Download as PDF, PPTX








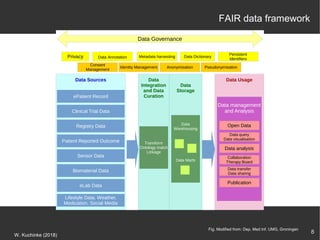
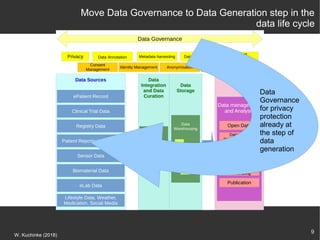
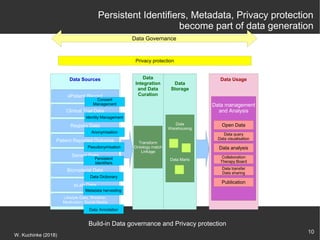












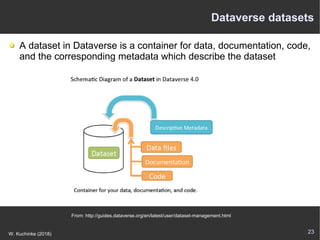















The document discusses the importance of open data in the research ecosystem, emphasizing that data sharing is essential for reproducibility and scientific progress. It highlights the FAIR principles (Findable, Accessible, Interoperable, Reusable) as a framework for managing research data and emphasizes the critical role of metadata for data recovery and reuse. Furthermore, it presents various tools and platforms like CKAN, Transmart, and Dataverse that facilitate open data management and integration within the biomedical research context.


















































































