Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Shota Yasui
PDF, PPTX
14,312 views
木と電話と選挙(causalTree)
Susan AtheyのcausalTreeをRで実装したパッケージの紹介です。
Data & Analytics
◦
Read more
18
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
計量経済学と 機械学習の交差点入り口 (公開用)
by
Shota Yasui
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PDF
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
計量経済学と 機械学習の交差点入り口 (公開用)
by
Shota Yasui
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
関数データ解析の概要とその方法
by
Hidetoshi Matsui
Rubinの論文(の行間)を読んでみる-傾向スコアの理論-
by
Koichiro Gibo
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
What's hot
PDF
Deeplearning輪読会
by
正志 坪坂
PDF
[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis
by
Deep Learning JP
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PPTX
LightGBMを少し改造してみた ~カテゴリ変数の動的エンコード~
by
RyuichiKanoh
PPTX
強化学習における好奇心
by
Shota Imai
PDF
はじめよう多変量解析~主成分分析編~
by
宏喜 佐野
PDF
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PPTX
Noisy Labels と戦う深層学習
by
Plot Hong
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
適切なクラスタ数を機械的に求める手法の紹介
by
Takeshi Mikami
PDF
10分でわかる主成分分析(PCA)
by
Takanori Ogata
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
PDF
質的変数の相関・因子分析
by
Mitsuo Shimohata
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PPTX
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PPTX
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
Deeplearning輪読会
by
正志 坪坂
[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis
by
Deep Learning JP
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
LightGBMを少し改造してみた ~カテゴリ変数の動的エンコード~
by
RyuichiKanoh
強化学習における好奇心
by
Shota Imai
はじめよう多変量解析~主成分分析編~
by
宏喜 佐野
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
Noisy Labels と戦う深層学習
by
Plot Hong
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
適切なクラスタ数を機械的に求める手法の紹介
by
Takeshi Mikami
10分でわかる主成分分析(PCA)
by
Takanori Ogata
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
質的変数の相関・因子分析
by
Mitsuo Shimohata
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
金融時系列のための深層t過程回帰モデル
by
Kei Nakagawa
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
不均衡データのクラス分類
by
Shintaro Fukushima
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
異常検知と変化検知の1~3章をまとめてみた
by
Takahiro Yoshizawa
Viewers also liked
PPTX
20161127 doradora09 japanr2016_lt
by
Nobuaki Oshiro
PPTX
Tidyverseとは
by
yutannihilation
PDF
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
PPTX
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
PDF
傾向スコア:その概念とRによる実装
by
takehikoihayashi
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
PDF
確実に良くするUI/UX設計
by
Takayuki Fukatsu
20161127 doradora09 japanr2016_lt
by
Nobuaki Oshiro
Tidyverseとは
by
yutannihilation
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
統計的因果推論勉強会 第1回
by
Hikaru GOTO
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
傾向スコア:その概念とRによる実装
by
takehikoihayashi
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
確実に良くするUI/UX設計
by
Takayuki Fukatsu
More from Shota Yasui
PDF
L 05 bandit with causality-公開版
by
Shota Yasui
PDF
Contextual package
by
Shota Yasui
PDF
PaperFriday: The selective labels problem
by
Shota Yasui
PDF
TokyoR 20180421
by
Shota Yasui
PDF
何故あなたの機械学習はビジネスを改善出来ないのか?
by
Shota Yasui
PDF
Factorization machines with r
by
Shota Yasui
PDF
Estimating the effect of advertising with Machine learning
by
Shota Yasui
PPTX
Prml nn
by
Shota Yasui
PPTX
Xgboost for share
by
Shota Yasui
PPTX
重回帰分析で頑張る
by
Shota Yasui
PDF
Dynamic panel in tokyo r
by
Shota Yasui
PDF
Rで部屋探し For slide share
by
Shota Yasui
PDF
Salmon cycle
by
Shota Yasui
L 05 bandit with causality-公開版
by
Shota Yasui
Contextual package
by
Shota Yasui
PaperFriday: The selective labels problem
by
Shota Yasui
TokyoR 20180421
by
Shota Yasui
何故あなたの機械学習はビジネスを改善出来ないのか?
by
Shota Yasui
Factorization machines with r
by
Shota Yasui
Estimating the effect of advertising with Machine learning
by
Shota Yasui
Prml nn
by
Shota Yasui
Xgboost for share
by
Shota Yasui
重回帰分析で頑張る
by
Shota Yasui
Dynamic panel in tokyo r
by
Shota Yasui
Rで部屋探し For slide share
by
Shota Yasui
Salmon cycle
by
Shota Yasui
Recently uploaded
PDF
EspressReport Enterprise Server ホワイトペーパー
by
株式会社クライム
PDF
研究資料ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
by
4fqg857pxh
PPTX
【Qlik 医療データ活用勉強会】医療の質可視化アプリの公開-その2- 20260128
by
QlikPresalesJapan
PPTX
KNIMEで奈良の気温を調べてみた_2026_0207_KNIMEST.pptx
by
syk zassou
PPTX
KNIMEは地味だが役に立つ_2026_0207_DojoMeeting_Kansai_#1.pptx
by
syk zassou
PPTX
What's New In Qlik ~ 2025年12月&2026年1月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
EspressReport Enterprise Server ホワイトペーパー
by
株式会社クライム
研究資料ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
by
4fqg857pxh
【Qlik 医療データ活用勉強会】医療の質可視化アプリの公開-その2- 20260128
by
QlikPresalesJapan
KNIMEで奈良の気温を調べてみた_2026_0207_KNIMEST.pptx
by
syk zassou
KNIMEは地味だが役に立つ_2026_0207_DojoMeeting_Kansai_#1.pptx
by
syk zassou
What's New In Qlik ~ 2025年12月&2026年1月リリース最新機能のご紹介 ~
by
QlikPresalesJapan
木と電話と選挙(causalTree)
1.
木と電話と選挙 Shota Yasui Japan.R 2016/11/27
2.
CausalTreeパッケージ ● Recursive Partitioning
for Heterogeneous Causal Effects ● Susan AtheyとGuido Imbensの提案手法 ● 機械学習のモデルを応用して、CATEを推定する。 ○ 介入効果が別の要因で強弱がついているという想定 ● 今回は機械学習の部分が決定木及びRandom Forestになっている。
3.
GerberGreenImaiデータ ● Do Get-Out-the-Vote
Calls Reduce Turnout? The Importance of Statistical Methods for Field Experiments ● 上記の論文で使われたデータ ● Matchingパッケージの中に入ってる。
4.
投票しましょう。 選挙前に投票を促す連絡を取る。
5.
投票日の選択肢
6.
この電話活動が投票率に影響があるのかを知りたい!
7.
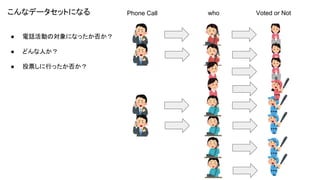
Phone Call who
Voted or Notこんなデータセットになる ● 電話活動の対象になったか否か? ● どんな人か? ● 投票しに行ったか否か?
8.
傾向スコアを利用する ● 電話活動がある程度対象を選んで行われていると考える。 ● 電話された人とされてない人では、そもそも投票に行く確率が違う。 ●
これを補正して効果を推定する必要がある。 →傾向スコア(詳細は割愛)
9.
PropensityScoreMatchingで推定する ● 電話の割り振りでPropensityScoreを出して、Matching。
10.
平均的には5%投票率を押し上げる
11.
電話の効果が、 性別や年齢や地域で違うんじゃないか?
12.
これを推定しに行くお話 ● Susan Atheyが提案しているCausal
TreeとCausal Forestを使う。 ○ Recursive Partitioning for Heterogeneous Causal Effects ○ Estimation and Inference of Heterogeneous Treatment Effects using Random Forests ● causalTreeパッケージとしてgithub上に公開されている。 ○ https://github.com/susanathey/causalTree ● 決定木の学習方法を改良して unbiased estimatorを得ようという話。
13.
決定木と大きく違う2点 ● コスト関数のデザインが違う ○ 機械学習で考えると:投票行動での予測誤差の最小化 ○
causalTree:電話の、投票行動に与える効果での予測誤差の最小化 ■ あくまで最小化したい誤差の定義が変わったという認識 →アンサンブルもできちゃう ● 推定時のデータの使い方が違う ○ 普通の決定木:学習データで枝と葉の両方を学習する ○ 今回:学習データを分けておいて、枝と葉の学習には別々のデータを用いる。
14.
PropensityTree(Forest)もあるよ ● 電話のケースのように、介入の割り振りに偏りが考えられるケースで使う。 ● この場合には枝の学習時にコスト関数を別のものにする。 ●
この時のコスト関数は介入の割り振りに対する予測誤差になる。
15.
propensityForestで推定する ● 可視化を前提として今回やるので、 PropensityForestで木の数を1にする。 ●
treatmentは電話を掛けたか否か PHN.C1 ● 設定周りの意味合いは下の資料参照 ○ https://github.com/susanathey/causalTree/blob/master/briefintro.pdf
16.
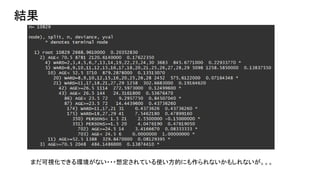
結果 まだ可視化できる環境がない・・・想定されている使い方的にも作られないかもしれないが。。。
17.
基本的なサマリ ● 年齢は若いほうが効果高い ○ 年齢が高い人のほうがそもそも投票率が高くて、それを押し上げるコストが高そう。 ○
投票所までの移動コストは年齢が高い人のほうがありそう。 ● 地域によって効果が違う ○ 地域のID以外の詳細データがないので地域間で比較とかはできない。 ○ 今回入ってない変数の影響とかが出てそう
18.
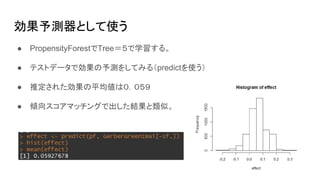
効果予測器として使う ● PropensityForestでTree=5で学習する。 ● テストデータで効果の予測をしてみる(predictを使う) ●
推定された効果の平均値は0.059 ● 傾向スコアマッチングで出した結果と類似。
19.
電話を掛ける対象を絞れる!
20.
おしまい。
Download

























![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)



































