Downloaded 68 times






















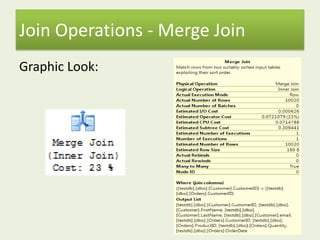

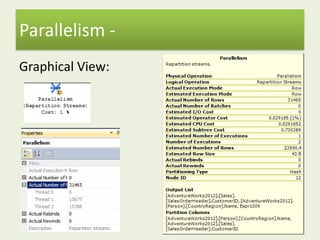




This document provides an introduction to execution plan analysis for performance tuning. It discusses dividing performance tuning into separate areas like hardware, disk performance, and other applications. It then focuses on execution plans, index operations like scans and seeks, join operations like hash and nested loop joins, and parallelism. The objectives are to understand additional execution plan tools, index best practices, join types, and when parallelism is beneficial or not.





























































