Download as PDF, PPTX




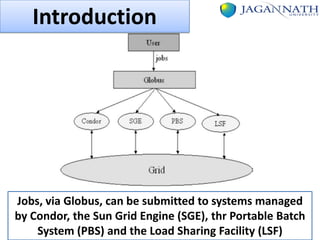


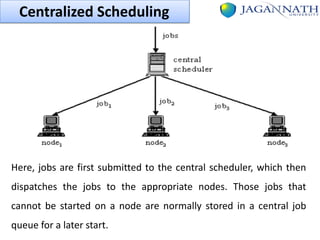

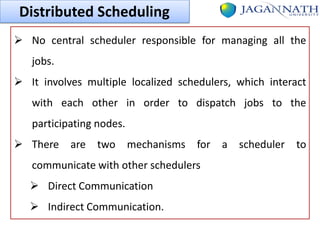
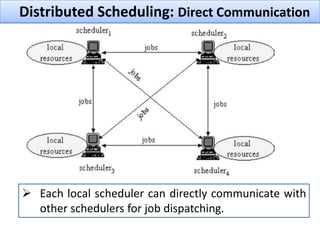

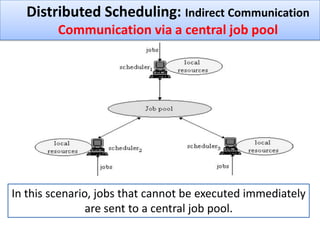

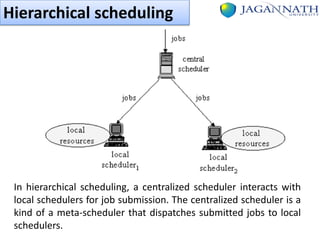



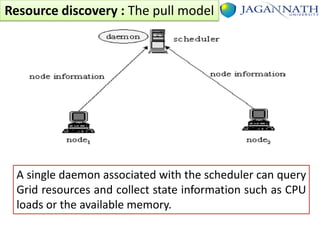

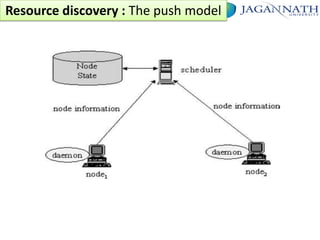

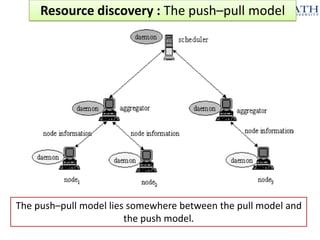





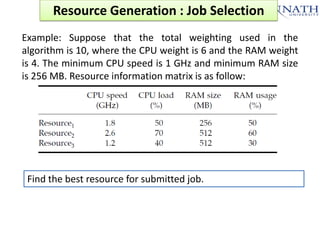








The document discusses grid computing and various scheduling paradigms such as centralized, hierarchical, and distributed scheduling, detailing the processes involved in job scheduling across multiple resources. It outlines four main stages of scheduling: resource discovery, resource selection, schedule generation, and job execution, emphasizing strategies for efficient resource utilization. Additionally, it covers the advantages and disadvantages of each scheduling paradigm and different job selection strategies like first come first serve, priority-based selection, and backfilling.







































![Grid computing [2005]](https://cdn.slidesharecdn.com/ss_thumbnails/gridcomputing2005-120430023634-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































































