Downloaded 25 times




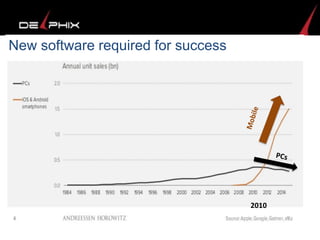









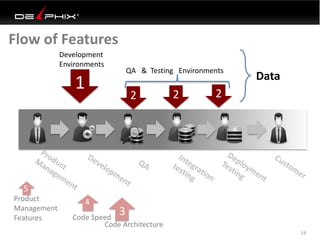
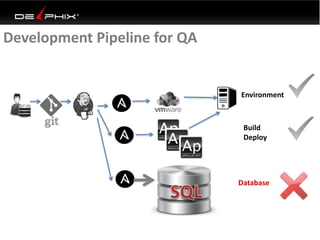

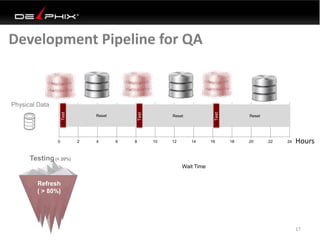








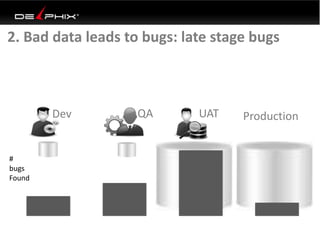
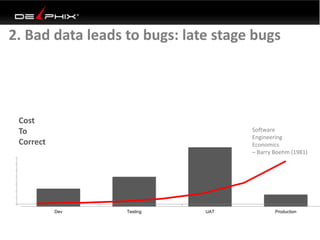

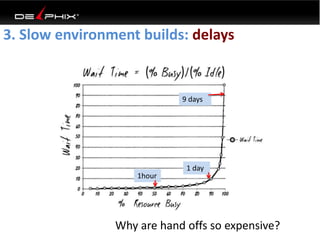




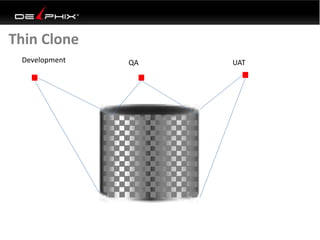
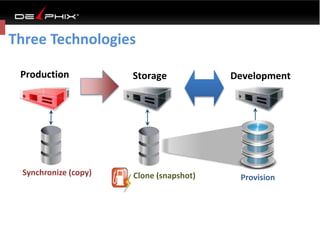
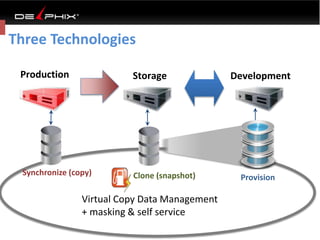


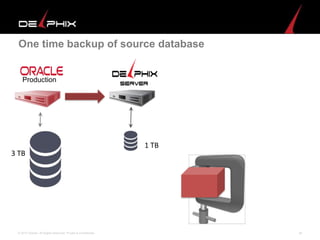
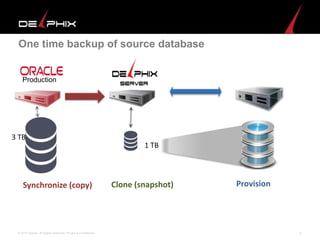
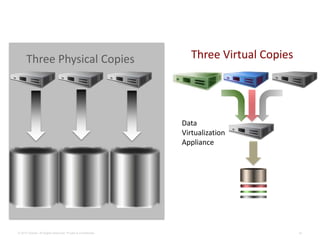
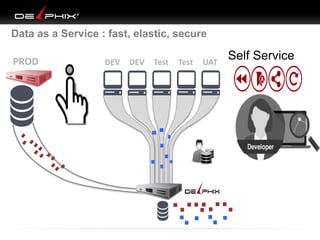






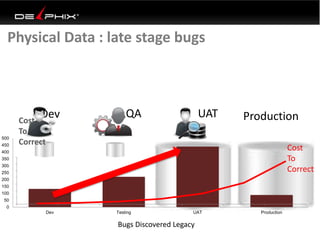
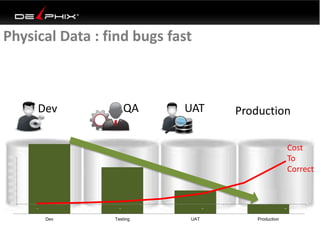
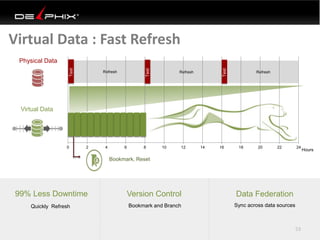

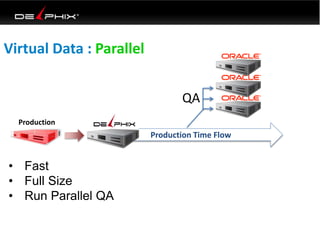
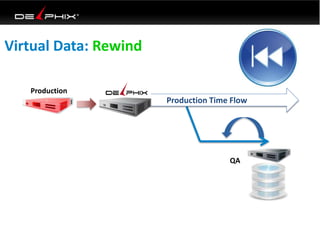
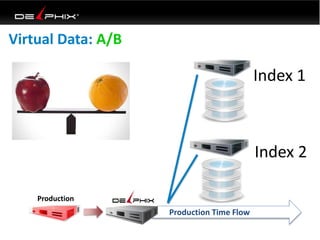
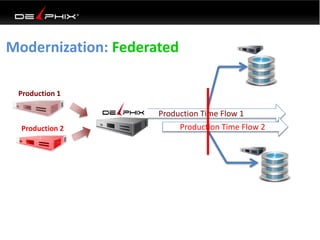



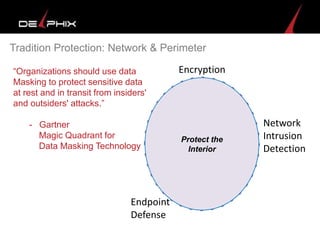
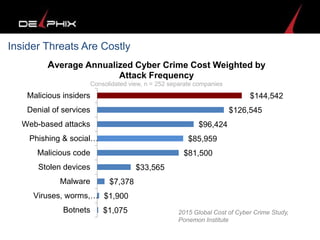
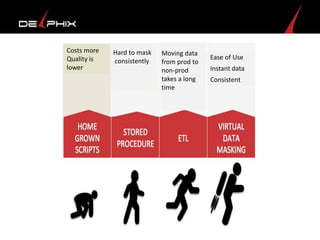



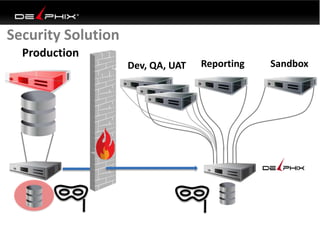



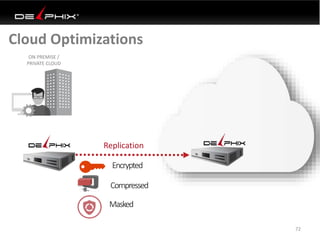
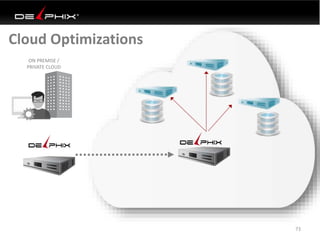
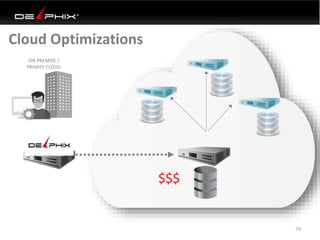
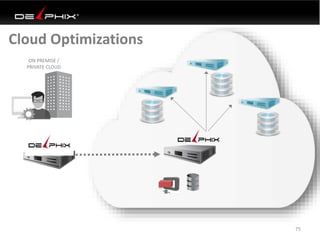
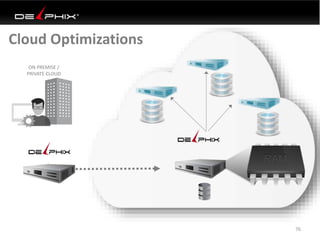
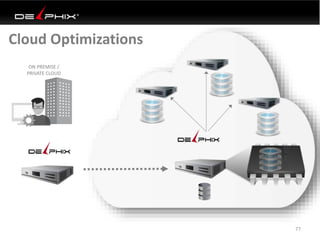
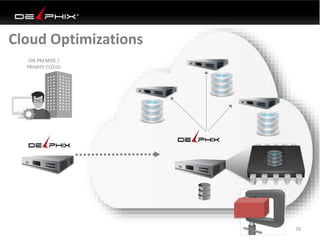

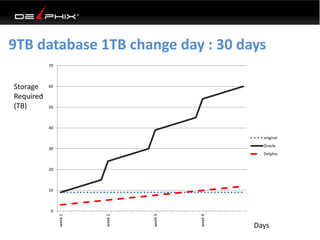
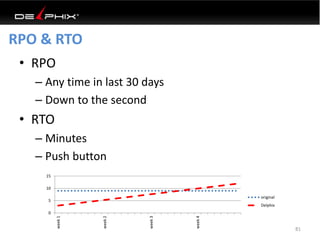
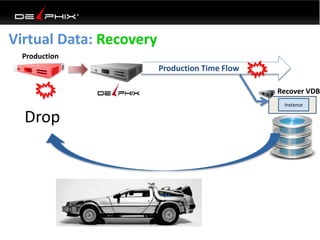
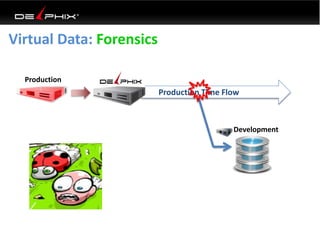
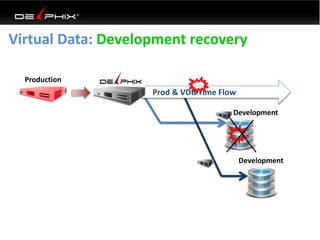


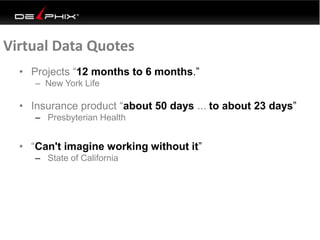
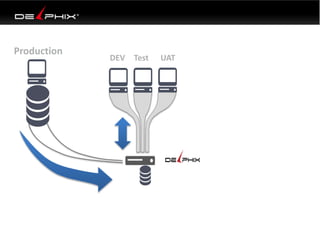


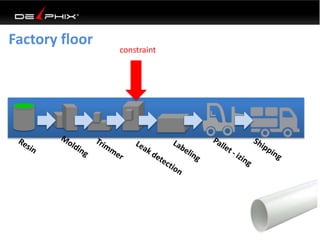
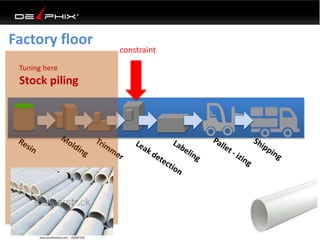
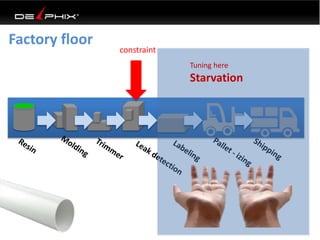
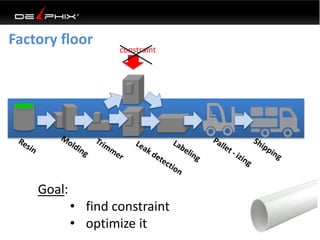

Virtual data provided by Delphix can eliminate data as a constraint in application development by enabling: 1) Fast provisioning of full-sized development databases in minutes from production data without moving large amounts of data. This allows development and testing to parallelize and find bugs earlier. 2) Self-service access to consistent, masked data for multiple use cases like development, security and cloud migration. Masking only needs to be done once before cloning databases. 3) Optimized data movement to the cloud through compression, encryption and replication of thin cloned data sets 1/3 the size of full production databases. This improves cloud migration and enables active-active disaster recovery across sites.























































![Oracle Open World 2014: Lies, Damned Lies, and I/O Statistics [ CON3671]](https://cdn.slidesharecdn.com/ss_thumbnails/thursday115ionfs-141107125307-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

























