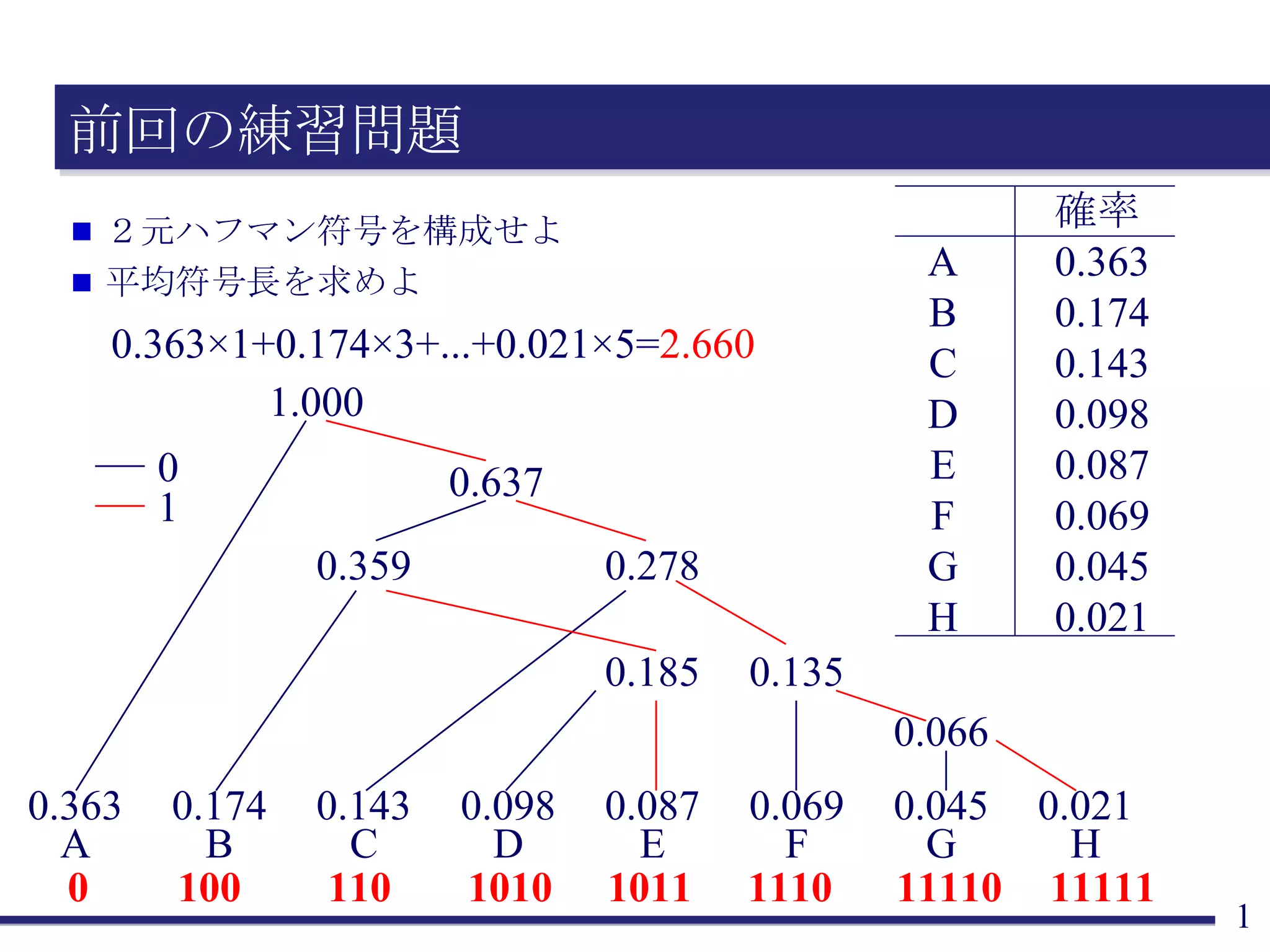
前回の練習問題 2元ハフマン符号を構成せよ 平均符号長を求めよ1.000 0.637 0.359 0.278 0.185 0.135 0.066 0.363 A 0.174 B 0.143 C 0.098 D 0.087 E 0.069 F 0.045 G 0.021 H 0 100 110 1010 1011 1110 11110 11111 0.363 ×1+0.174 ×3+...+0.021×5= 2.660 A B C D E F G H 確率 0.363 0.174 0.143 0.098 0.087 0.069 0.045 0.021 0 1
2.
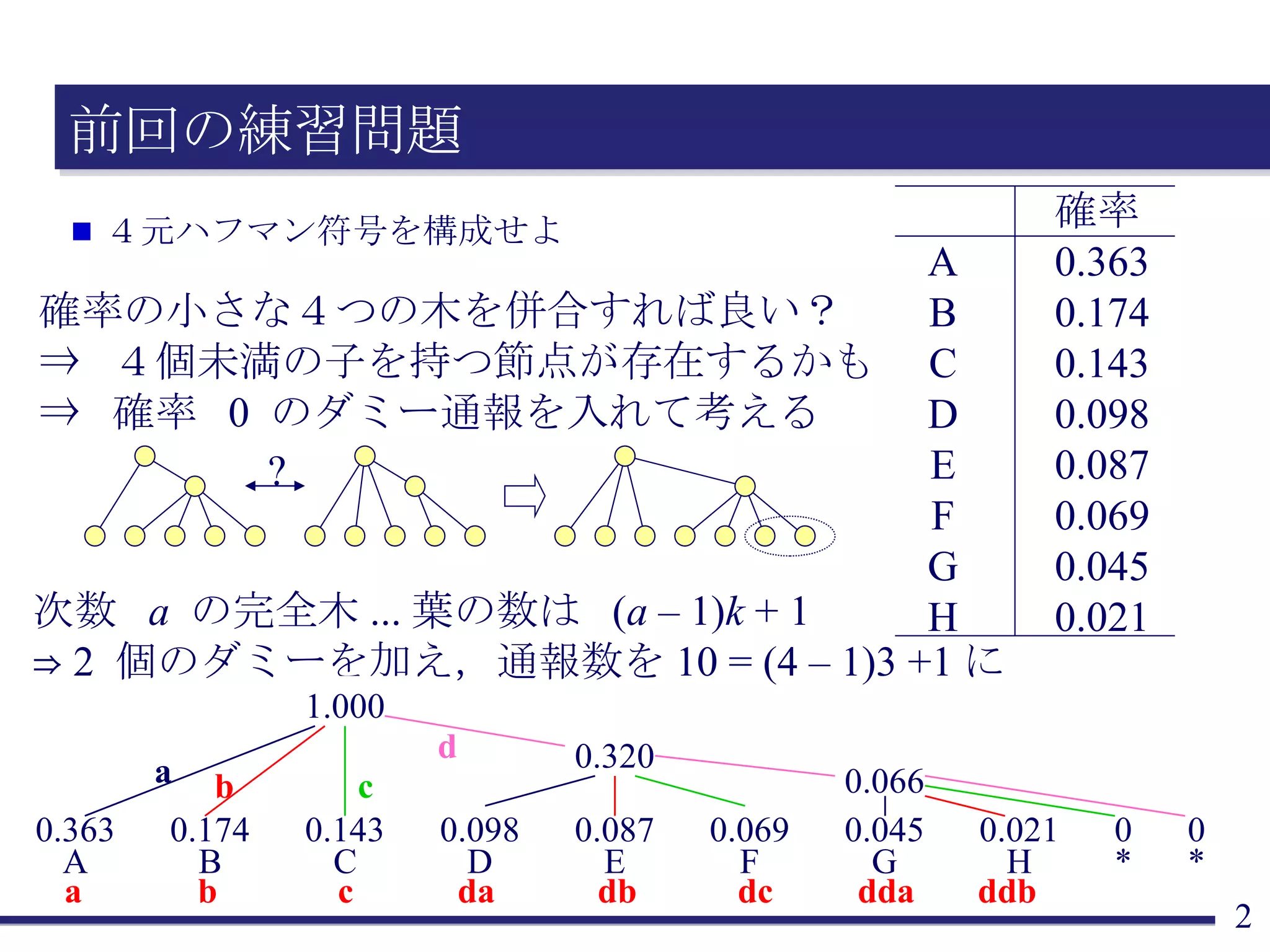
前回の練習問題 4元ハフマン符号を構成せよ 確率の小さな4つの木を併合すれば良い?⇒ 4個未満の子を持つ節点が存在するかも ⇒ 確率 0 のダミー通報を入れて考える ? 次数 a の完全木 ... 葉の数は ( a – 1) k + 1 ⇒ 2 個のダミーを加え,通報数を 10 = (4 – 1)3 +1 に 0.363 A 0.174 B 0.143 C 0.098 D 0.087 E 0.069 F 0.045 G 0.021 H a b c da db dc dda ddb 0 * 0 * 0.066 0.320 1.000 a b c d A B C D E F G H 確率 0.363 0.174 0.143 0.098 0.087 0.069 0.045 0.021
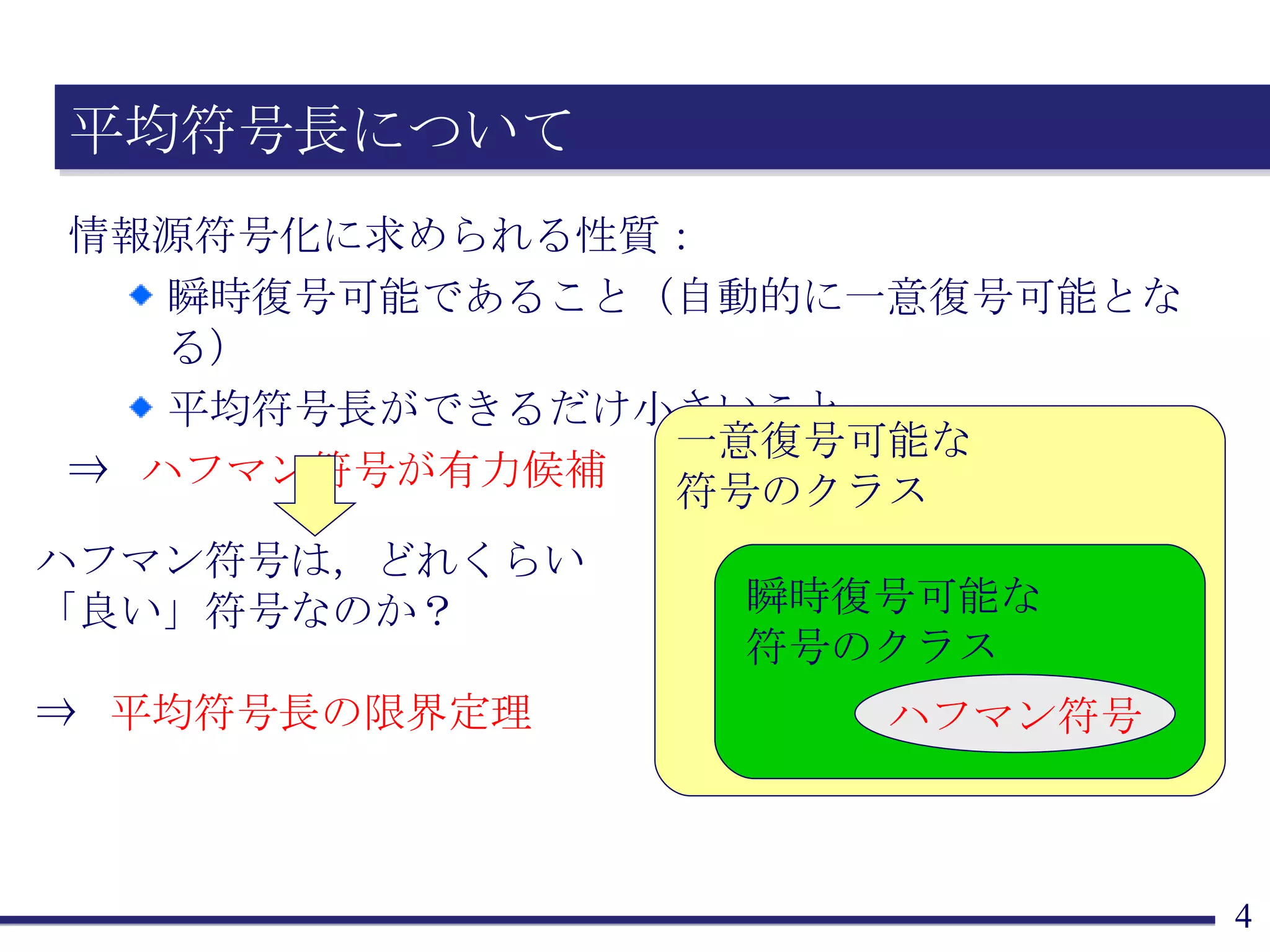
平均符号長の限界定理 定常情報源 S から発生する 通報を一個ずつ , 瞬時復号可能な符号 C により 符号化 することを考える 通報は M 通り,各通報の発生確率は p 1 , ..., p M [ 定理 ] 任意の符号について, 平均符号長は必ず L H 1 ( S ) となる ... どんなに効率的でも,平均符号長は1次エントロピー以下 平均符号長が L < H 1 ( S ) + 1 となる符号を構成できる ... 平均符号長が1次エントロピーに迫る符号を作ることが可能
6.
シャノンの補助定理 定理の証明にあたり,補助定理(補題)をひとつ導入 (シャノンの補助定理 , Shannon’s lemma ) [ 補題 ] q 1 + ... + q M 1 を満たす任意の正数 q 1 , ..., q M に対し, 等号成立は, p 1 = q 1 , ..., p M = q M のとき,かつそのときのみ.
符号長限界定理の証明(前半) C の符号語長をl 1 , ..., l M とし, q i = 2 – li とおく.クラフトの不等式より l i = – log 2 q i なので,平均符号長は シャノンの補助定理を用いて, 等号成立は, p 1 = q 1 , ..., p M = q M のとき,かつそのときのみ (前半証明終了)
9.
符号長限界定理の証明(後半) 以下の不等式を満たすよう,整数 l i を定める. これより 2 – li 2 log pi =p i であり, したがって l 1 , ..., l M はクラフトの不等式を満足し, この符号長を持つ(瞬時に復号可能な)符号を構成可能. この符号の平均符号長は (後半証明終了)
10.
符号長限界定理とハフマン符号 [定理](再掲) 任意の符号について,平均符号長は必ず L H 1 ( S ) となる 平均符号長が L < H 1 ( S ) + 1 となる符号を構成できる ハフマン符号では, 平均符号長が,必ず L < H 1 ( S ) + 1 となる ... 実際には,もっと強い証明が可能 ハフマン符号よりも平均符号長の小さな瞬時符号は存在しない (ハフマン符号は コンパクト符号 ( compact code ) である) 証明は,符号木の大きさに関する帰納法による(以下略).
11.
ハフマン符号とブロック化 ハフマン符号... 一個の通報を,一個の符号語に変換する 平均符号長は,かならず1以上となる 2元情報源の符号化には向かない 複数の通報をまとめて符号化 ( ブロック符号化 )すると ... 通報あたりの平均符号長を1以下にできるかも 2元情報源の符号化にも利用可能 A B 10 A C C 1101 A 01 A 0 B 10 A 0 C 11 C 11 A 0 通報 A B 平均符号長 確率 0.8 0.2 C 1 0 1 1.0 C 2 1 0 1.0
12.
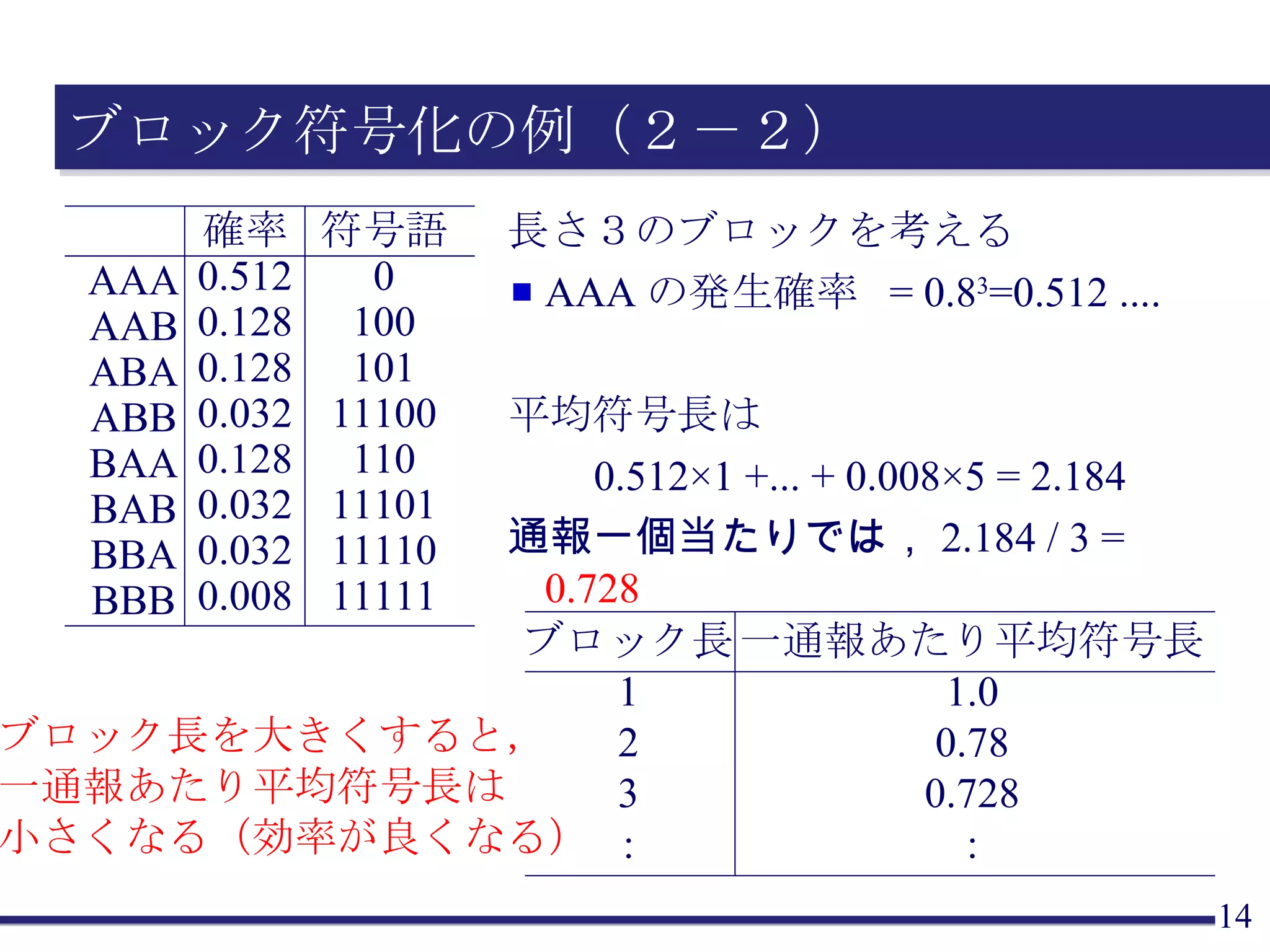
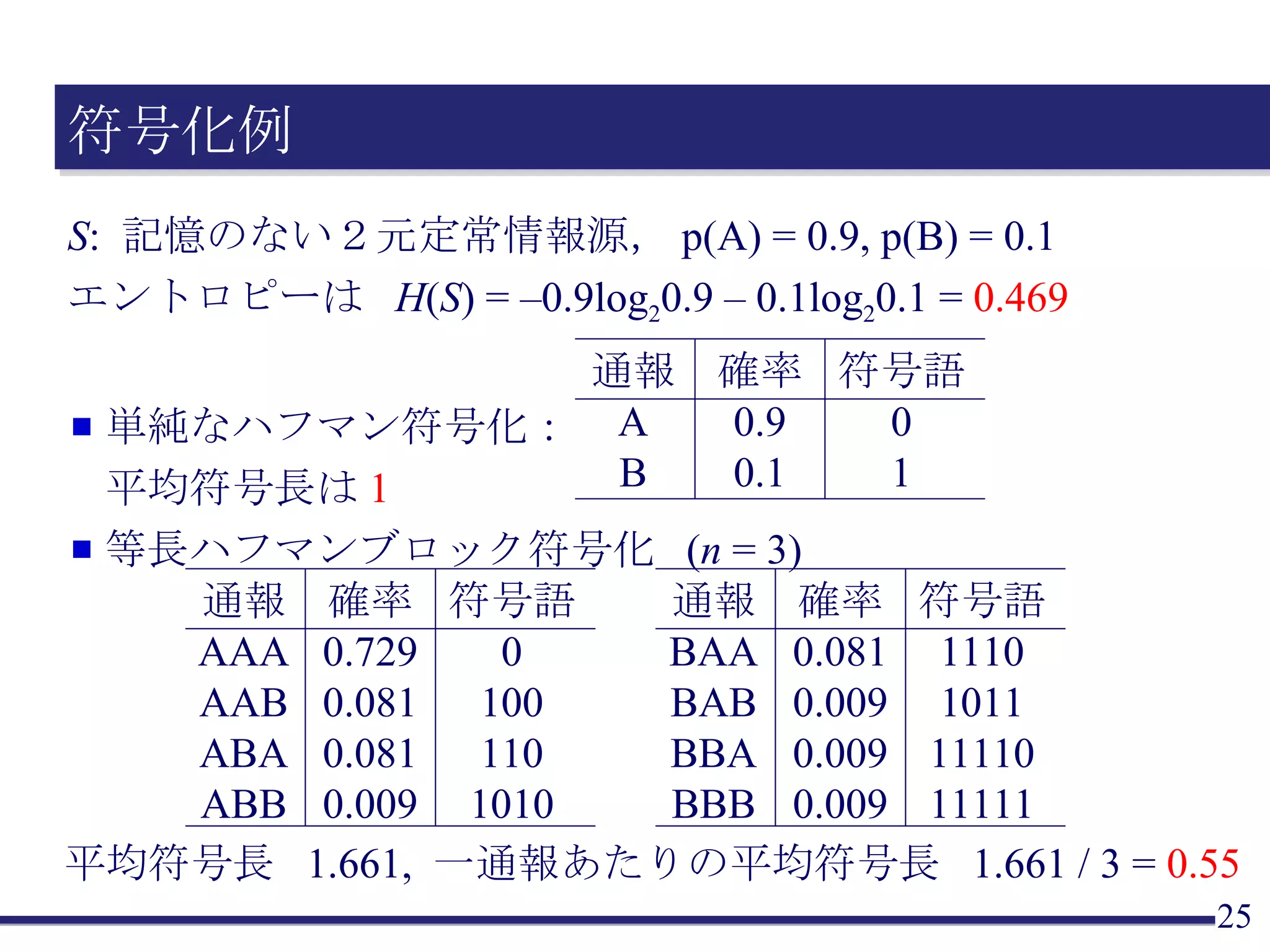
ブロック符号化の例(1) 左表のとおりハフマン符号化をすると, 平均符号長は0.6 ×1 + 0.3×2 + 0.1×2 = 1.4 長さ2のブロックを考える AA の発生確率 = 0.6 ×0.6=0.36 .... 左表のとおりハフマン符号化をすると, 平均符号長は 0.36 ×1 + 0.18×3 + ... + 0.01×6 = 2.67 通報一個当たりでは, 2.67 / 2 = 1.335 ⇒ 少し効率が良くなった A B C 確率 0.6 0.3 0.1 符号語 0 10 11 AA AB AC BA BB BC CA CB CC 確率 0.36 0.18 0.06 0.18 0.09 0.03 0.06 0.03 0.01 符号語 0 100 1100 101 1110 11110 1101 111110 111111
13.
ブロック符号化の例(2-1) 平均符号長は 0.8×1+ 0. 2×1 = 1.0 長さ2のブロックを考える AA の発生確率 = 0.8 ×0.8=0.64 .... 平均符号長は 0.64 ×1 + 0.16×2 + ... + 0.04×3 = 1.56 通報一個当たりでは, 1.56 / 2 = 0.78 ⇒ 2元情報源でも,効率改善 A B 確率 0.8 0.2 符号語 0 1 AA AB BA BB 確率 0.64 0.16 0.16 0.04 符号語 0 10 110 111
ブロック符号の平均符号長 ブロック長を大きくすると,一通報あたり平均符号長は小さくなる ⇒ どこまで小さくなるのか? n 個単位でブロック化された通報= n 次拡大情報源 S n の通報1個 ⇒ 平均符号長の限界定理が適用できる! ブロック符号の平均符号長を L n とすると, H 1 ( S n ) L n < H 1 ( S n )+1 . 一通報当たりの平均符号長に換算すると ...
16.
シャノンの情報源符号化定理 H 1( S n ) / n は,情報源 S の n 次拡大エントロピー n -> ∞のとき, H 1 ( S n ) / n -> H ( S )...情報源 S の極限エントロピー 1 / n -> 0 [ シャノンの情報源符号化定理 ] 情報源 S から発生する通報は,一通報あたりの平均符号長が H ( S ) L < H ( S ) + である瞬時復号可能な符号に符号化可能
17.
情報源符号化定理の意味するところ 情報源 Sから発生する通報は,一通報あたりの平均符号長が H ( S ) L < H ( S ) + である瞬時復号可能な符号に符号化可能 ブロック長を長くしてハフマン符号を使えば,効率的にはベスト どれだけ頑張っても,極限エントロピーの壁は越えられない ブロック長 1 2 3 : : 一通報あたり平均符号長 1.0 0.78 0.728 : : 0.723 + H ( S ) = 0.723 A B 確率 0.8 0.2 符号語 0 1
非等長ブロック符号化 ここまでのブロック符号化:符号化対象のパターンは同じ長さ ⇒発生確率の非常に小さなパターンにも符号語定義が必要 ⇒ 対応表の巨大化 符号化対象のパターンが,異なる長さを持つことを許す ⇒ 非等長 ( unequal-length ) ブロック化.ただし 各パターンの 発生確率が,ある程度均衡 すること 任意の通報系列が,パターンにブロック化できる こと ...どのようにパターンを定義するかが鍵となる A B A A B A B A A B A A B A B A
20.
パターンの定義方法について パターン定義の戦略1:頻出パターンの細分化 長さ1のパターンを用意する発生頻度の高いパターンを細分化し,分割する 所望のパターン数になるまで 2 を繰り返す 例:P(A) = 0.8, P(B) = 0.2,所望パターン数4のとき 任意の系列を, {AAA, AAB, AB, B} にブロック化可能 A B 0.8 0.2 AA AB B 0.64 0.16 0.2 AAA AAB AB B 0.512 0.128 0.16 0.2
21.
非等長ブロック化時の平均符号長 前スライドのパターンに対し, ハフマン符号を定義(右表)n 個のブロックがあったとすると ... 符号語系列の長さ は 0.512 n ×1 + 0.128 n ×3 + 0.16 n ×3 + 0.2 n ×1 = 1.776 n 通報系列の長さ は 0.512 n ×3 + 0.128 n ×3 + 0.16 n ×2 + 0.2 n ×1 = 2.44 n 一通報あたりの符号長は, 1.776 n / 2.44 n = 0.728 ... ブロック長3(対応表8行)のときと同程度の効率 (cf. p.14) パターン AAA AAB AB B 確率 0.512 0.128 0.16 0.2 符号語 0 100 101 11
22.
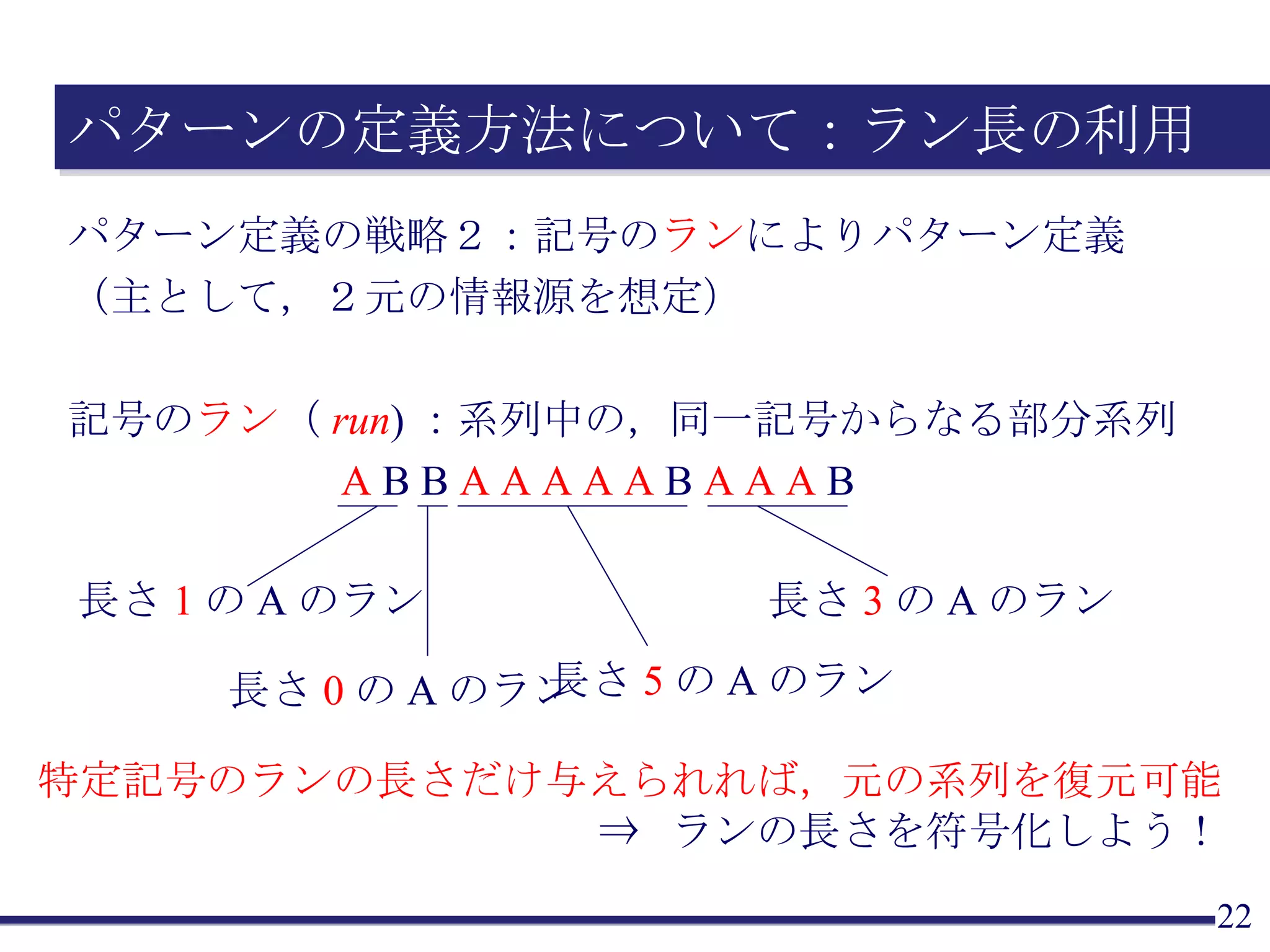
パターンの定義方法について:ラン長の利用 パターン定義の戦略2:記号の ランによりパターン定義 (主として,2元の情報源を想定) 記号の ラン ( run ):系列中の,同一記号からなる部分系列 特定記号のランの長さだけ与えられれば,元の系列を復元可能 ⇒ ランの長さを符号化しよう! A B B A A A A A B A A A B 長さ 1 の A のラン 長さ 5 の A のラン 長さ 3 の A のラン 長さ 0 の A のラン
23.
ラン長の上限 非常に長いランが発生することも ...⇒ ランの長さに上限を設け,上限以上のランは短く分割して表現 ABBAAAAABAAAB を表現する: A が 1個 発生し,Bが発生 A が 0個 発生し,Bが発生 A が 3個以上 発生 A が 2個 発生し,Bが発生 A が 3個以上 発生 A が 0個 発生し,Bが発生 上限を3とした場合 ラン長 0 1 2 3 4 5 6 7 : 表現方法 0 1 2 3+0 3+1 3+1 3+3+0 3+3+1 :


![平均符号長の限界定理 定常情報源 S から発生する 通報を一個ずつ , 瞬時復号可能な符号 C により 符号化 することを考える 通報は M 通り,各通報の発生確率は p 1 , ..., p M [ 定理 ] 任意の符号について, 平均符号長は必ず L H 1 ( S ) となる ... どんなに効率的でも,平均符号長は1次エントロピー以下 平均符号長が L < H 1 ( S ) + 1 となる符号を構成できる ... 平均符号長が1次エントロピーに迫る符号を作ることが可能](https://image.slidesharecdn.com/4-090331082425-phpapp01/75/4-Info-Theory-5-2048.jpg)
![シャノンの補助定理 定理の証明にあたり,補助定理(補題)をひとつ導入 ( シャノンの補助定理 , Shannon’s lemma ) [ 補題 ] q 1 + ... + q M 1 を満たす任意の正数 q 1 , ..., q M に対し, 等号成立は, p 1 = q 1 , ..., p M = q M のとき,かつそのときのみ.](https://image.slidesharecdn.com/4-090331082425-phpapp01/75/4-Info-Theory-6-2048.jpg)



 任意の符号について, 平均符号長は必ず L H 1 ( S ) となる 平均符号長が L < H 1 ( S ) + 1 となる符号を構成できる ハフマン符号では, 平均符号長が,必ず L < H 1 ( S ) + 1 となる ... 実際には,もっと強い証明が可能 ハフマン符号よりも平均符号長の小さな瞬時符号は存在しない (ハフマン符号は コンパクト符号 ( compact code ) である) 証明は,符号木の大きさに関する帰納法による(以下略).](https://image.slidesharecdn.com/4-090331082425-phpapp01/75/4-Info-Theory-10-2048.jpg)




![シャノンの情報源符号化定理 H 1 ( S n ) / n は,情報源 S の n 次拡大エントロピー n -> ∞のとき, H 1 ( S n ) / n -> H ( S )...情報源 S の極限エントロピー 1 / n -> 0 [ シャノンの情報源符号化定理 ] 情報源 S から発生する通報は,一通報あたりの平均符号長が H ( S ) L < H ( S ) + である瞬時復号可能な符号に符号化可能](https://image.slidesharecdn.com/4-090331082425-phpapp01/75/4-Info-Theory-16-2048.jpg)












![[CVPR読み会]BING:Binarized normed gradients for objectness estimation at 300fps](https://cdn.slidesharecdn.com/ss_thumbnails/bing-140725194514-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![集中不等式のすすめ [集中不等式本読み会#1]](https://cdn.slidesharecdn.com/ss_thumbnails/concentrationintro-150128034517-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Deep Learning 第3章 確率と情報理論](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning3-180601014703-thumbnail.jpg?width=640&height=640&fit=bounds)












































