Download to read offline







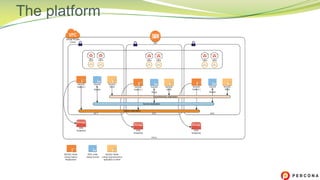

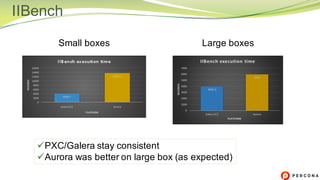
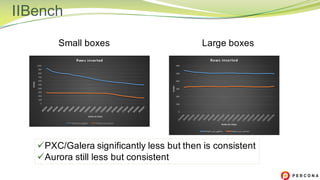
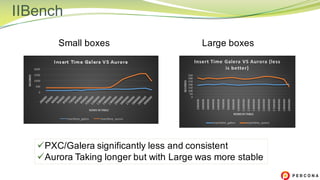
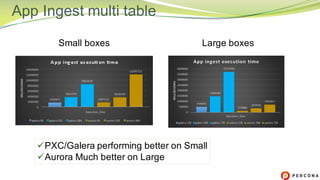


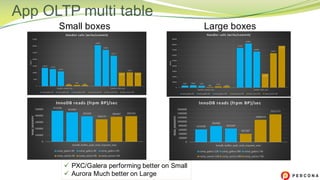
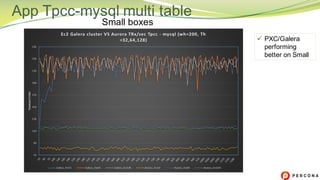
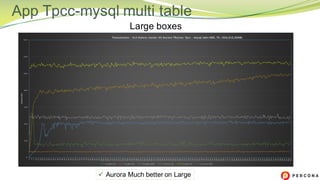
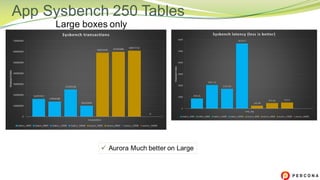
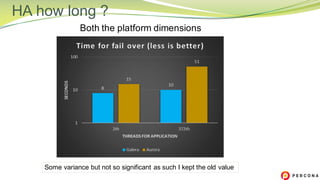
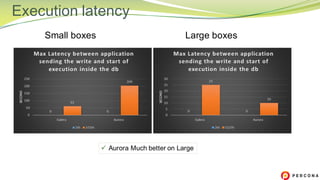

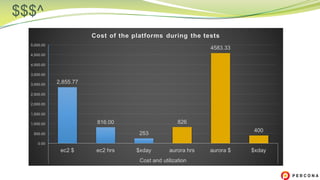



The document is a comparative analysis of synchronous replication solutions in cloud environments, focusing on tests conducted by Marco Tusa using AWS services like EC2, PXC, and Aurora. It discusses performance implications based on workloads and machine sizes, noting that PXC performs better for smaller installations while Aurora excels in larger setups, albeit with some known limitations. The author also encourages exploring alternatives to enhance offerings for customers.



















































































