Downloaded 202 times

![[email_address]](https://image.slidesharecdn.com/apacheconus2008tikapaolomottadelli-1225998762707619-8/75/Content-analysis-for-ECM-with-Apache-Tika-2-2048.jpg)


















































![Q & A [email_address]](https://image.slidesharecdn.com/apacheconus2008tikapaolomottadelli-1225998762707619-8/75/Content-analysis-for-ECM-with-Apache-Tika-71-2048.jpg)

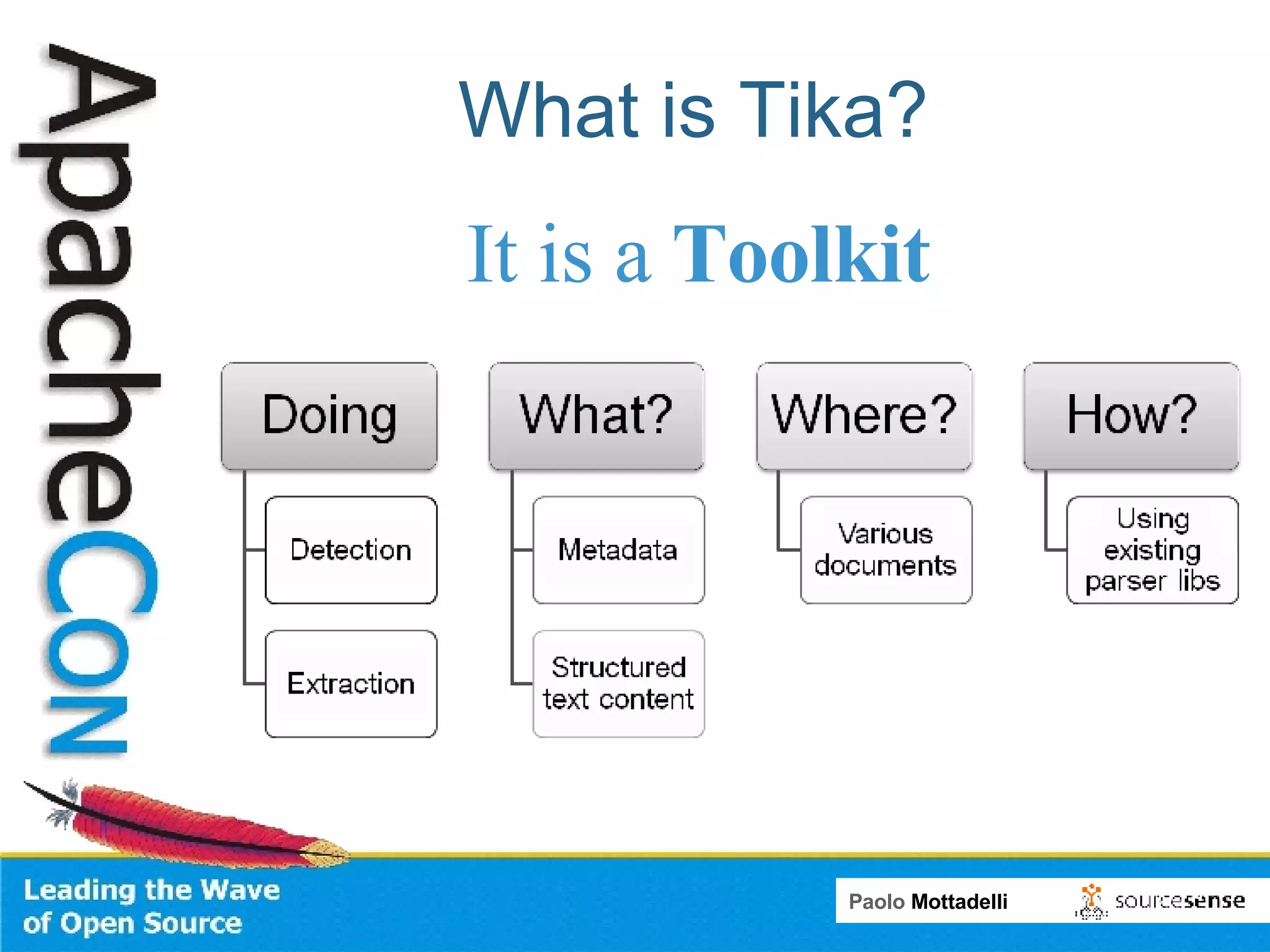
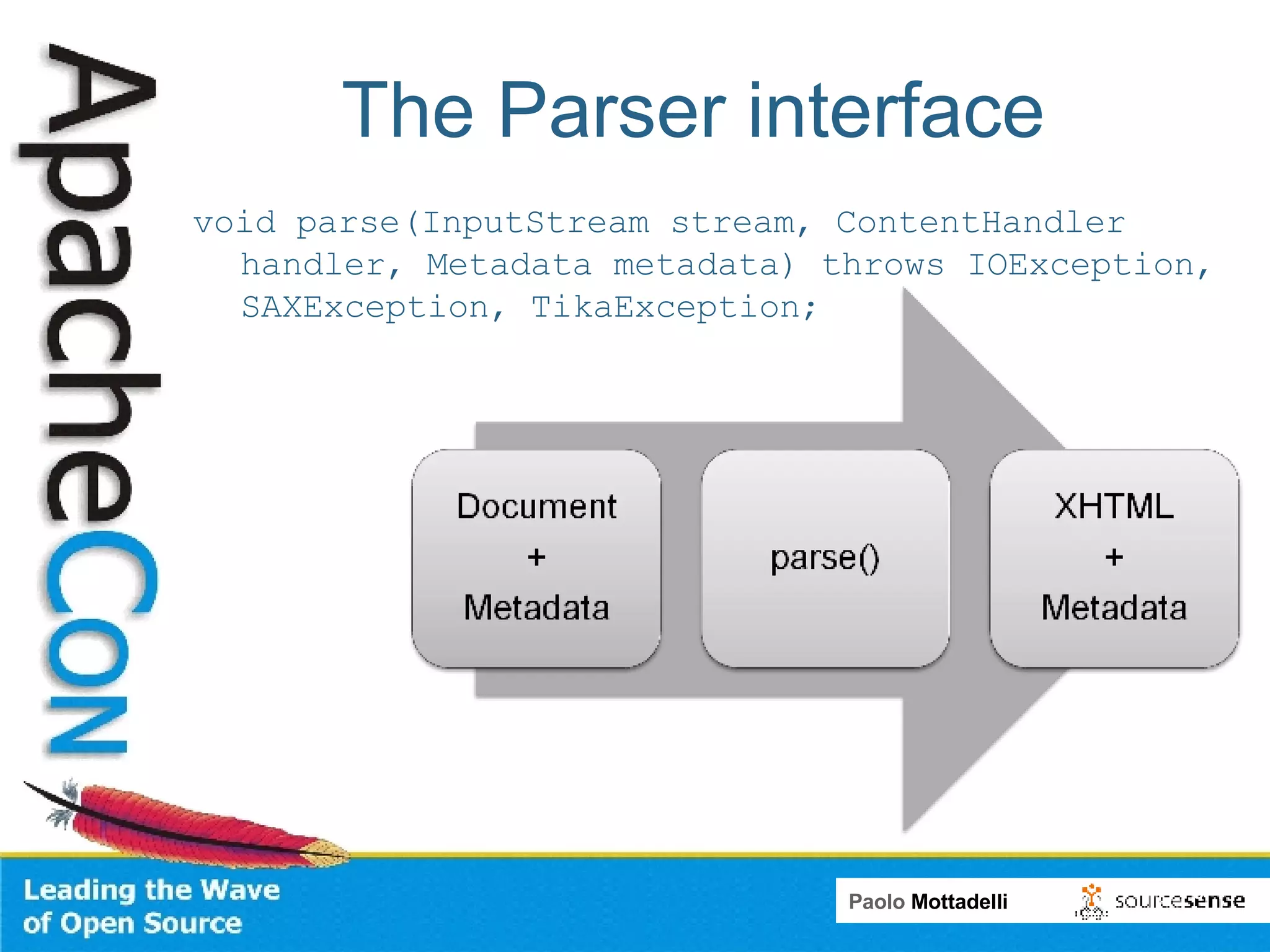
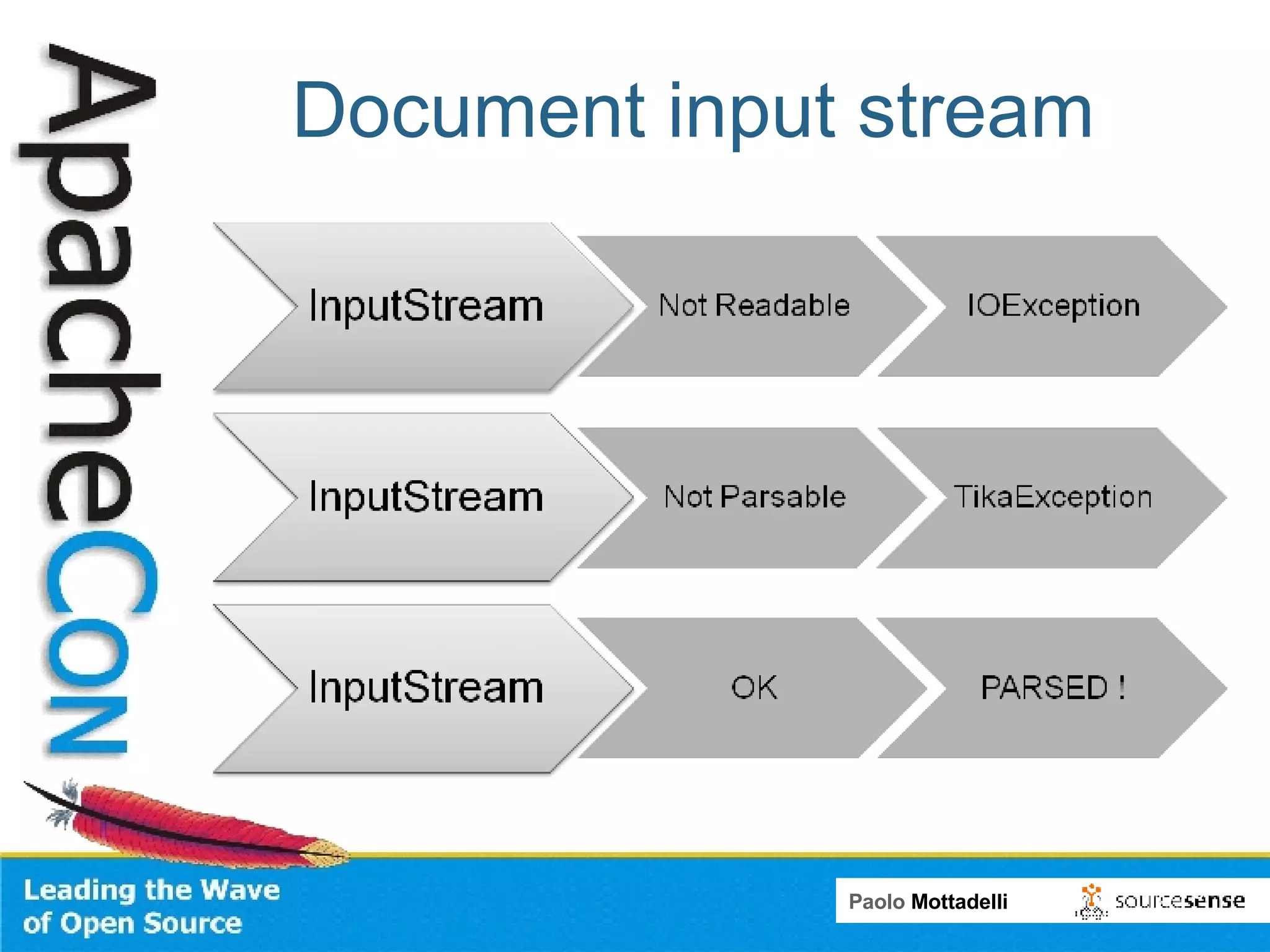
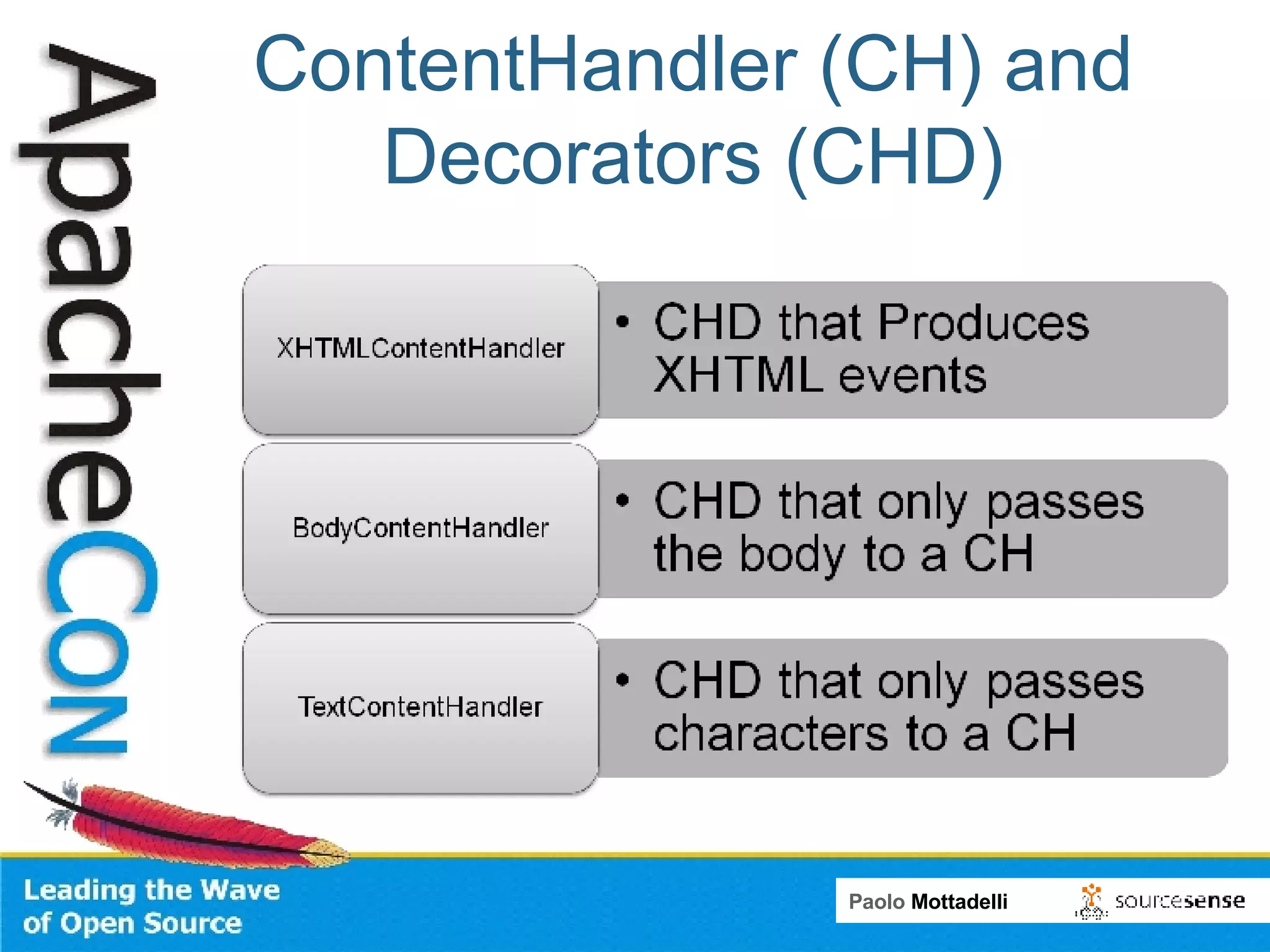
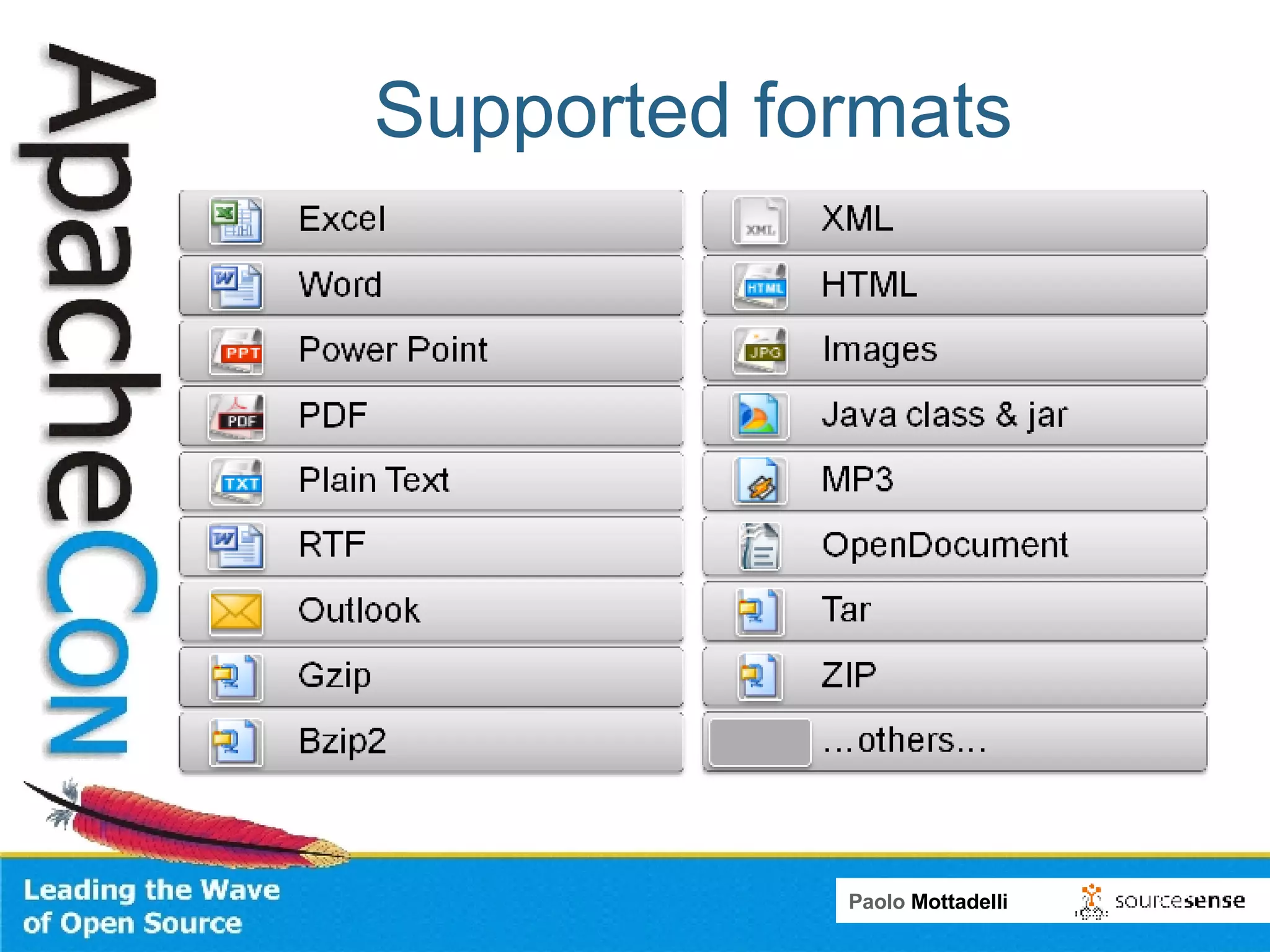
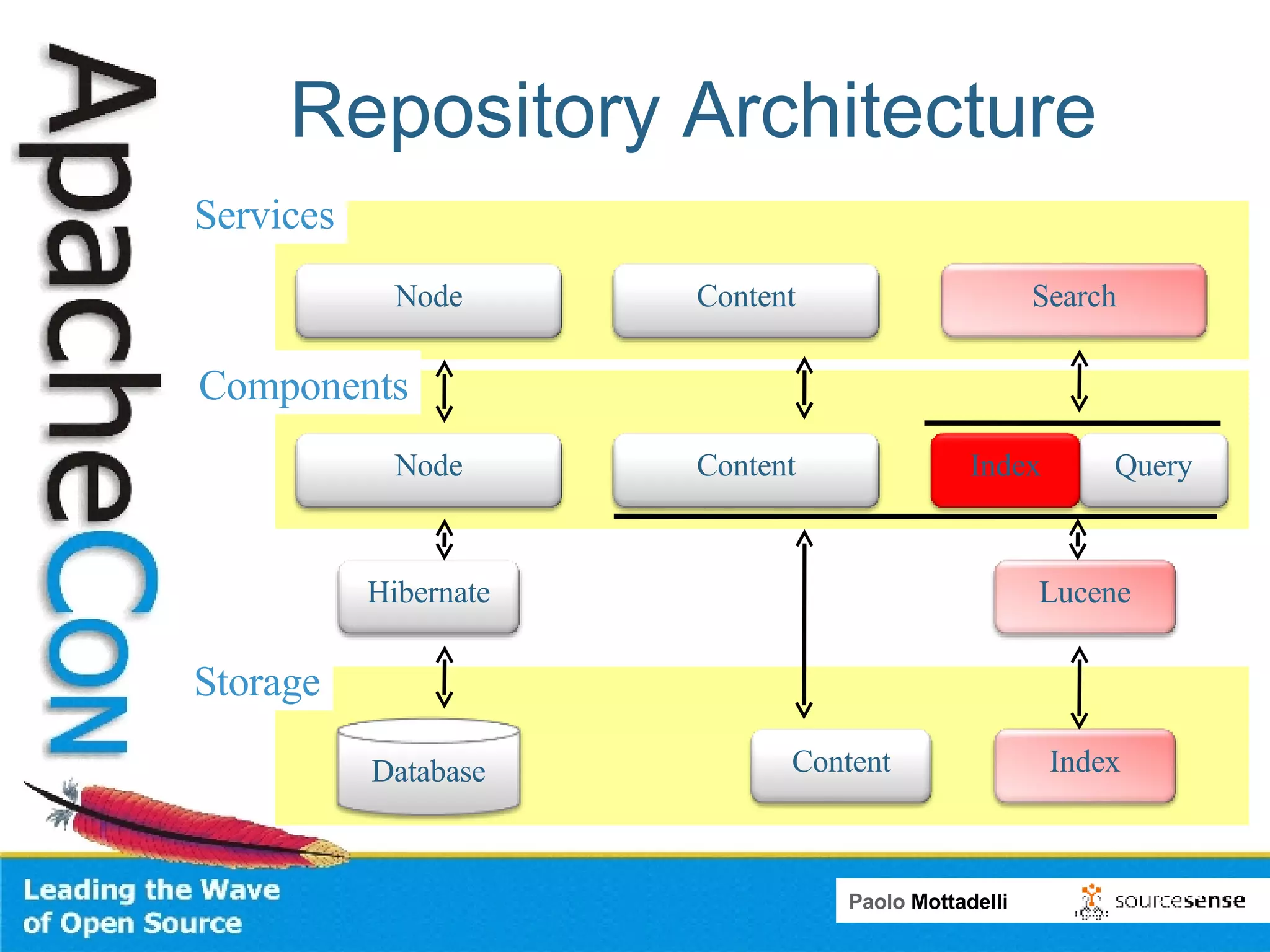
Tika is a toolkit for extracting metadata and text from various document formats. It allows developers to parse documents and extract metadata and text content in 3 main steps. Tika shields systems like Alfresco from needing to integrate many individual parsing components. Alfresco uses Tika to index content from various formats by passing file streams through Tika's parsers rather than using multiple custom transformers.

























































































