Download as PDF, PPTX

















![Пример
xdb01g/maildb M # dS mail.box
Table "mail.box"
Column | Type | Modifiers
---------------+--------------------------+------------------------
uid | bigint | not null
mid | bigint | not null
lids | integer[] | not null
<...>
Indexes:
"pk_box" PRIMARY KEY, btree (uid, mid)
"i_box_uid_lids" gin (mail.ulids(uid, lids)) WITH (fastupdate=off)
28](https://image.slidesharecdn.com/2-161114181219/75/PostgreSQL-28-2048.jpg)












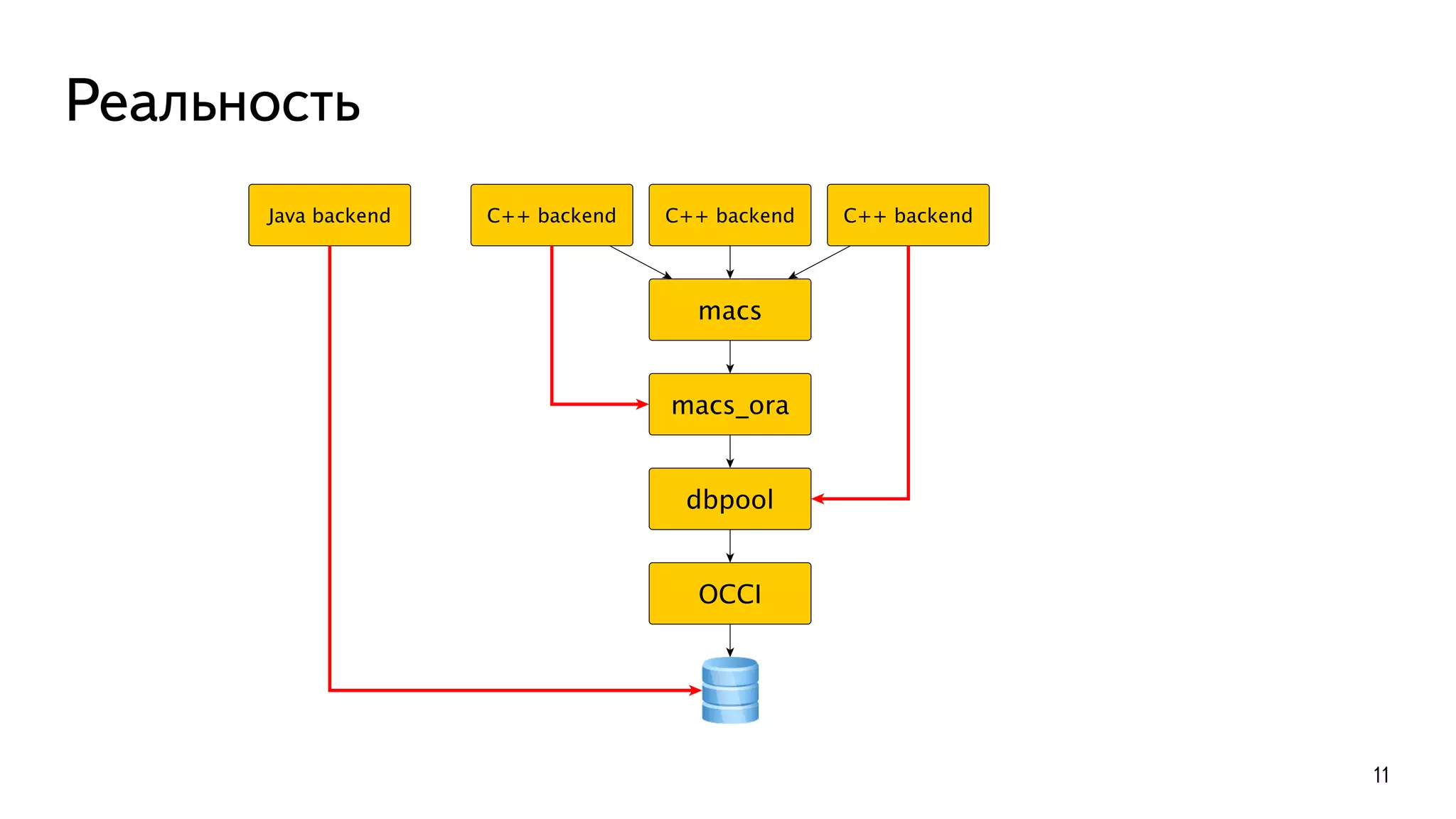
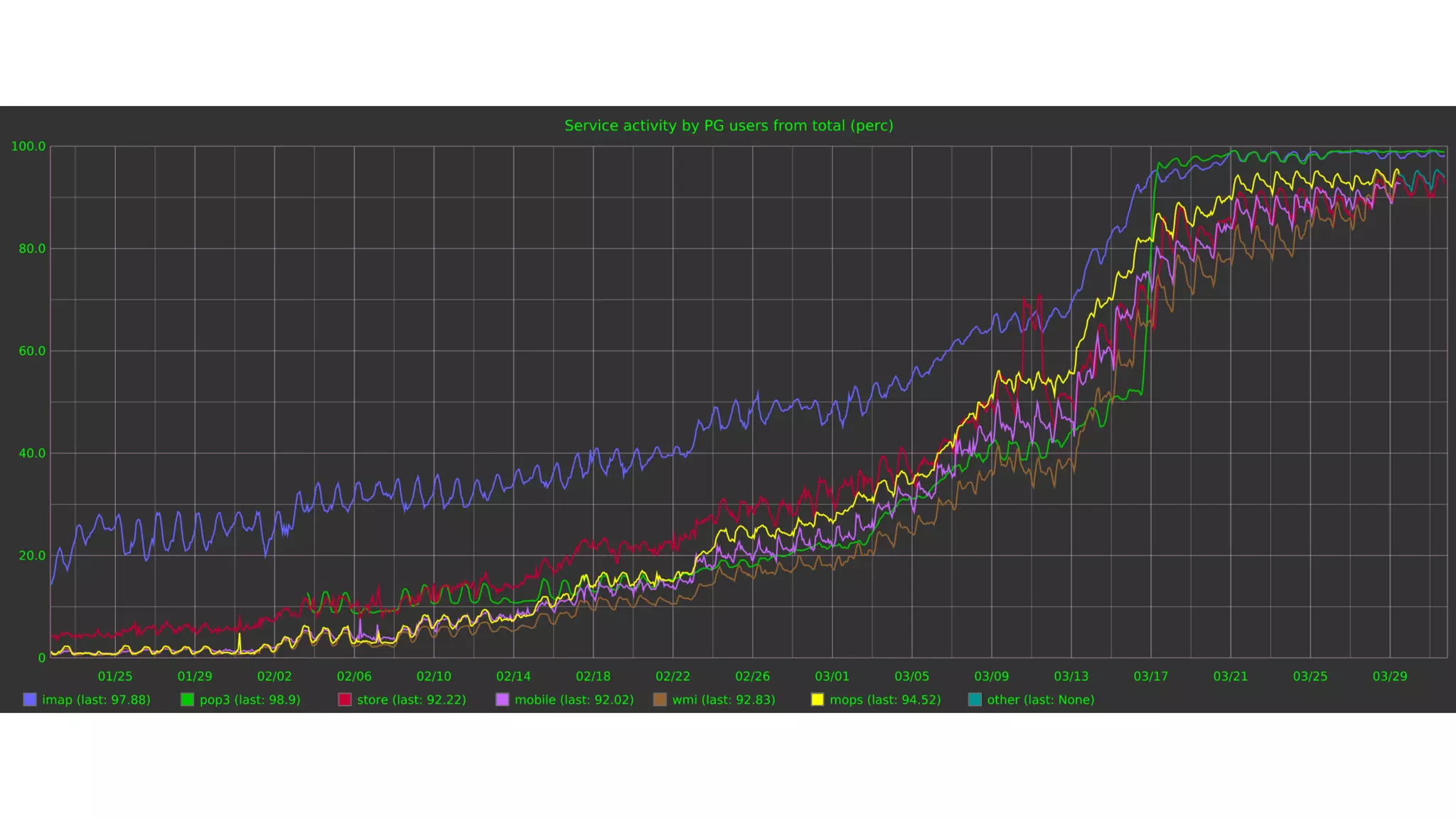
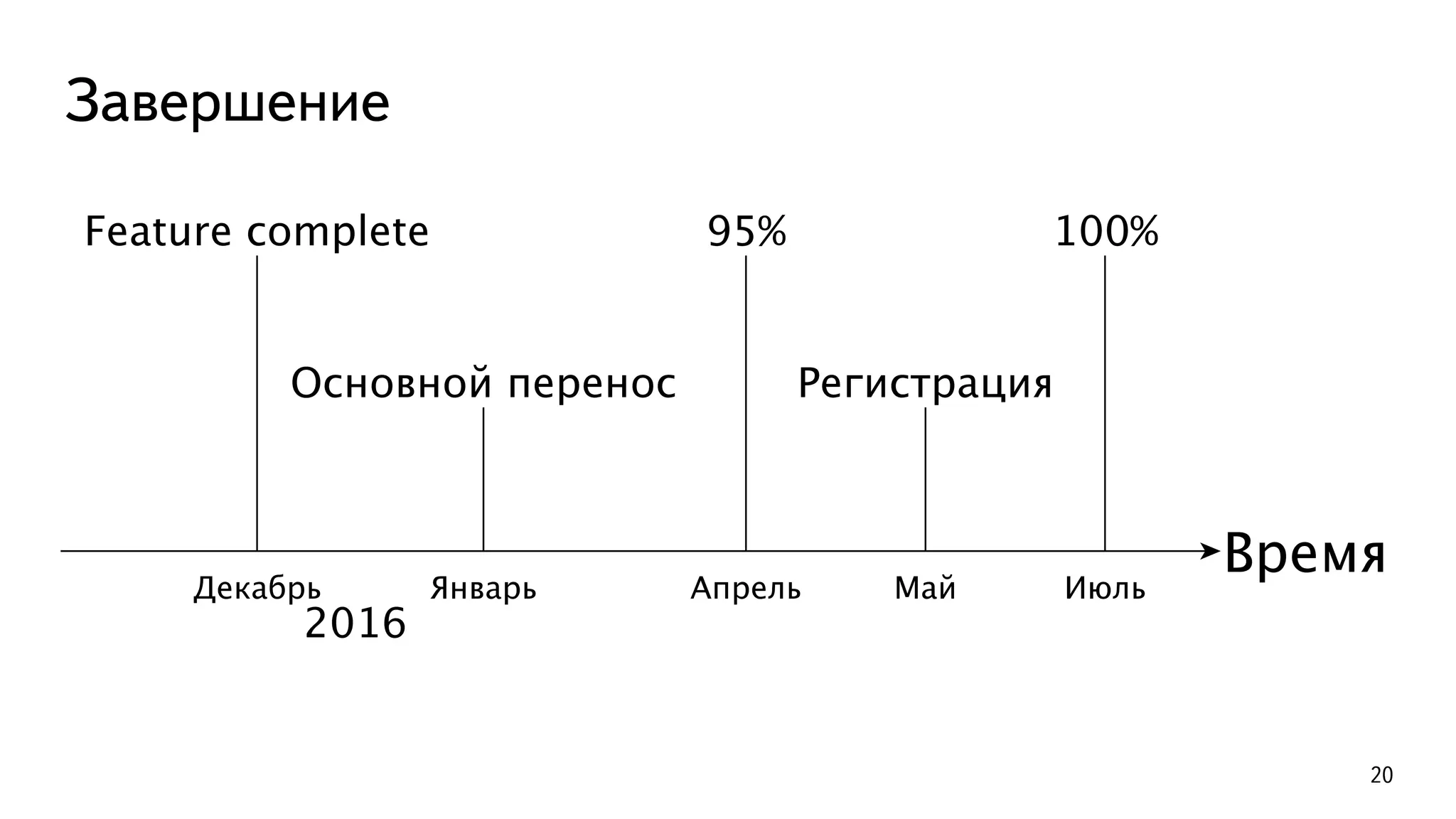
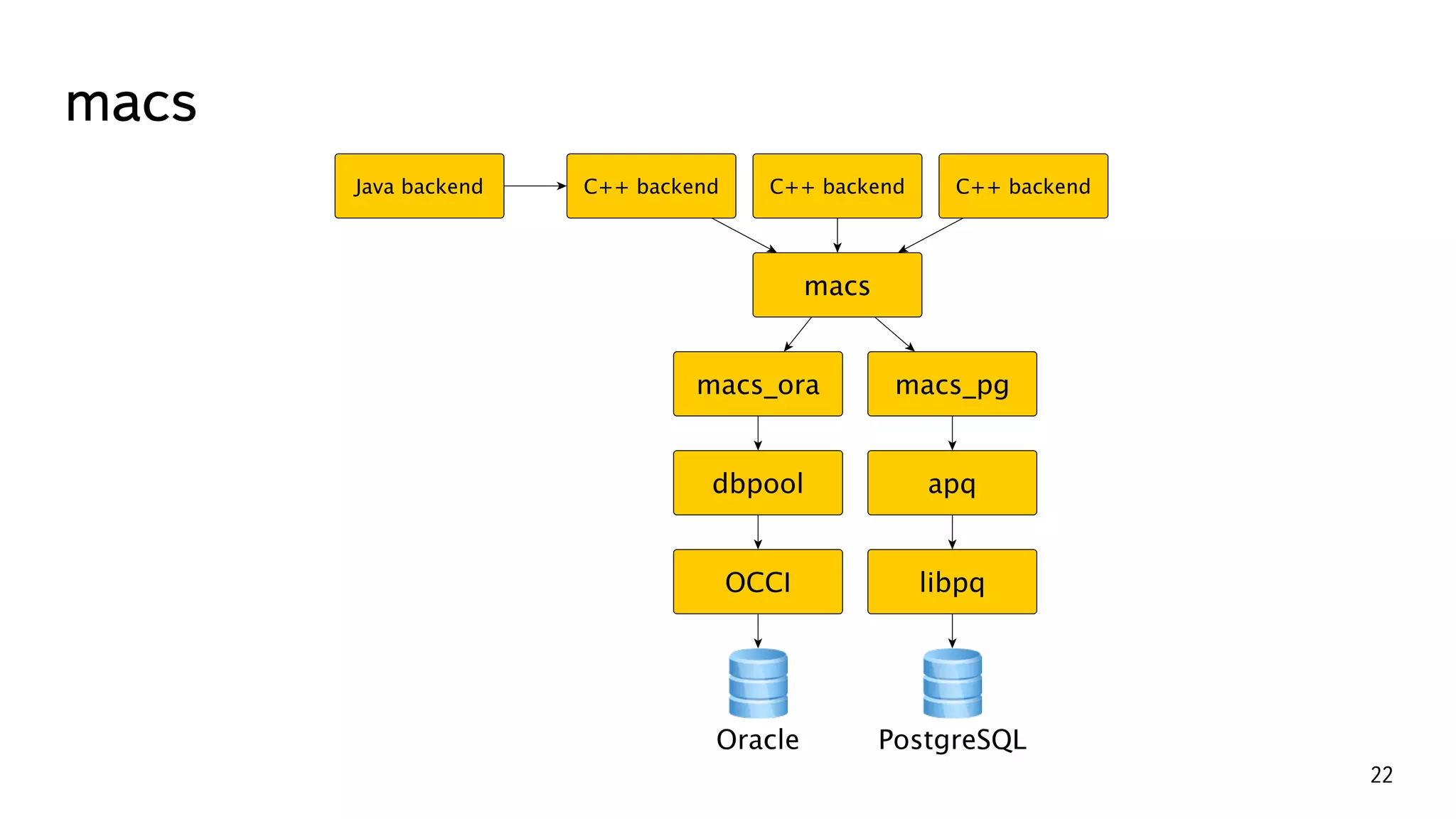
В документе описывается история успешной миграции Яндекс.Почты с Oracle на PostgreSQL, включая ключевые этапы и вызовы, связанные с этой трансформацией. Миграция, начавшаяся в 2012 году и завершившаяся в 2016 году, включала переноса более 300 ТБ данных и автоматизацию множества процессов. Основные достижения включают увеличение производительности до 250 000 TPS и эффективное использование аппаратного обеспечения.























































































