Downloaded 43 times






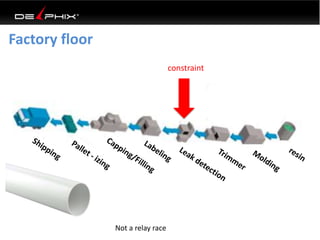

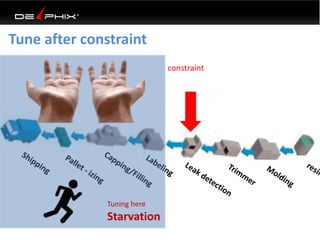





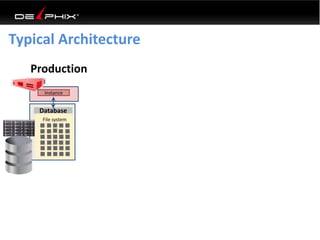

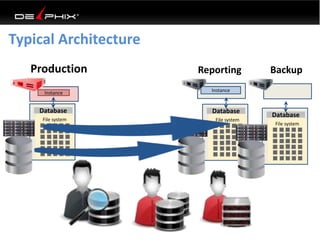
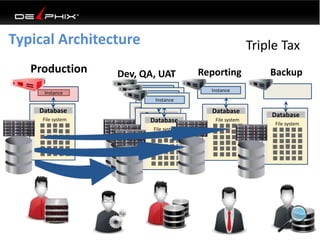
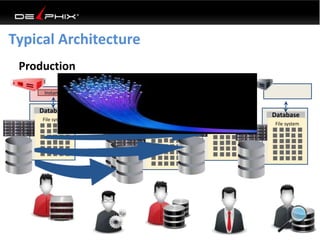
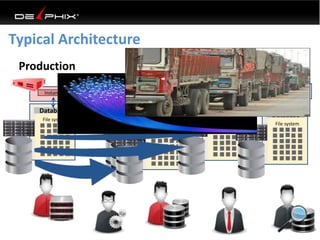
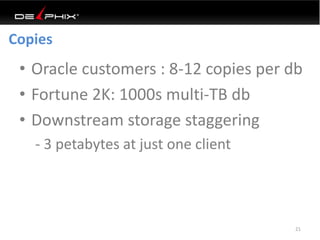









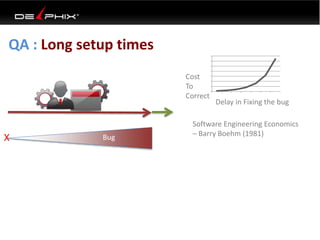



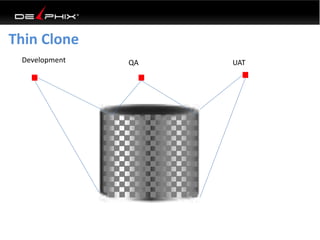

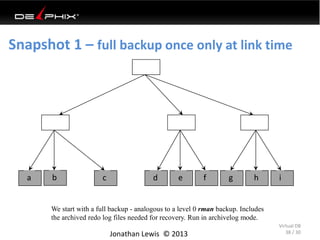
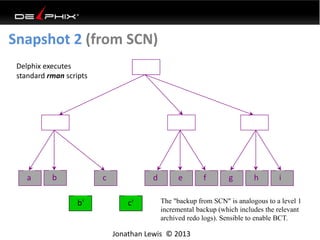
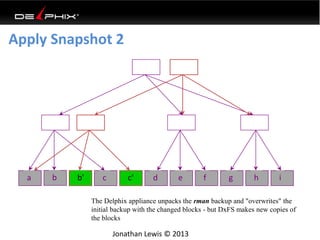
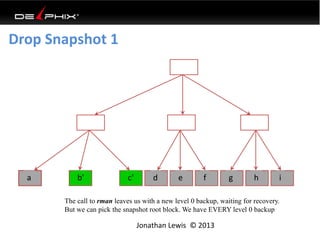
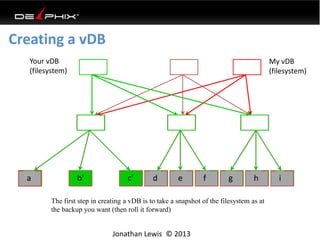
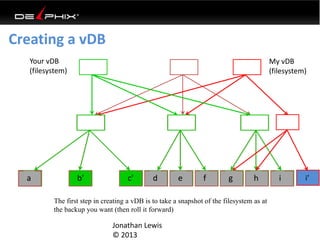

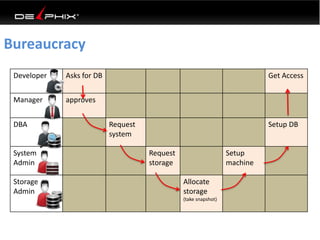
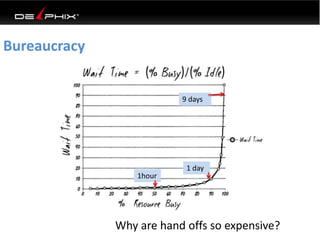
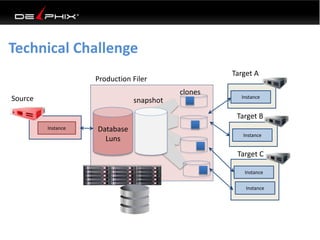
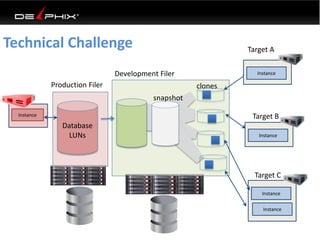


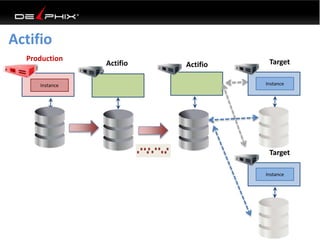
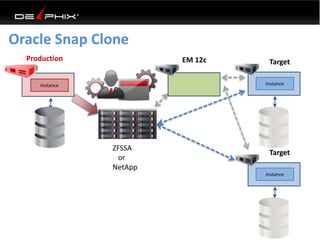
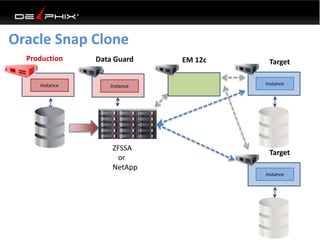
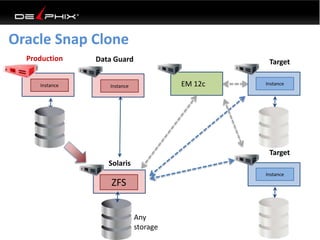
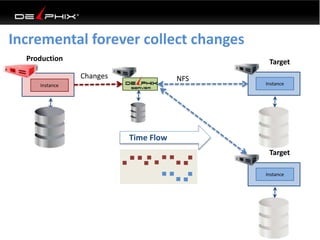


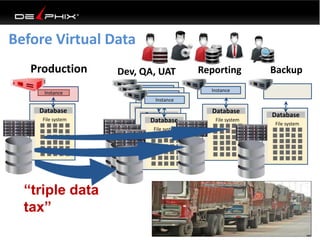
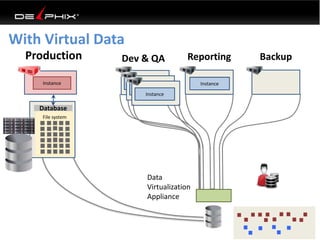








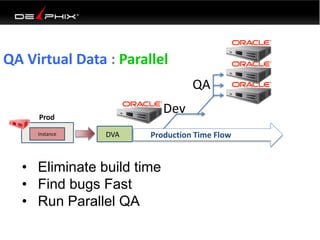
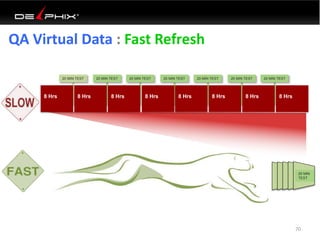
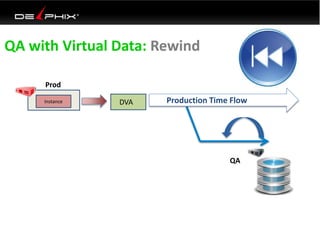
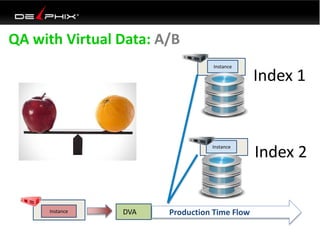



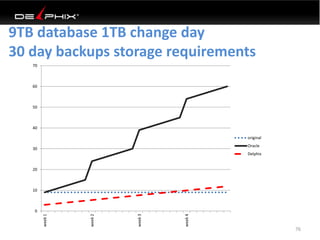
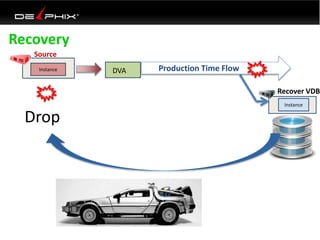
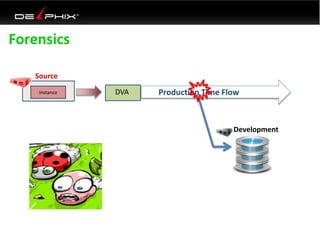
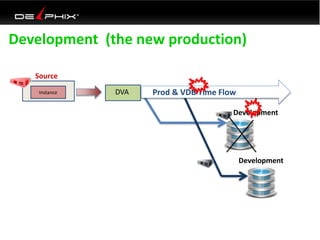
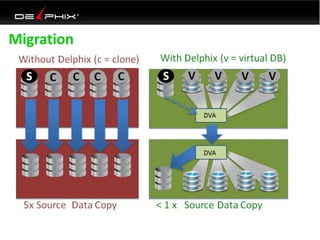

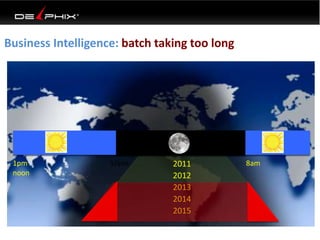


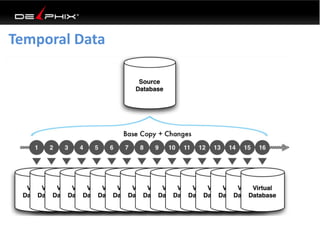

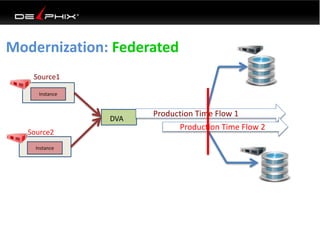

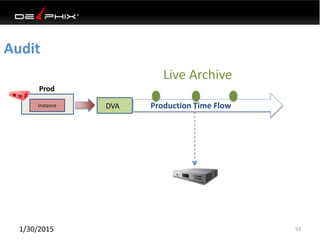



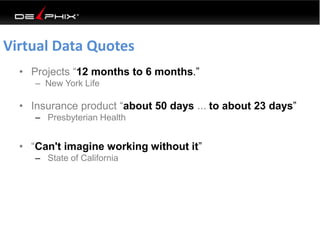


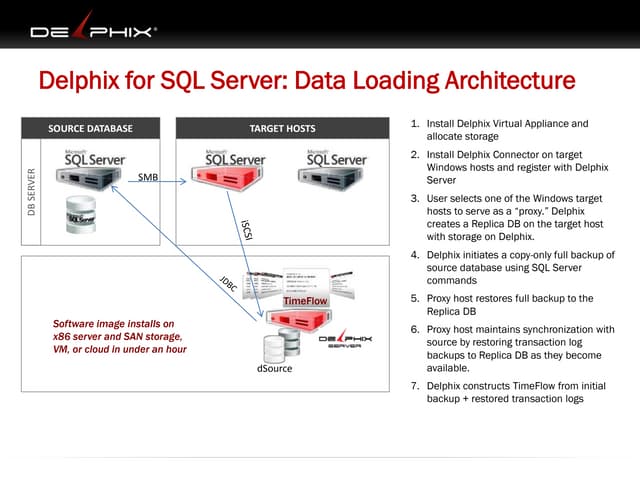
This document discusses data virtualization and its use in DevOps. It begins by explaining that data virtualization, also known as copy data management, is becoming more common. It then discusses how data virtualization enables DevOps practices like continuous integration by allowing fast provisioning of full database environments. The document outlines some of the typical challenges with traditional database architectures, including long setup times, lack of parallel environments, and high storage costs due to many full database copies. It presents data virtualization as a solution, allowing instant provisioning of thin clones from a production database. Finally, it provides examples of how data virtualization can help with development/QA, production support, and business intelligence use cases.






![Oracle Open World 2014: Lies, Damned Lies, and I/O Statistics [ CON3671]](https://cdn.slidesharecdn.com/ss_thumbnails/thursday115ionfs-141107125307-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)