Download as PDF, PPTX






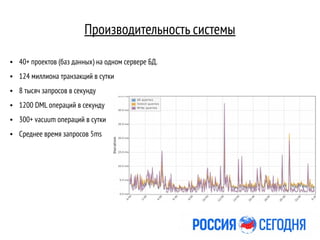




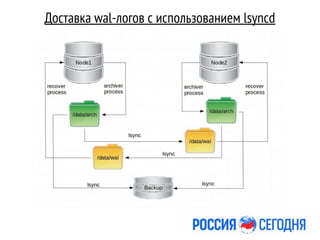





Документ описывает миграцию новостного приложения на базу данных PostgreSQL, проводимую Дмитрием Кремером, который имеет многолетний опыт в администрировании баз данных. Основные задачи включают достижение высокой производительности, отказоустойчивости и минимизации простоя, а также соблюдение требований по сохранестии структуры БД. В документе также обсуждаются особенности настройки, мониторинга и обеспечения безопасности системы.














































