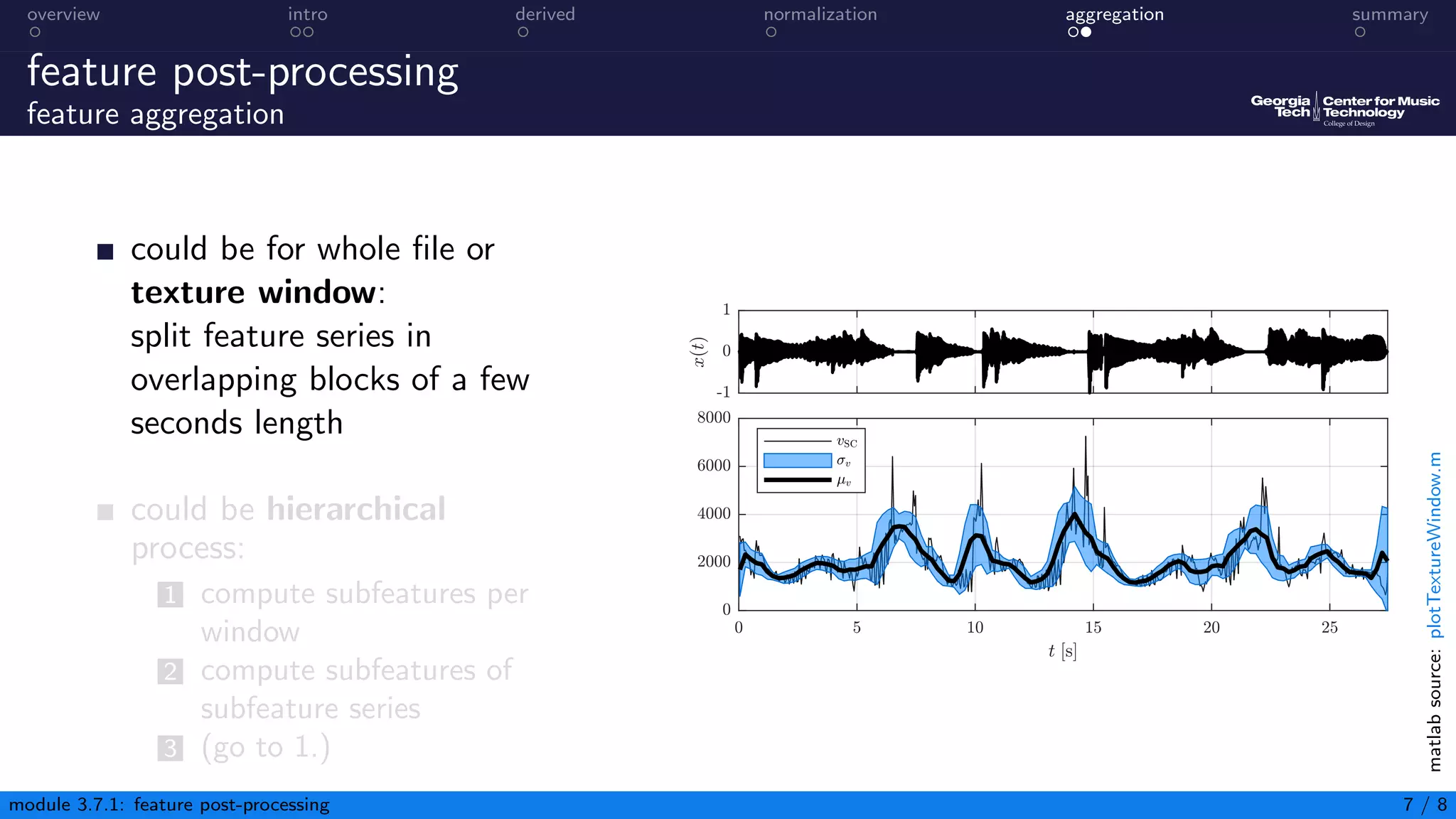
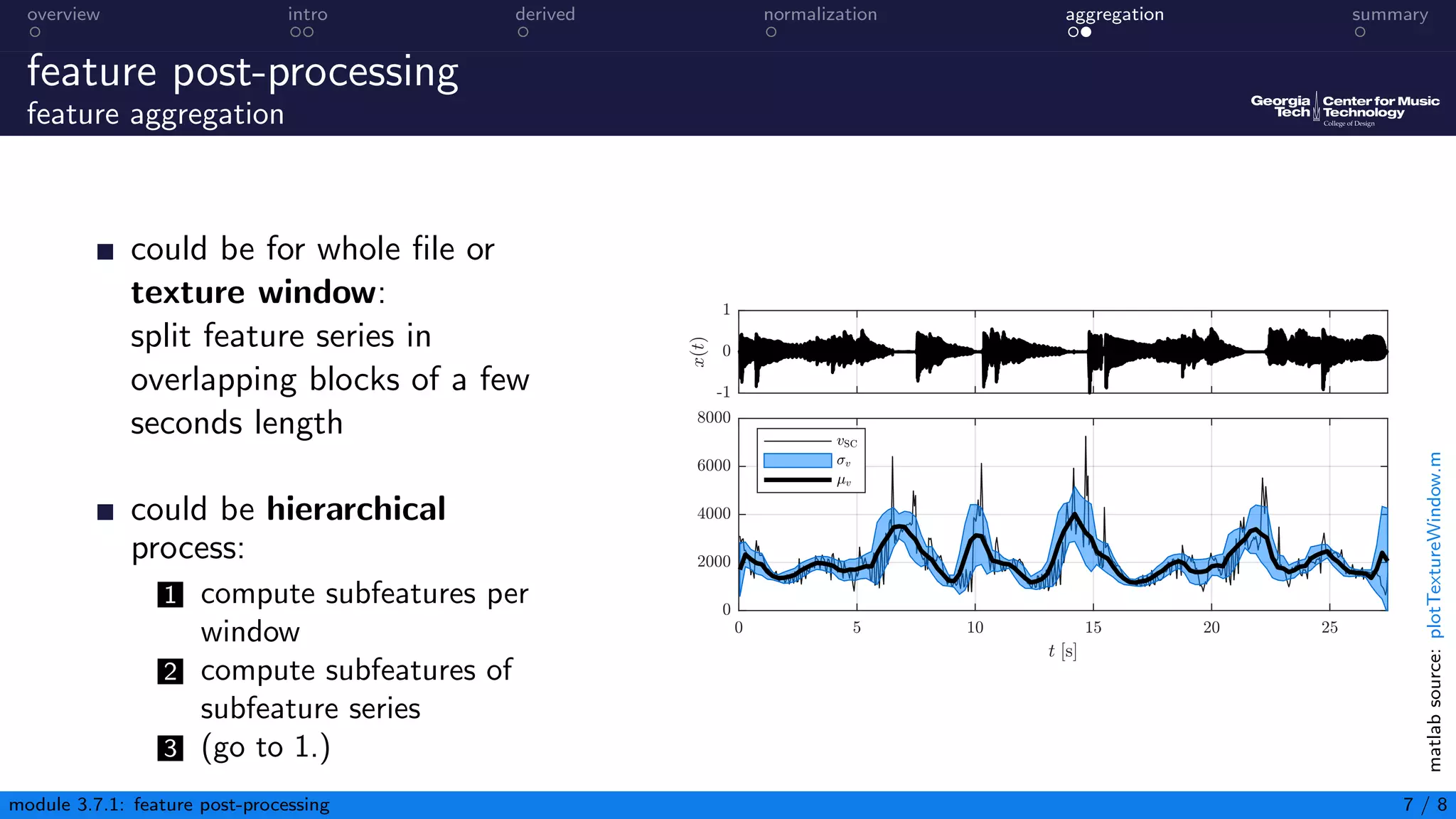
This document discusses post-processing of audio content features. It describes deriving additional features, aggregating features to reduce data and compute summary statistics, and normalizing features to ensure similar scales and distributions. Specific techniques include taking differences between adjacent values to derive new features, smoothing features using filters, computing z-score and min-max normalization, and aggregating features within blocks using statistical descriptors. The overall aim is to adapt the feature matrix to the task and classifier.

![overview intro derived normalization aggregation summary
feature post-processing
introduction 1/2
extracting multiple instantaneous features leads to
→ one feature vector per block, or
→ one feature matrix per audio file
V = [v(0) v(1) . . . v(N − 1)]
=
v0(0) v0(1) . . . v0(N − 1)
v1(0) v1(1) . . . v1(N − 1)
.
.
.
.
.
.
...
.
.
.
vF−1(0) vF−1(1) . . . vF−1(N − 1)
dimensions: F × N (number of features and number of blocks, resp.)
module 3.7.1: feature post-processing 2 / 8](https://image.slidesharecdn.com/03-07-01-aca-input-post-processing-230301025219-f3a895e1/75/03-07-01-ACA-Input-Post-Processing-pdf-4-2048.jpg)