Download to read offline



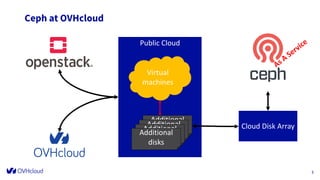
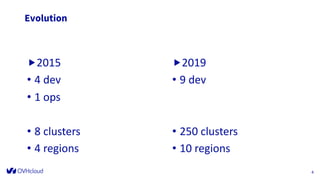

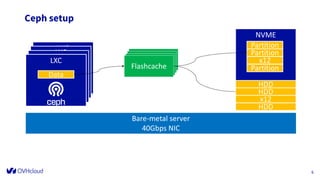

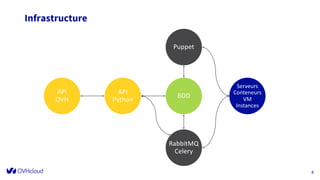
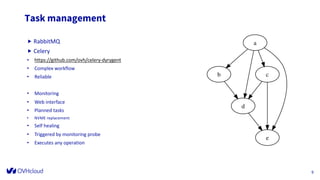
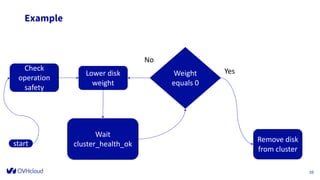
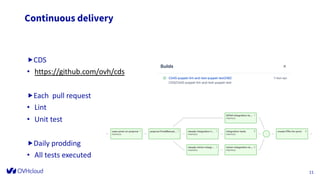








The document outlines the infrastructure management of OVHcloud, detailing the growth from 4 clusters in 2015 to 250 clusters by 2019, managed by a single sysadmin. It highlights the various technologies and processes used, such as Ceph as a service for storage and the automation of infrastructure management through tools like RabbitMQ and continuous delivery practices. Additionally, it includes insights on metrics monitoring and logging capabilities to ensure operational efficiency.





















![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)
































































