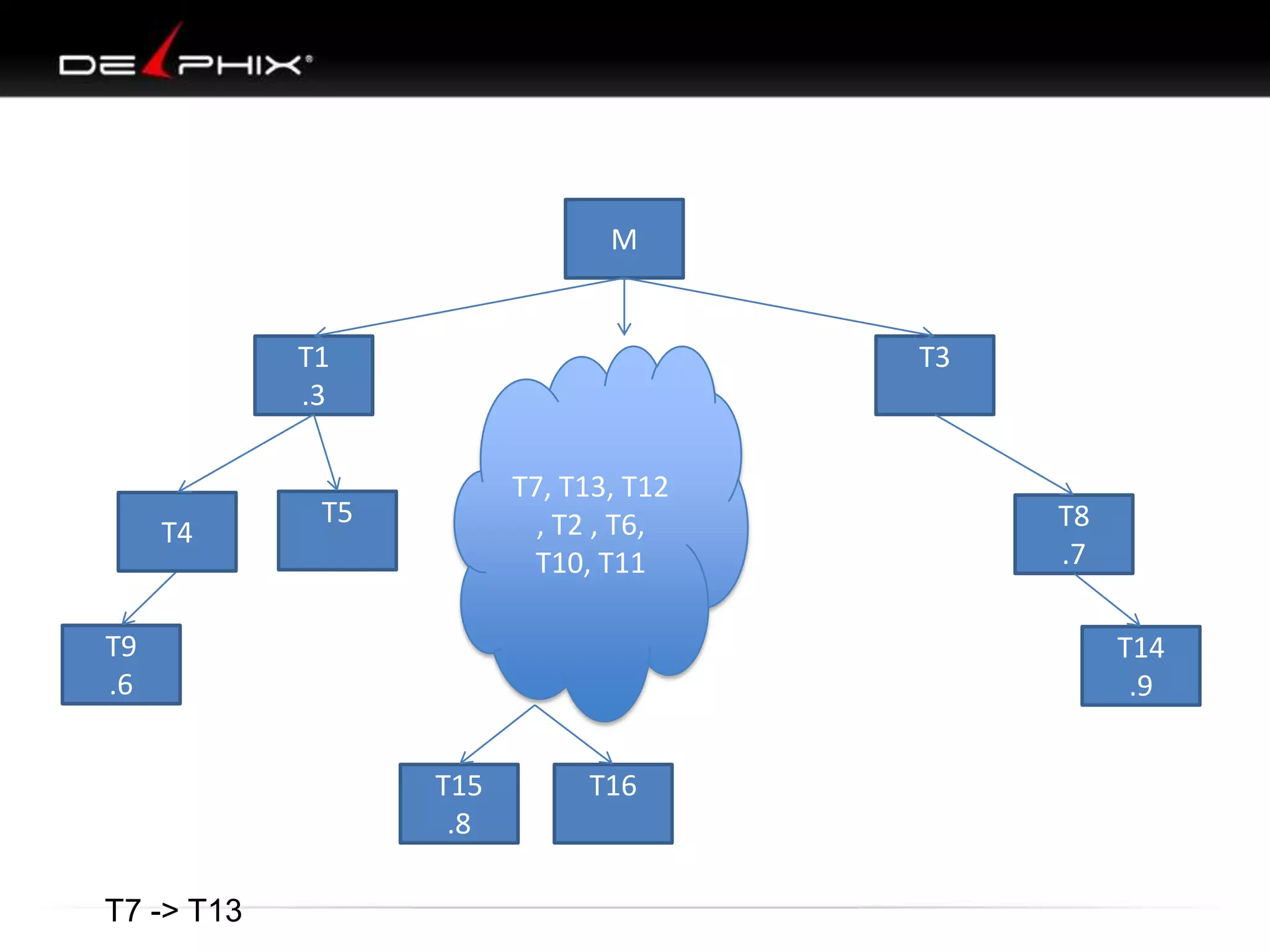
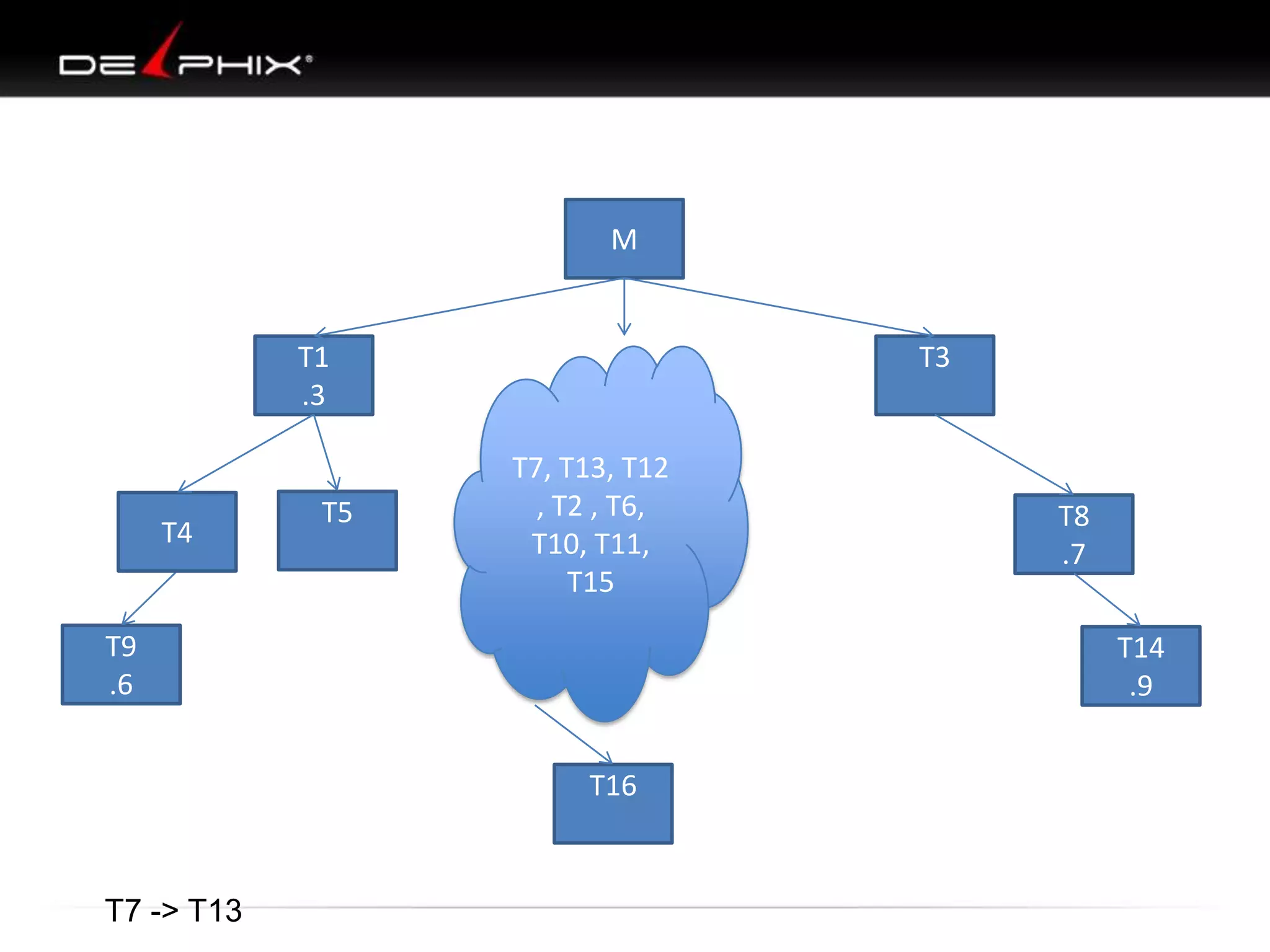
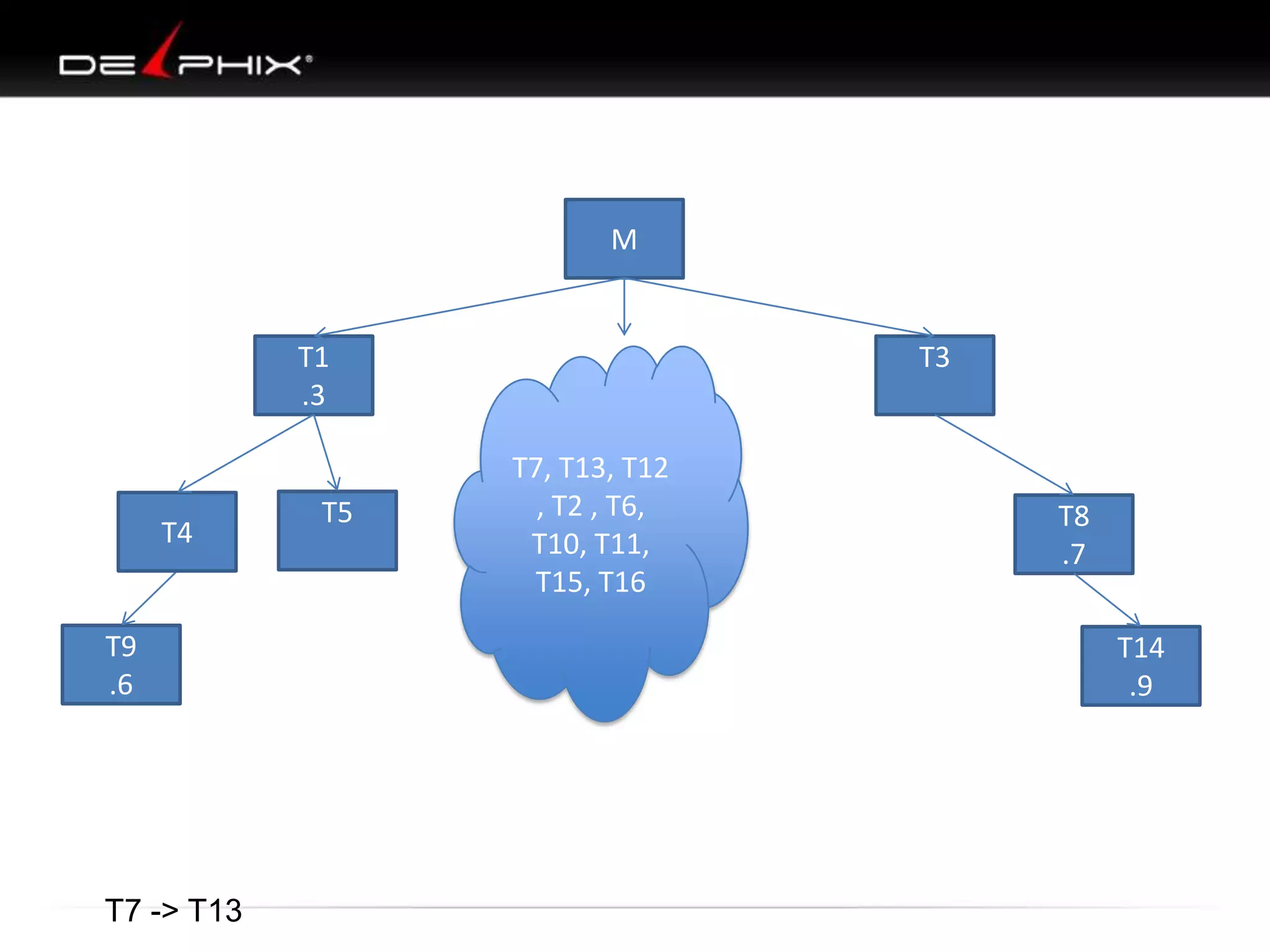
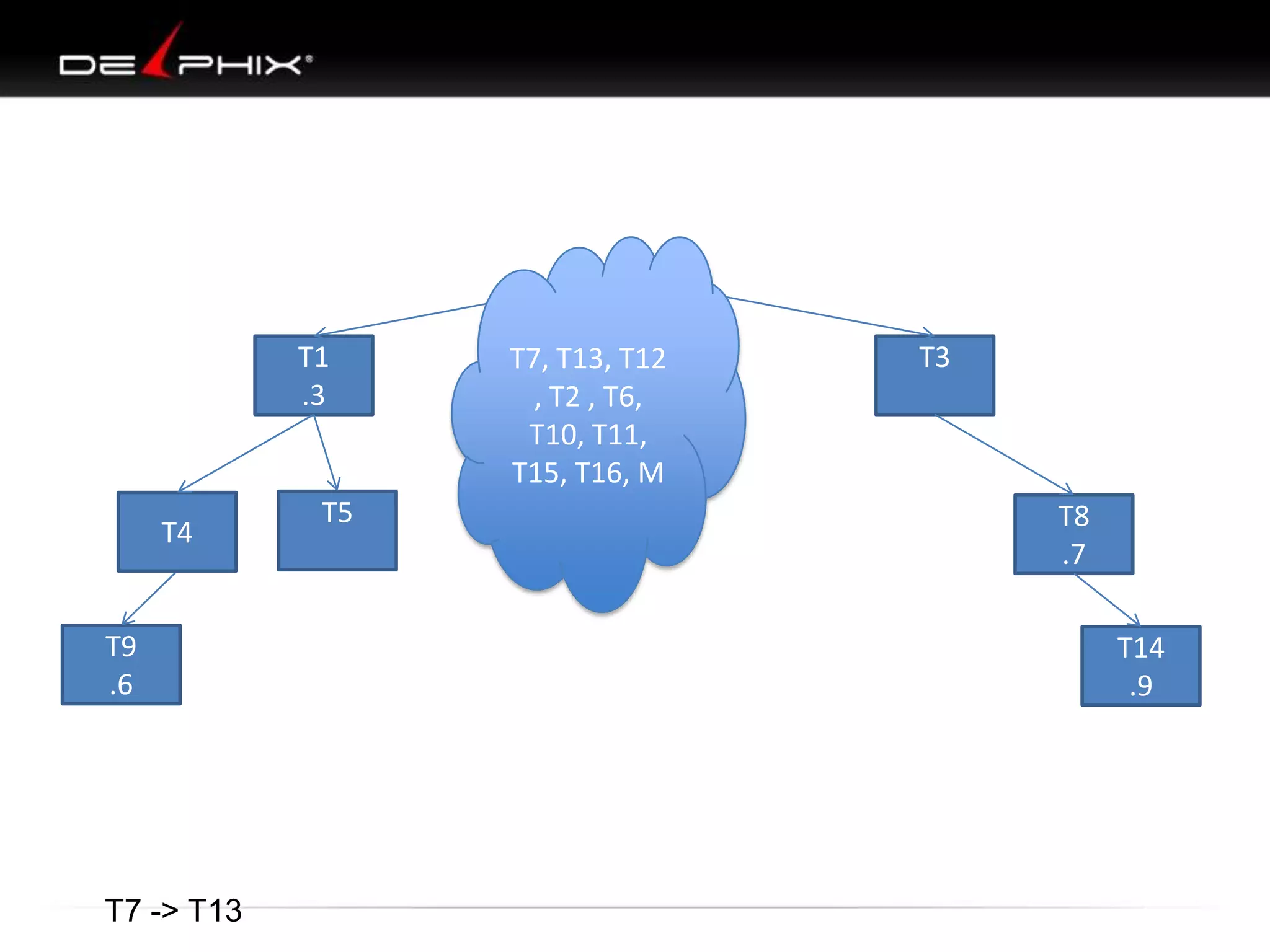
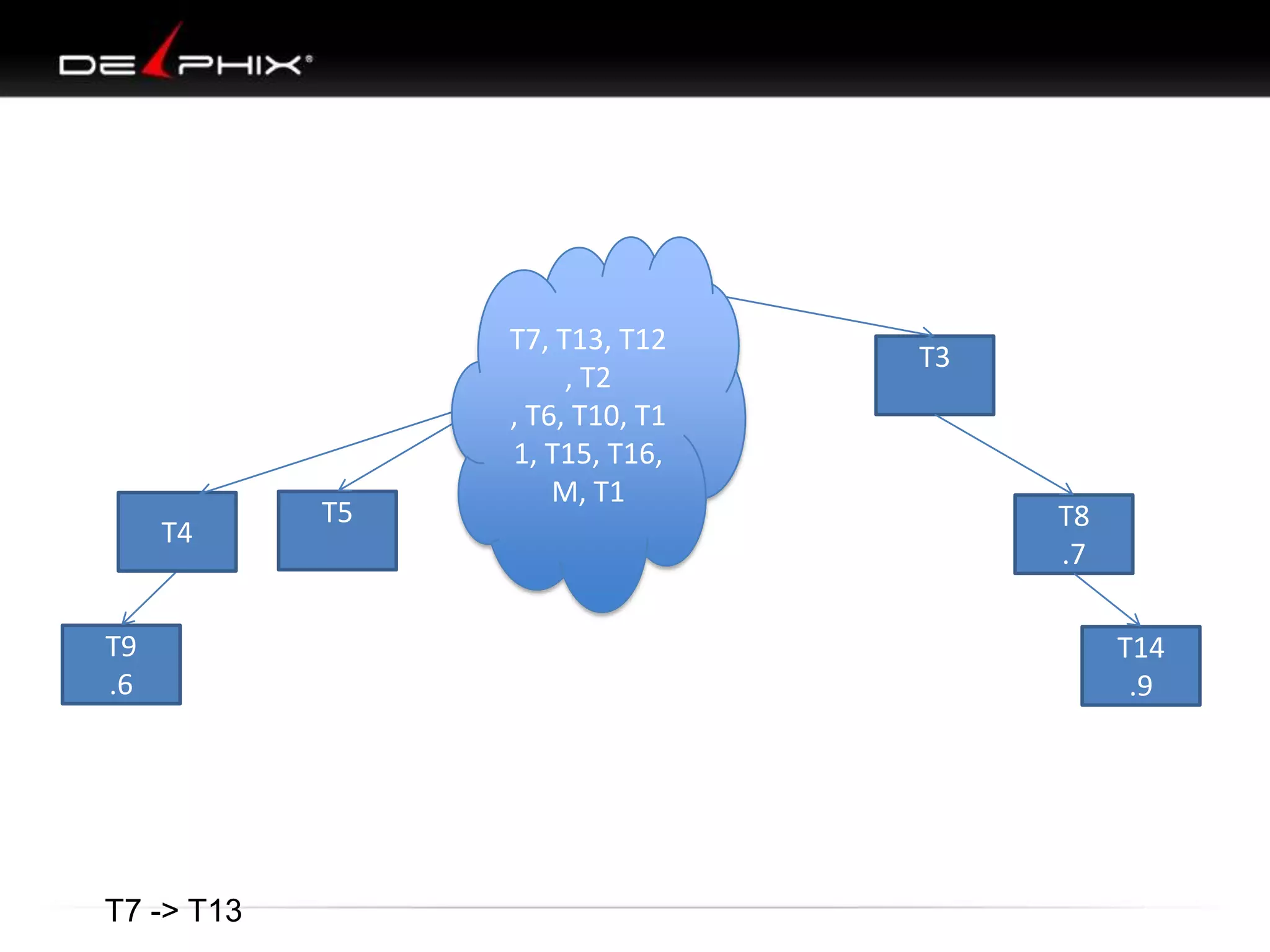
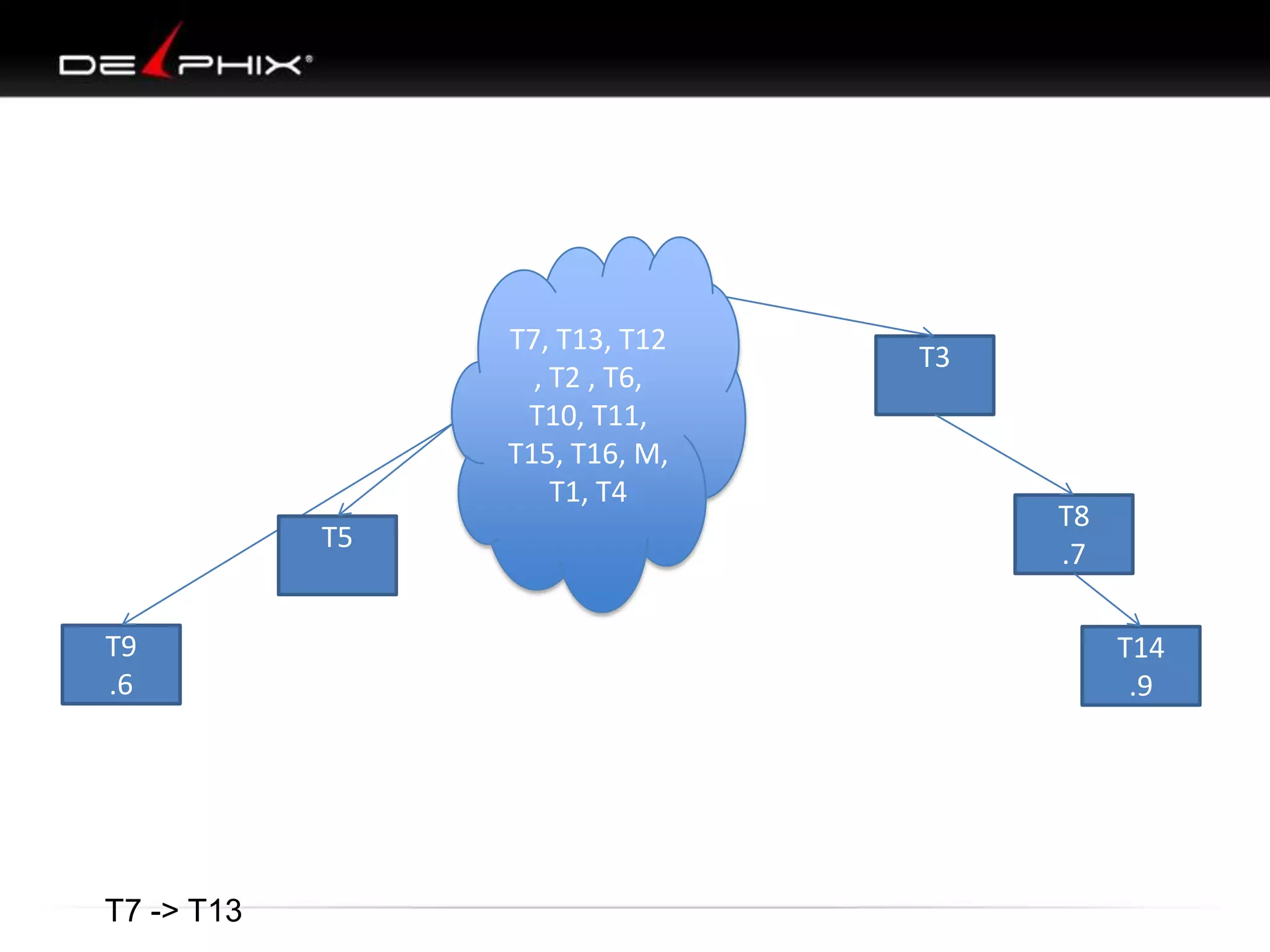
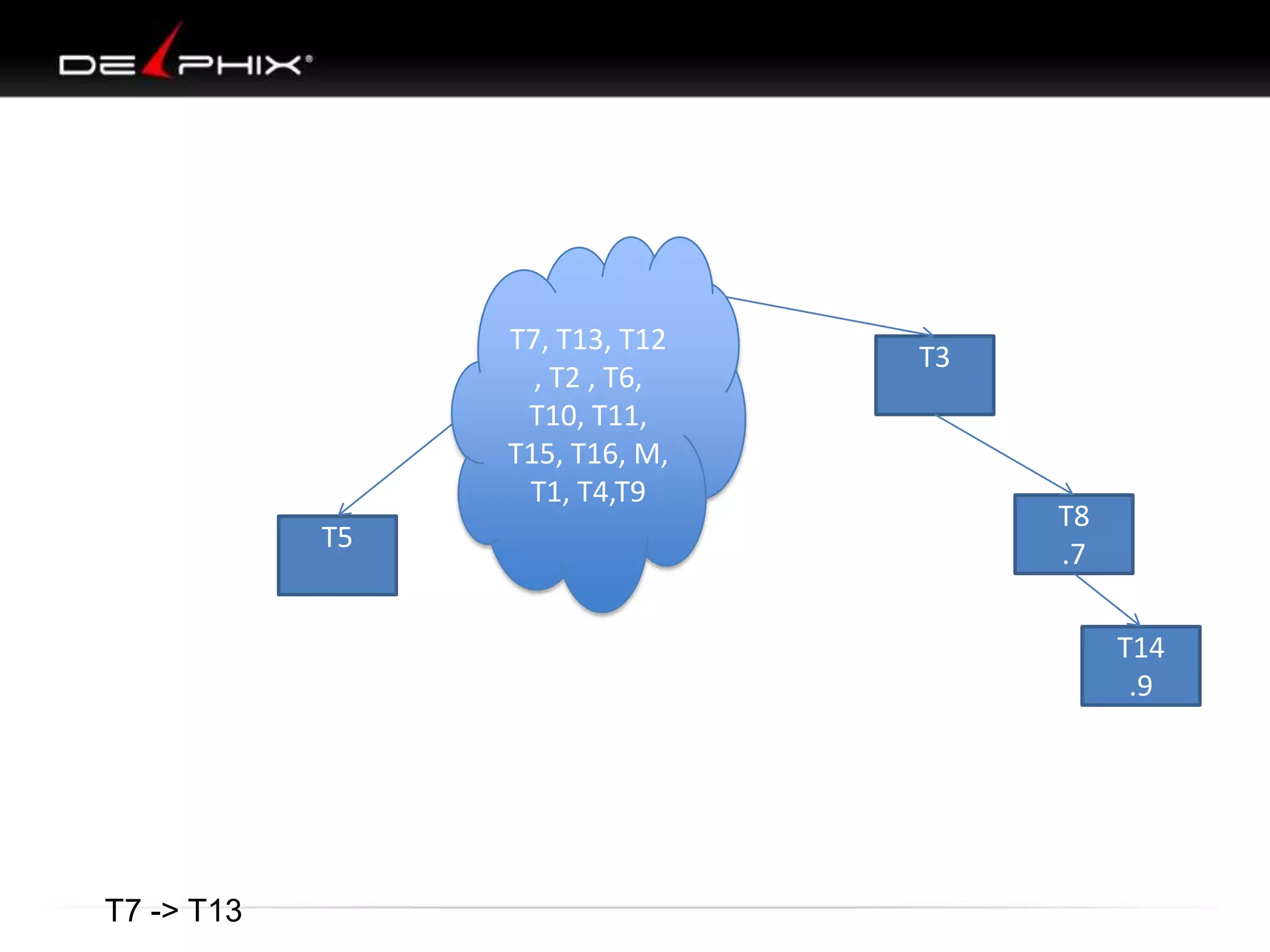
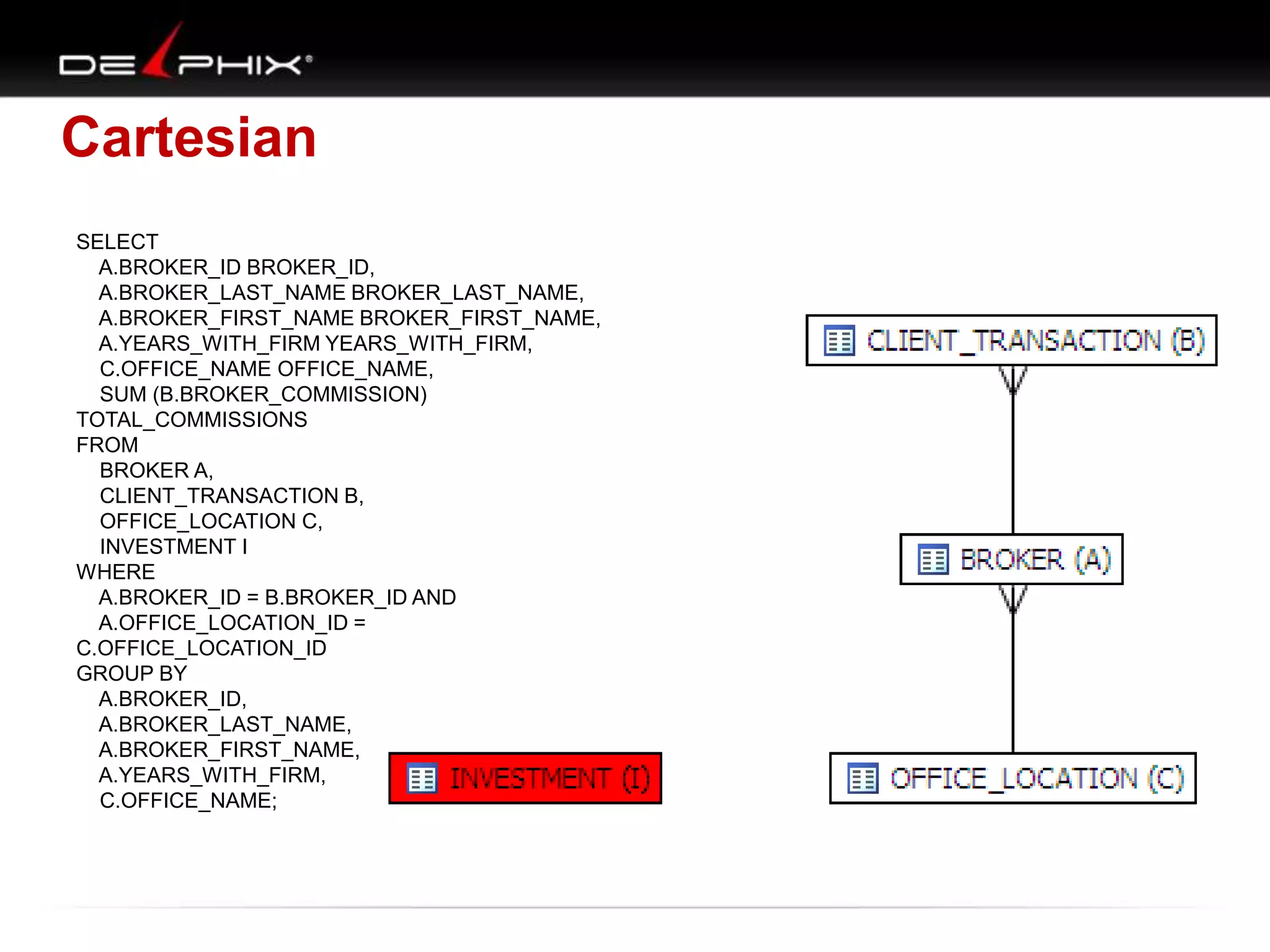
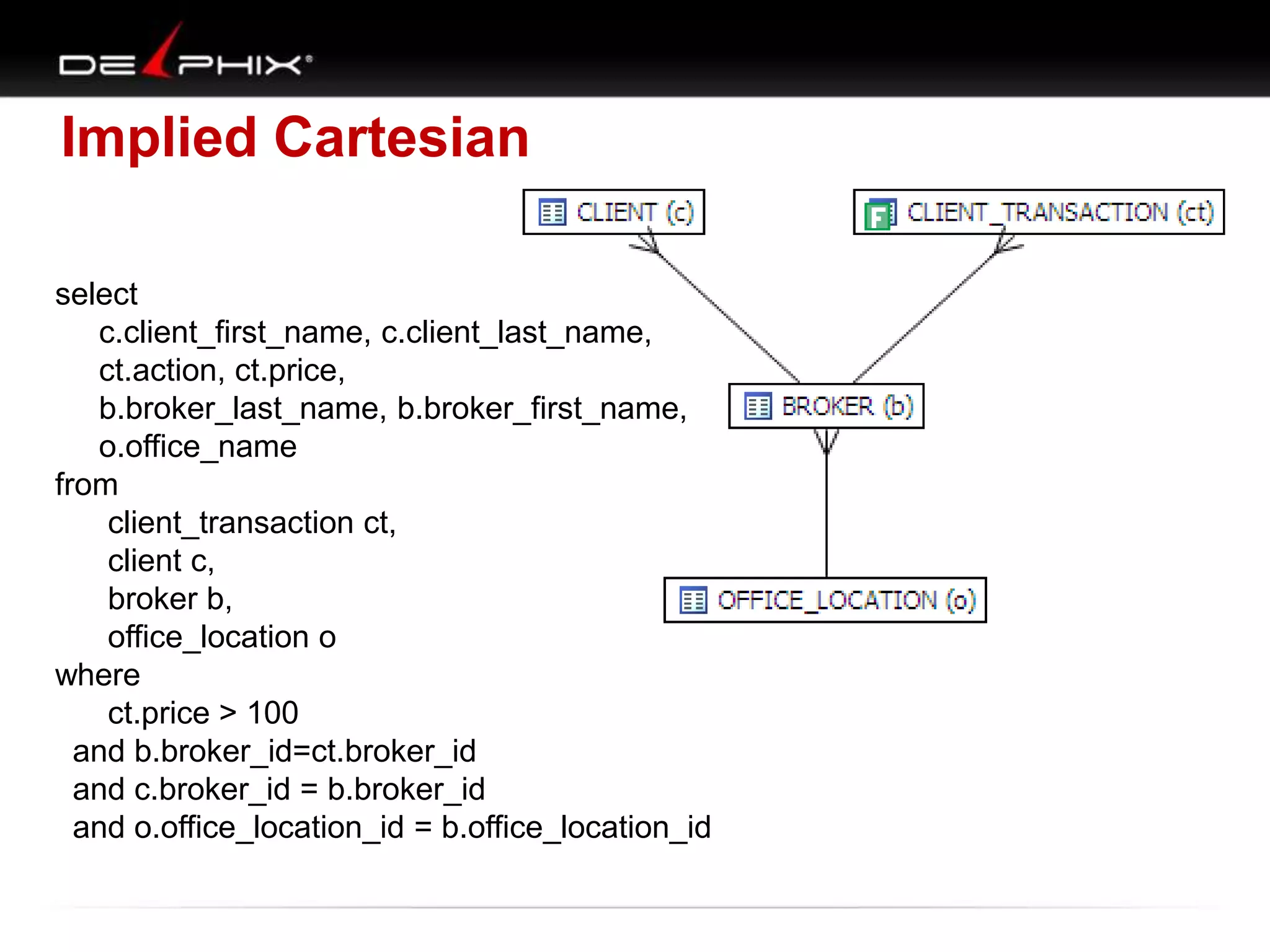
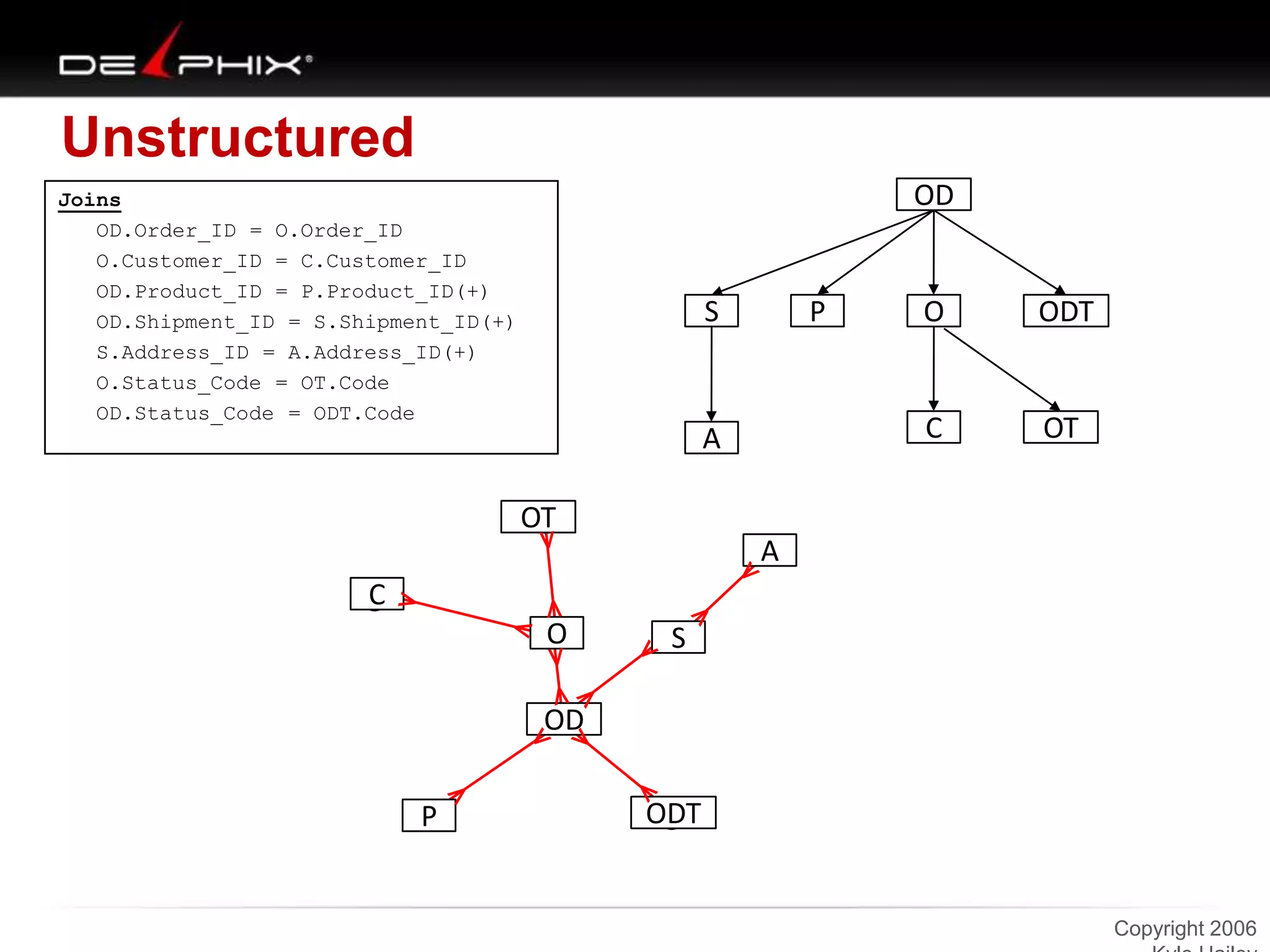
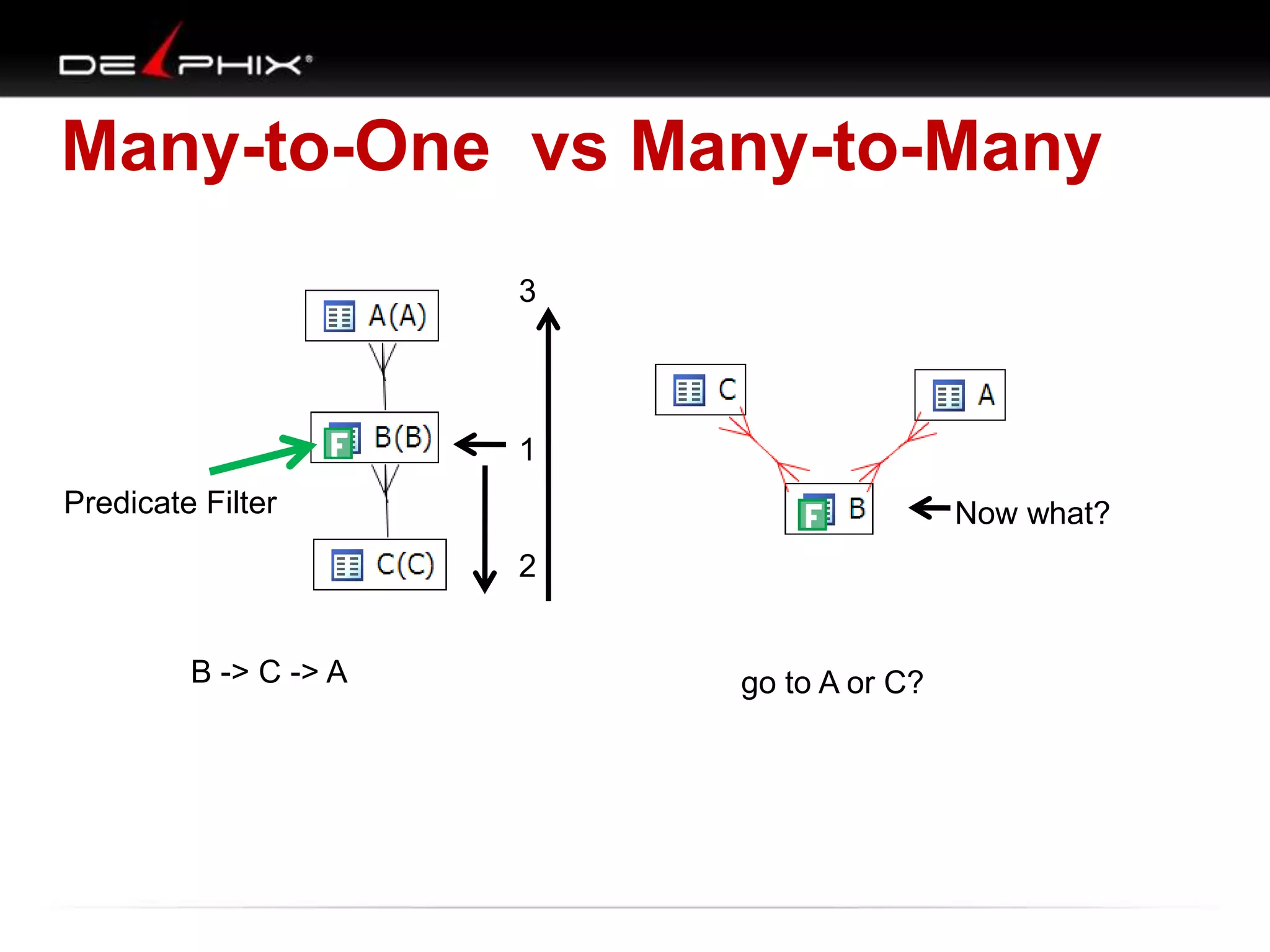
1. The document describes visual SQL tuning (VST) which involves finding problem SQL, studying the execution plan, and fixing issues. 2. It recommends laying out tables and joins visually with a map to determine the optimal execution path. Filters should be marked to start with the most selective one. 3. Drawing parents and children shows table relationships to structure the tree and determine the best join order from most selective filter down before joining back up.










































































![Oracle Open World 2014: Lies, Damned Lies, and I/O Statistics [ CON3671]](https://cdn.slidesharecdn.com/ss_thumbnails/thursday115ionfs-141107125307-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)





















