


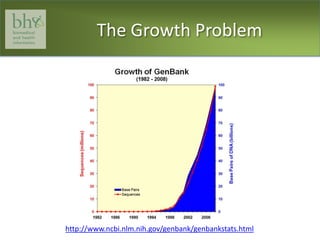
![The Growth ProblemLu Z. PubMed and Beyond. Database 2011;2011:baq036 21245076[pmid]](https://image.slidesharecdn.com/1mskfearn4-06-11-110708041014-phpapp01/85/NY-Prostate-Cancer-Conference-P-A-Fearn-Session-1-Data-management-for-predictive-tools-3-320.jpg)
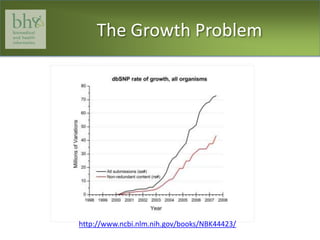


![The Curation ProblemIncreasing volume of dataMore data points for annotationClinical / patientGenomic / biologicalPublic health / environmentParallel curation issues in modern clinical and biological research databases (Krallinger 2008*)Development of NLP system to support clinical research operations (Savova 2010**)*18834499[pmid], **20819853[pmid]](https://image.slidesharecdn.com/1mskfearn4-06-11-110708041014-phpapp01/85/NY-Prostate-Cancer-Conference-P-A-Fearn-Session-1-Data-management-for-predictive-tools-8-320.jpg)



![Tightly Integrating DataVocabulary / TerminologyNCI Thesaurus (NCIt)NLM UMLSStandard data modelscaBIG / caDSRHL7/FDA/NCI CDISC / BRIDGWeb services*Common syntax / format*Stein. Creating a bioinformatics nation. Nature (2002) vol. 417 (6885) pp. 119-20 12000935[pmid]](https://image.slidesharecdn.com/1mskfearn4-06-11-110708041014-phpapp01/85/NY-Prostate-Cancer-Conference-P-A-Fearn-Session-1-Data-management-for-predictive-tools-12-320.jpg)
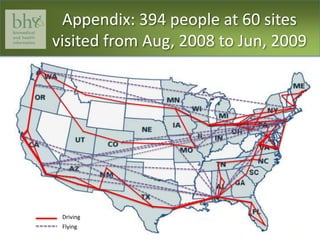




This document discusses data management requirements for predictive modeling using large datasets from multiple clinical, specimen, and lab repositories. It notes the need to assemble complete and up-to-date datasets while maintaining quality assurance and transparency. Over time, data storage systems experience problems with exponential data growth, manual data curation difficulties, and challenges integrating heterogeneous databases across different research groups. The document examines a spectrum of potential data management approaches and highlights collaborative networks and use of open source platforms as ways to address these issues.























































































