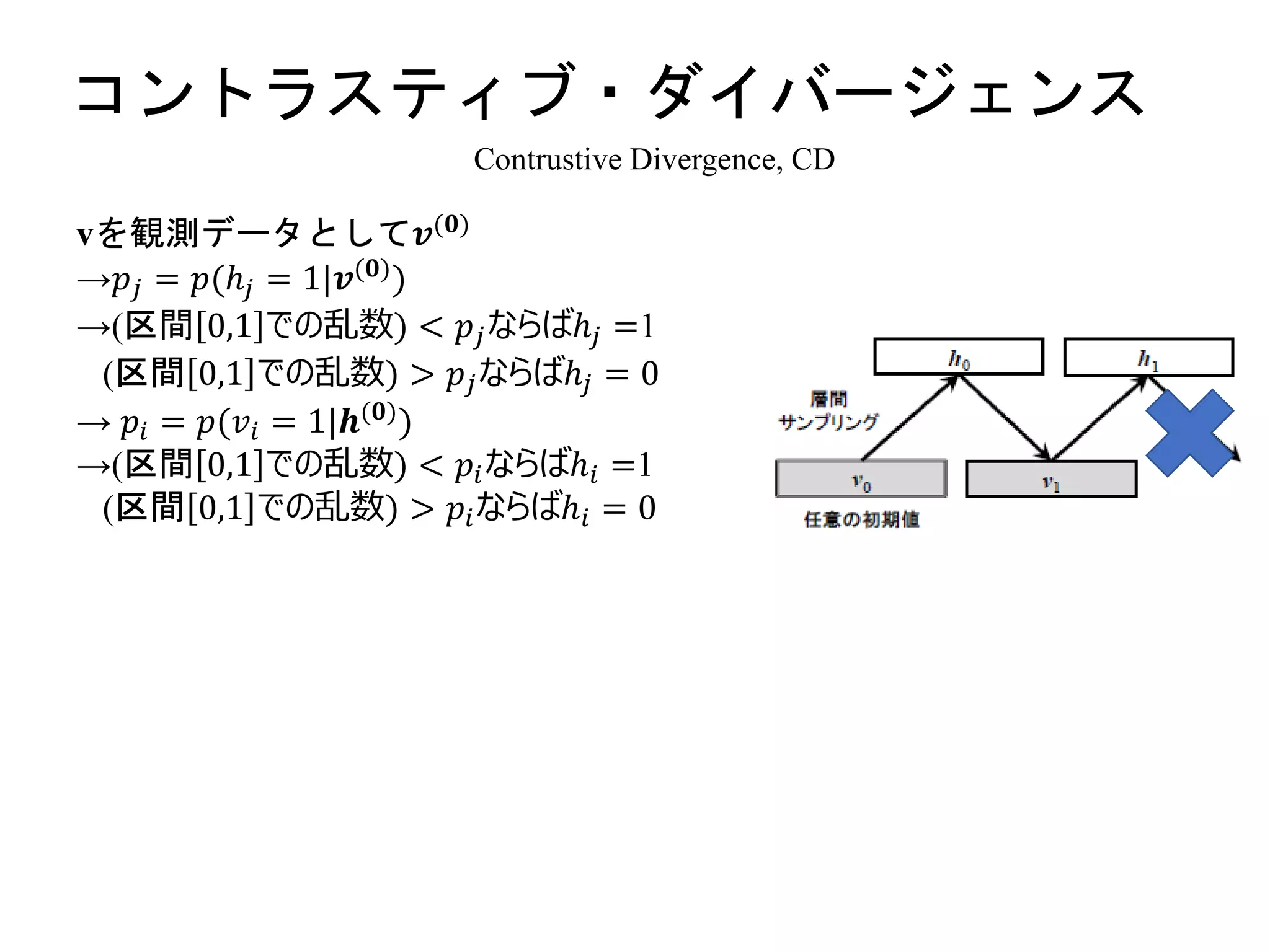
More Related Content

PPTX

PDF

PDF

PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料) 
PDF
確率的深層学習における中間層の改良と高性能学習法の提案 
PDF
Chapter 8 ボルツマンマシン - 深層学習本読み会 
PDF

PPTX
What's hot

PPTX

PPTX
MCMC and greta package社内勉強会用スライド 
PDF
20110109第8回CV勉強会(ミーンシフトの原理と応用:6章・7章)shirasy) 
PDF

PDF

PDF
Prml Reading Group 10 8.3 
PDF

PPTX

PDF
第8回関西CV・PRML勉強会(Meanshift) 
PPTX
M1gp -Who’s (Not) Talking to Whom?- 
PDF
論文紹介:Using the Forest to See the Trees: A Graphical. Model Relating Features,... 
PDF
Probabilistic Graphical Models 輪読会 #1 
PPTX
![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第1章:序論) 
PDF

PDF

PDF
![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル) 
PPTX

PDF
Similar to Statistical machine learning

PPTX

PDF
Implement for Deep Learning of RBM Network in C. 
PDF

PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~ 
PDF

PPTX

PDF

PDF

PPTX
Deep learning basics described 
PDF

PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計 
PPTX

PDF
Learning Deep Architectures for AI (第 3 回 Deep Learning 勉強会資料; 松尾) 
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2) 
PDF
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw... 
PDF

PDF

PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ 
PDF
Statistical machine learning
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
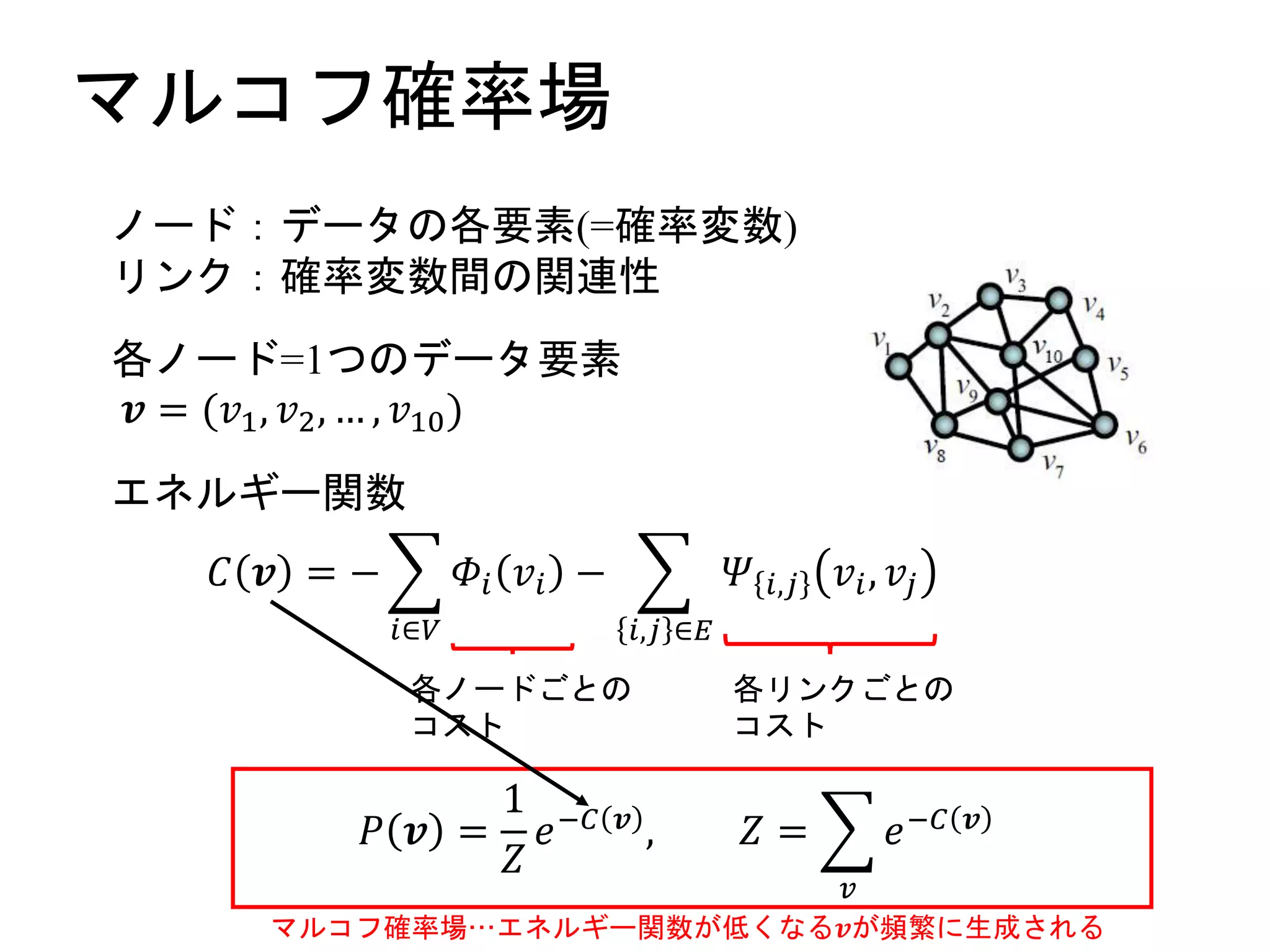
マルコフ確率場
エネルギー関数
𝐶 𝒗 =−
𝑖∈𝑉
𝛷𝑖 𝑣𝑖 −
𝑖,𝑗 ∈𝐸
𝛹 𝑖,𝑗 𝑣𝑖, 𝑣𝑗
各ノードごとの
コスト
各リンクごとの
コスト
𝑃 𝒗 =
1
𝑍
𝑒−𝐶 𝒗 , 𝑍 =
𝑣
𝑒−𝐶 𝒗
マルコフ確率場…エネルギー関数が低くなる𝒗が頻繁に生成される
ノード:データの各要素(=確率変数)
リンク:確率変数間の関連性
各ノード=1つのデータ要素
𝒗 = (𝑣1, 𝑣2, … , 𝑣10)
- 9.
- 10.
- 11.
- 12.
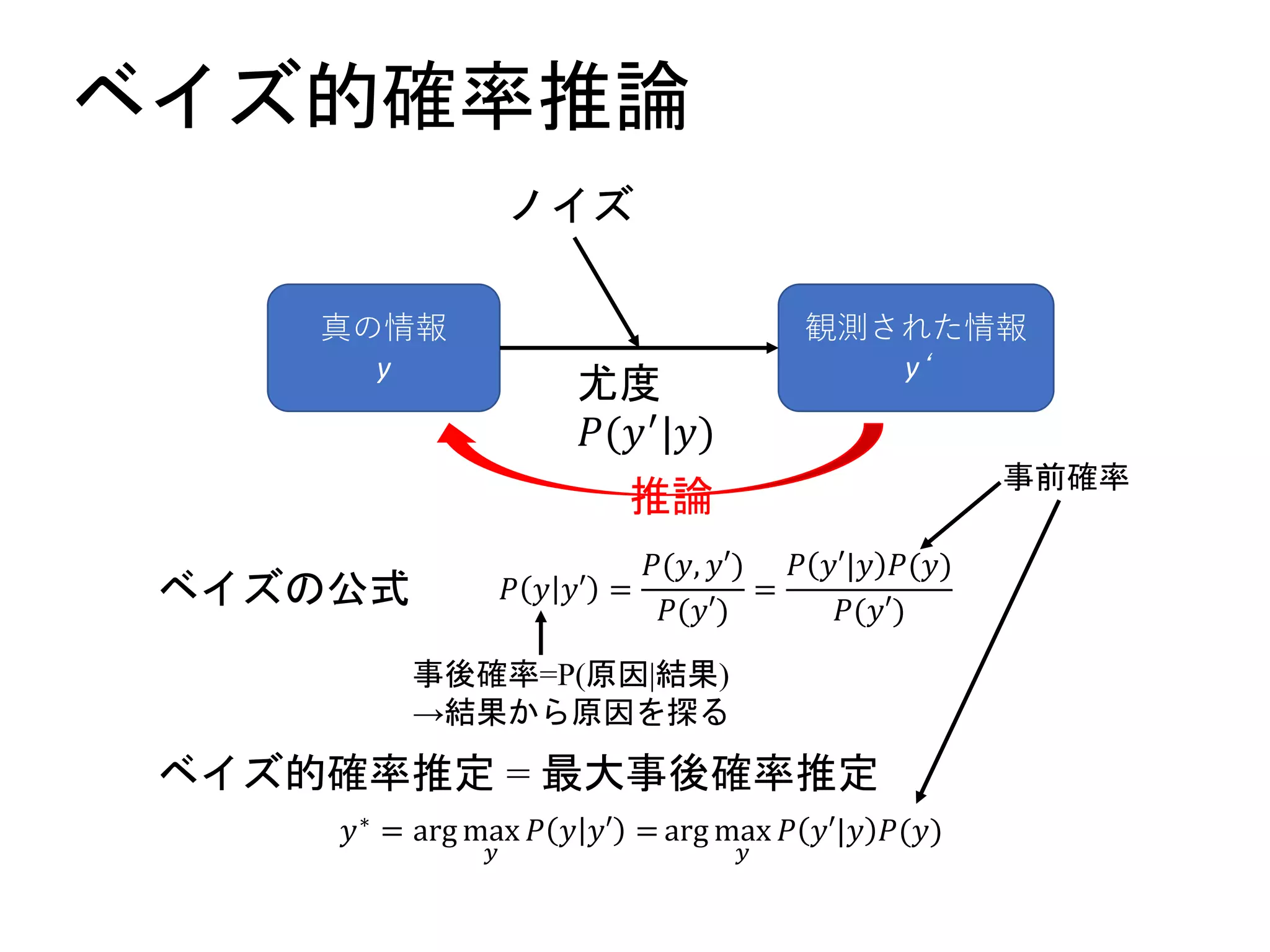
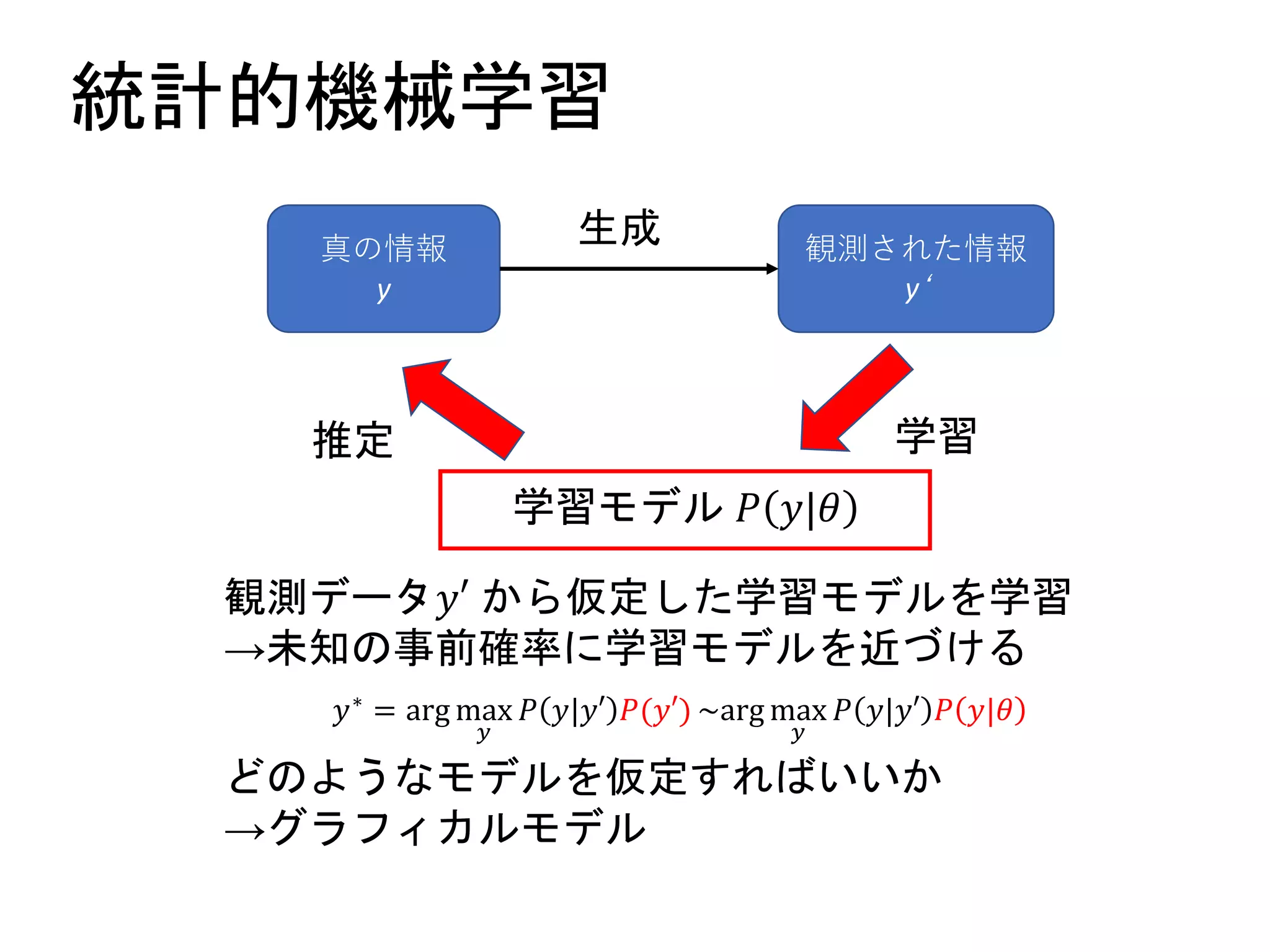
最尤推定(maximum likelihood estimation,MLE)
𝐷 = 𝒅(1), 𝒅(2), … , 𝒅(𝑁) , 𝒅(𝜇) = 𝑑1
(𝜇)
, 𝑑2
(𝜇)
, … , 𝑑 𝑛
(𝜇)
として、観測データと同じn次元の変数を持つBM
𝑃 𝒚|𝜽 𝒚 = 𝑣1, 𝑣2, … , 𝑣 𝑛
を作成すると、観測データ群Dを生成する確率は、
𝑃 𝒚 = 𝒅 1 𝜽 𝑃 𝒚 = 𝒅 2 𝜽 … 𝑃 𝒚 = 𝒅 𝑁 𝜽
※各データ𝒅(𝜇)
は独立に生成される
・尤度関数=仮定した学習モデルが実際に観測データを
生成する確率
→観測データに対して一番尤もらしいモデル=尤度関数
を最大とするパラメター値の時のモデル
→これを求めるのが最尤推定
=尤度関数
- 13.
- 14.
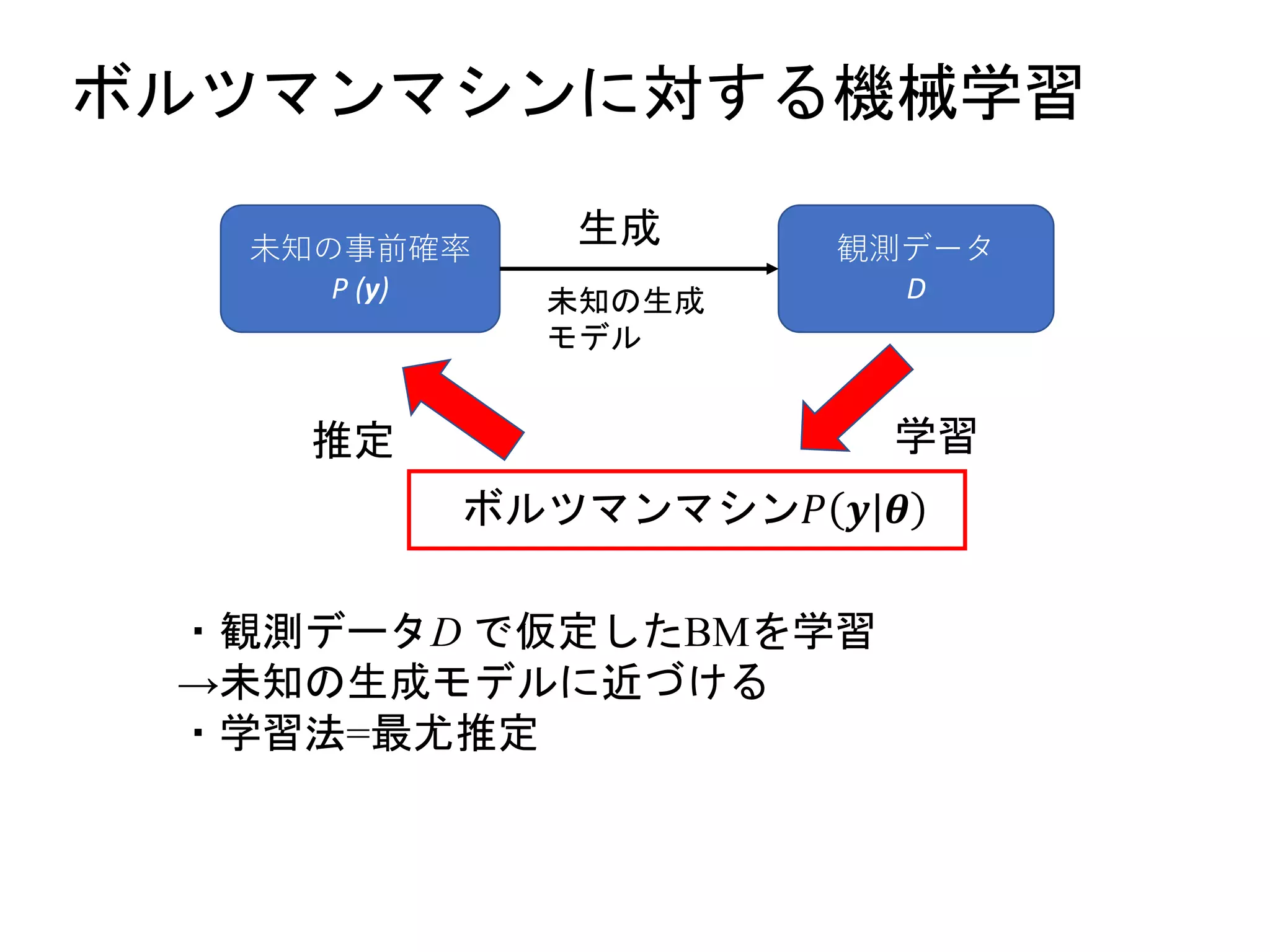
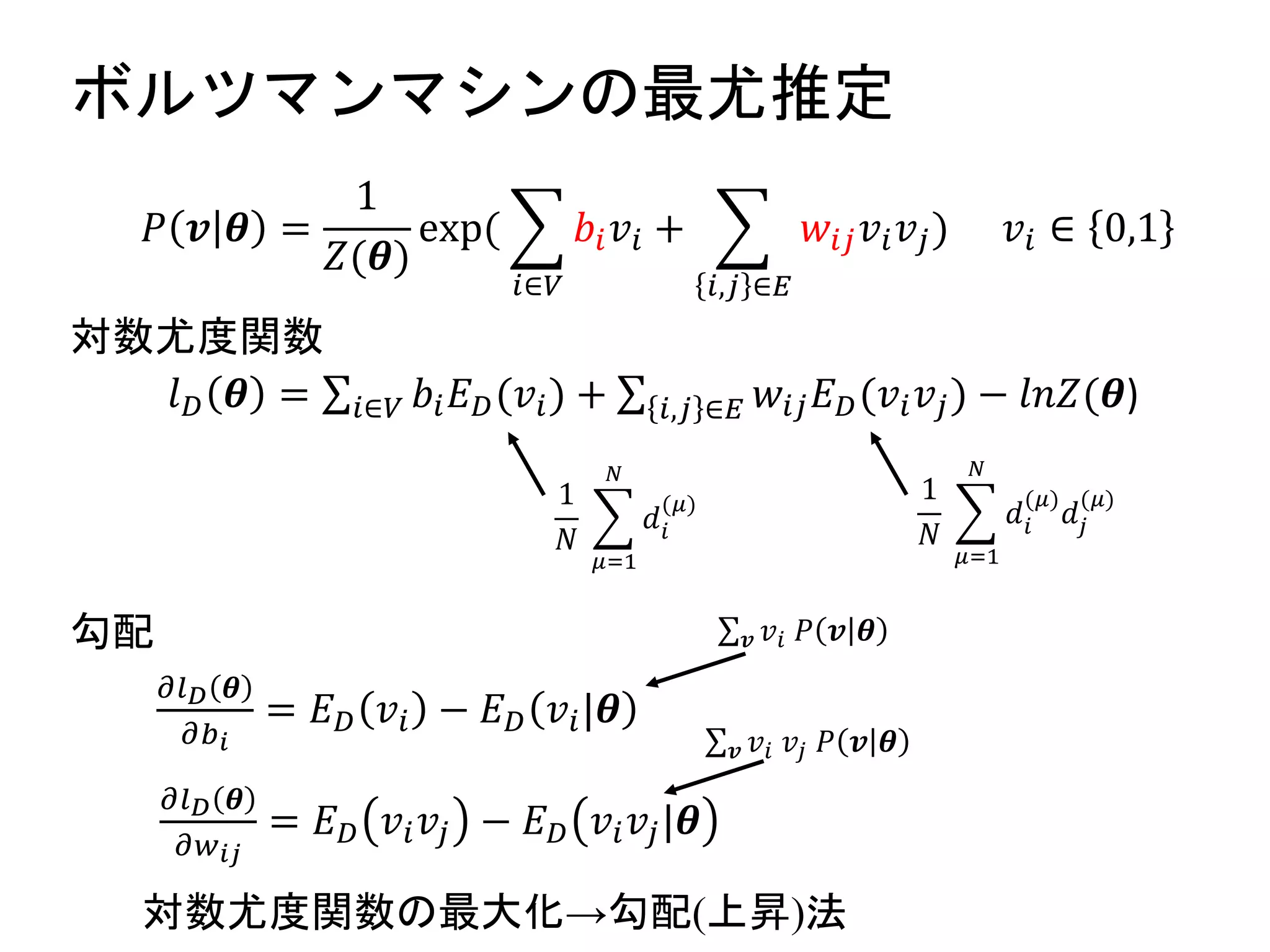
ボルツマンマシンの最尤推定
𝑙 𝐷 𝜽= 𝑖∈𝑉 𝑏𝑖 𝐸 𝐷(𝑣𝑖) + 𝑖,𝑗 ∈𝐸 𝑤𝑖𝑗 𝐸 𝐷(𝑣𝑖 𝑣𝑗) − 𝑙𝑛𝑍(𝜽)
𝑃 𝒗 𝜽 =
1
𝑍(𝜽)
exp(
𝑖∈𝑉
𝑏𝑖 𝑣𝑖 +
𝑖,𝑗 ∈𝐸
𝑤𝑖𝑗 𝑣𝑖 𝑣𝑗) 𝑣𝑖 ∈ 0,1
勾配
対数尤度関数
1
𝑁
𝜇=1
𝑁
𝑑𝑖
(𝜇)
1
𝑁
𝜇=1
𝑁
𝑑𝑖
(𝜇)
𝑑𝑗
(𝜇)
𝜕𝑙 𝐷 𝜽
𝜕𝑏 𝑖
= 𝐸 𝐷 𝑣𝑖 − 𝐸 𝐷 𝑣𝑖|𝜽
𝜕𝑙 𝐷 𝜽
𝜕𝑤 𝑖𝑗
= 𝐸 𝐷 𝑣𝑖 𝑣𝑗 − 𝐸 𝐷 𝑣𝑖 𝑣𝑗|𝜽
𝒗 𝑣𝑖 𝑃 𝒗 𝜽
𝒗 𝑣𝑖 𝑣𝑗 𝑃 𝒗 𝜽
対数尤度関数の最大化→勾配(上昇)法
- 15.
勾配上昇法
𝑥 𝑛𝑒𝑤 ←𝑥 𝑜𝑙𝑑 + 𝜀
𝜕𝑓(𝑥 𝑜𝑙𝑑)
𝜕𝑥
BMの更新式
勾配
𝜀: 小さい正の数(学習率) 𝑥
𝑓
初期値
勾配0で学習終了
更新
𝑏𝑖
𝑛𝑒𝑤
← 𝑏𝑖
𝑜𝑙𝑑
+𝜀(𝐸 𝐷 𝑣𝑖 − 𝐸 𝐷 𝑣𝑖|𝜽 𝑜𝑙𝑑 )
𝑤𝑖𝑗
𝑛𝑒𝑤 ← 𝑤𝑖𝑗
𝑜𝑙𝑑 +𝜀(𝐸 𝐷 𝑣𝑖 𝑣𝑗 − 𝐸 𝐷 𝑣𝑖 𝑣𝑗|𝜽 𝑜𝑙𝑑 )
- 16.
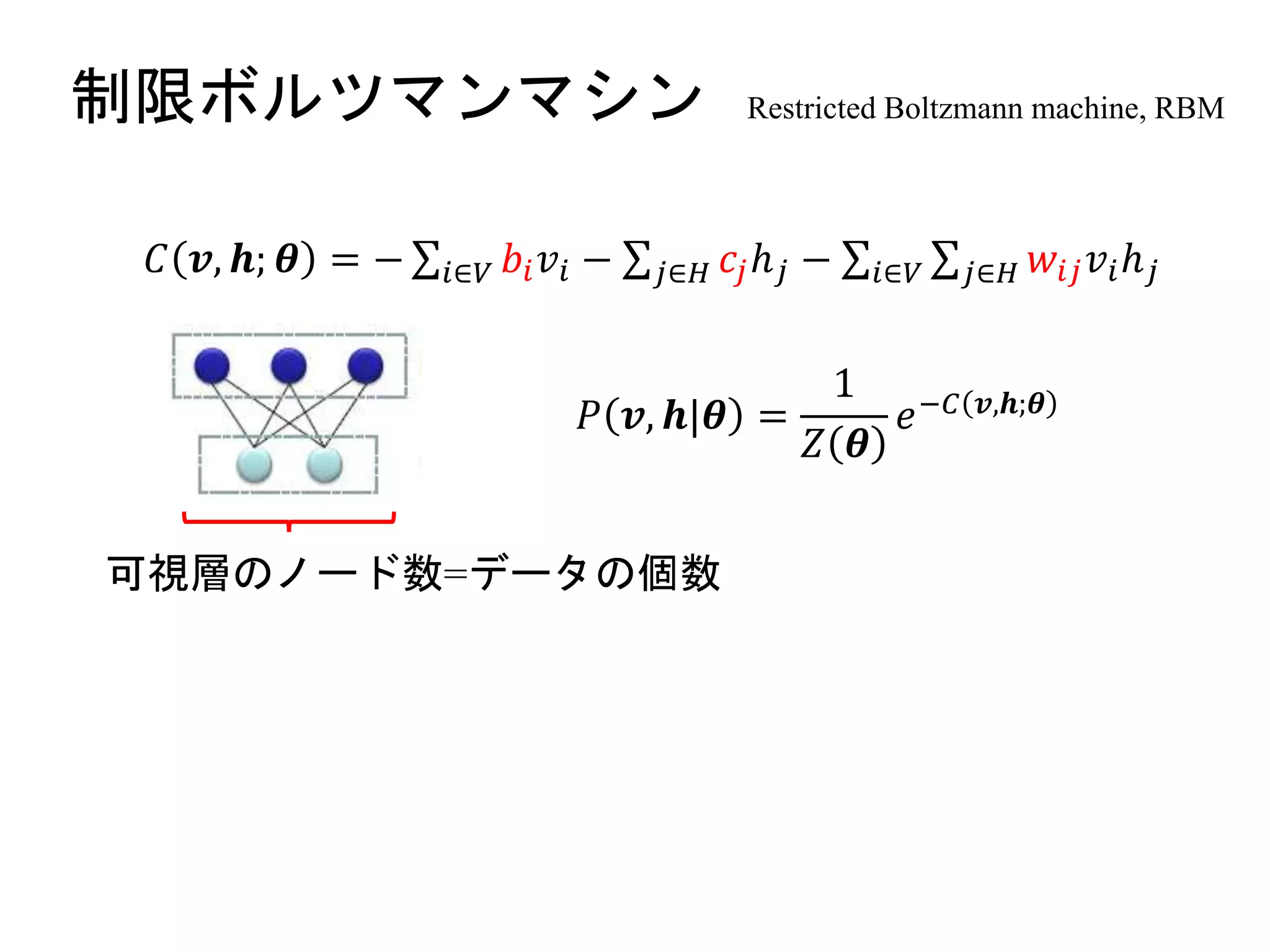
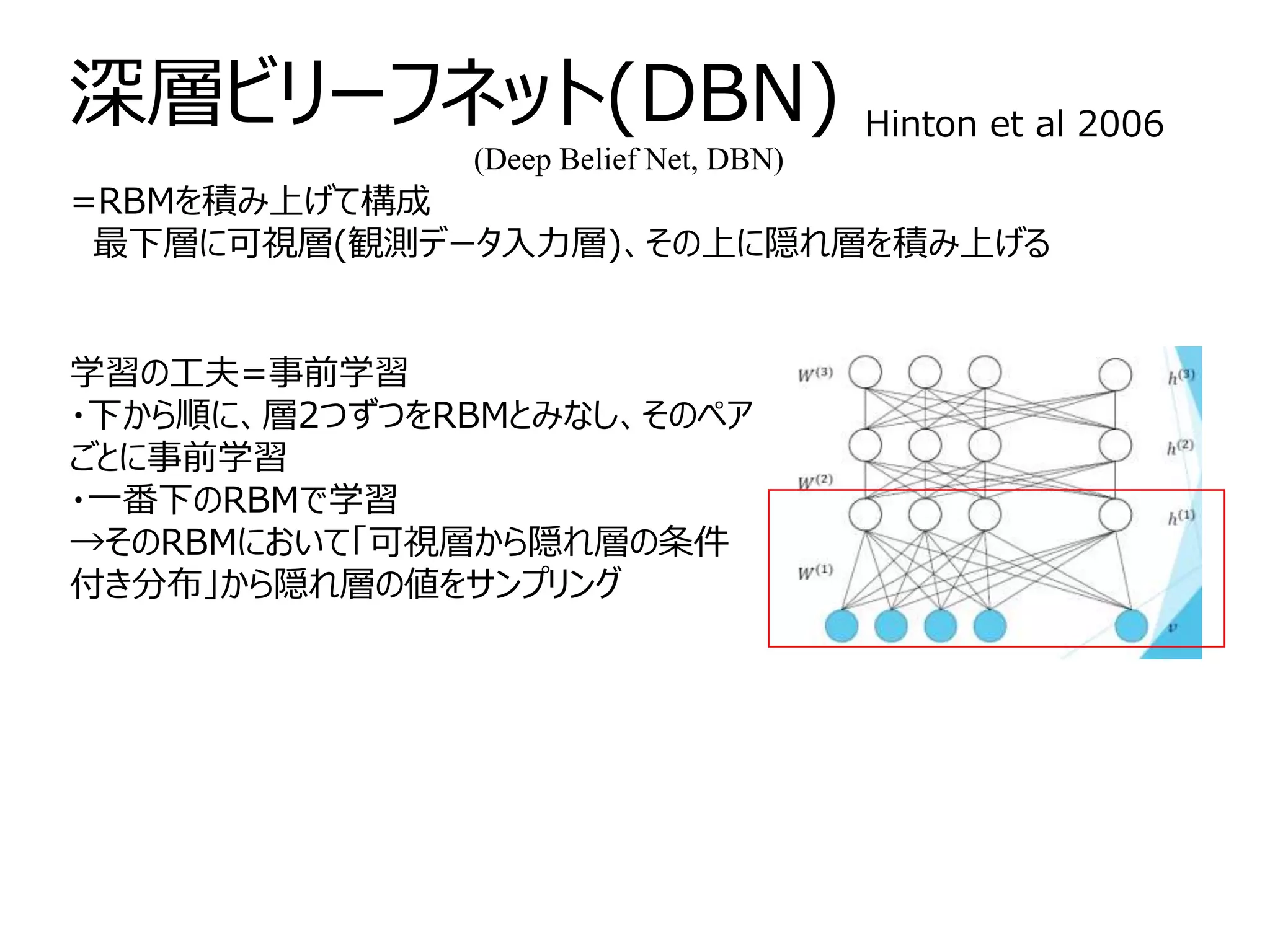
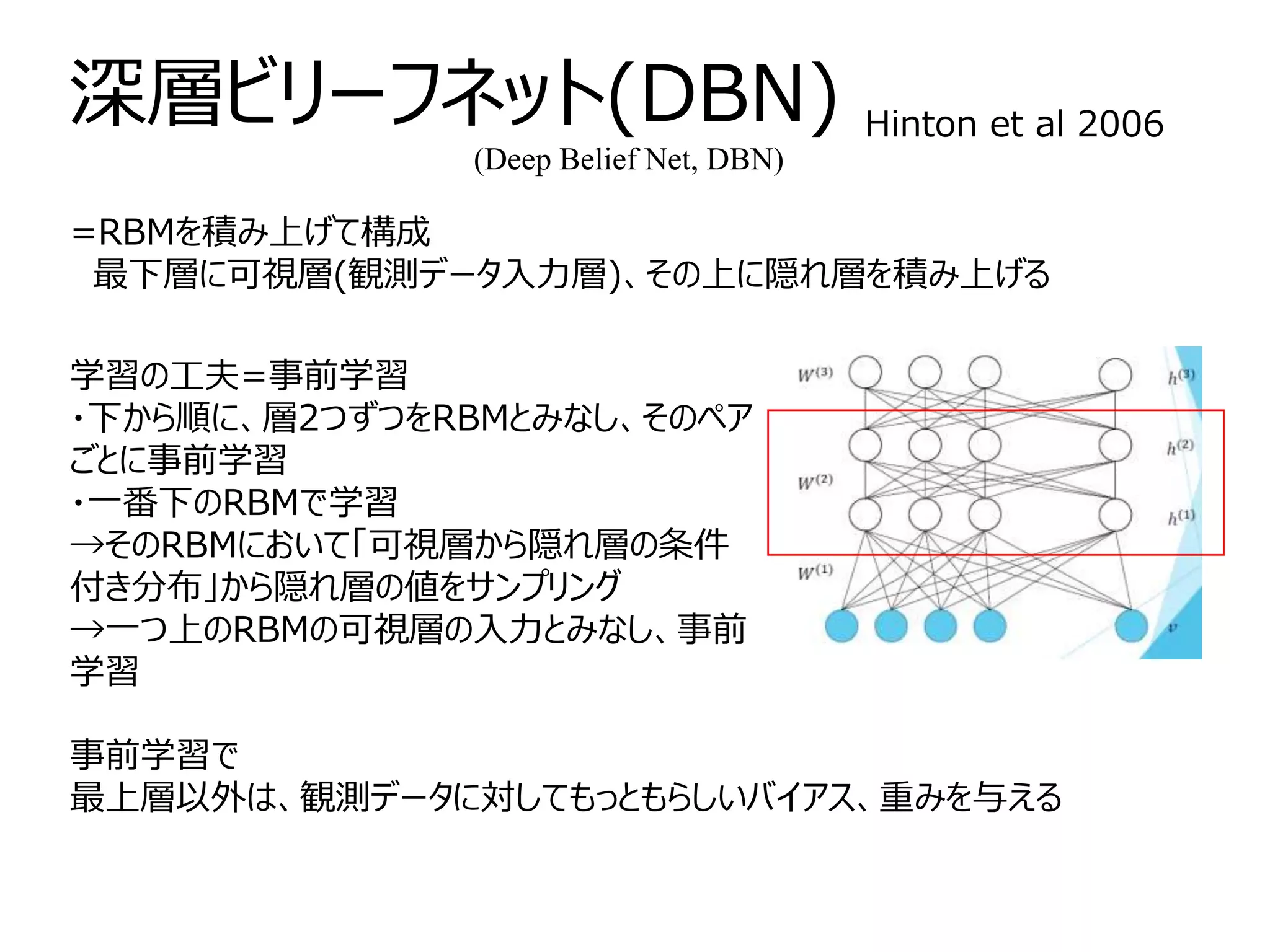
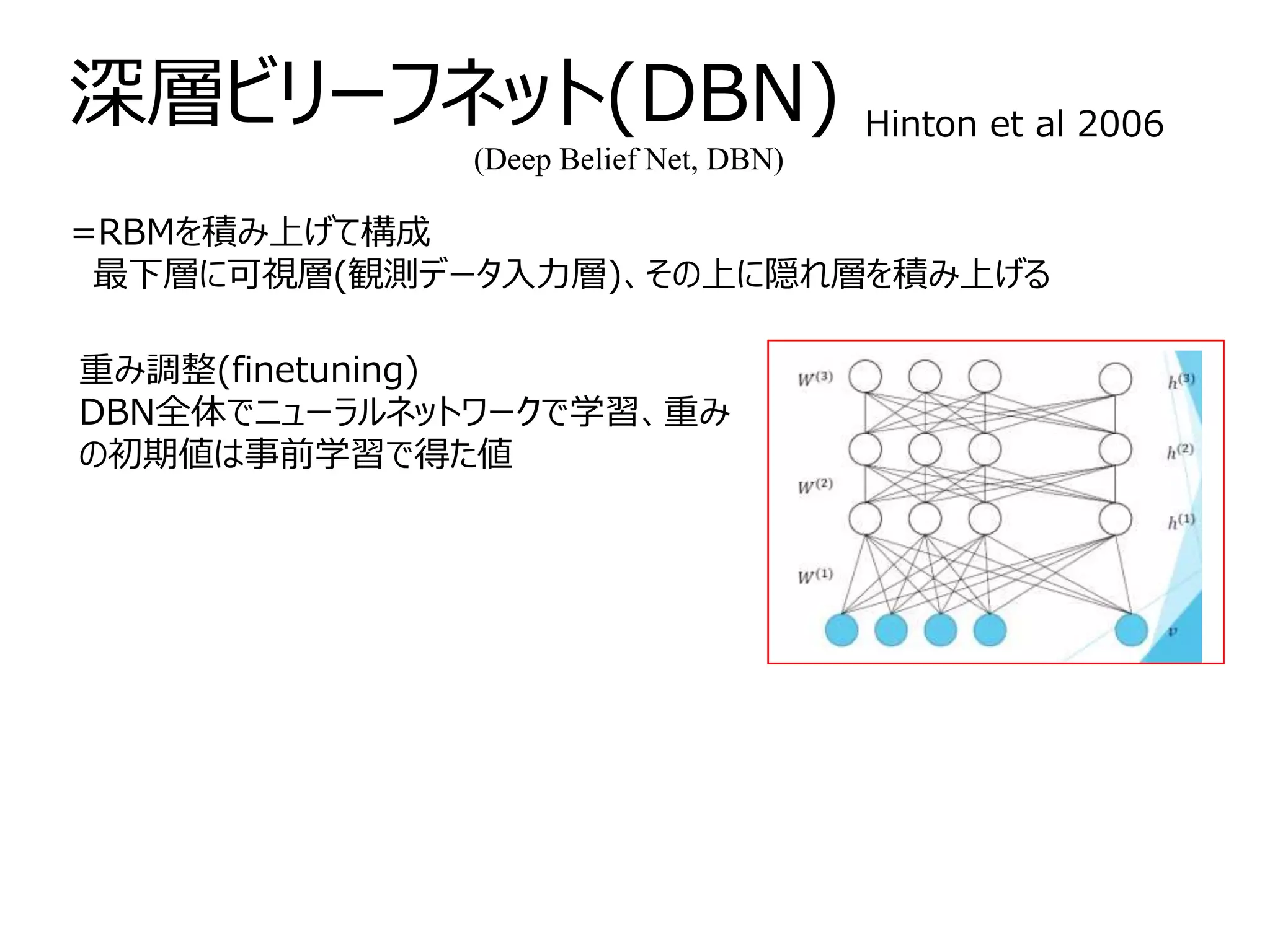
制限ボルツマンマシン Restricted Boltzmannmachine, RBM
ボルツマンマシンに
・「隠れ変数」を導入
→最尤推定時の目的関数に隠れ変数に関して周辺化した可視関数
のみの分布
・制約を加える。
=可視ノード同士、隠れノード同士のリンク無し(層内結合無し)
→・可視ノードのみからなる可視層、隠れノードのみからなる隠
れ層の2つの層
・可視層内、隠れ層内の変数が互いに影響しない(条件付き独立)
深層学習の基本単位
- 17.
- 18.
制限ボルツマンマシン Restricted Boltzmannmachine, RBM
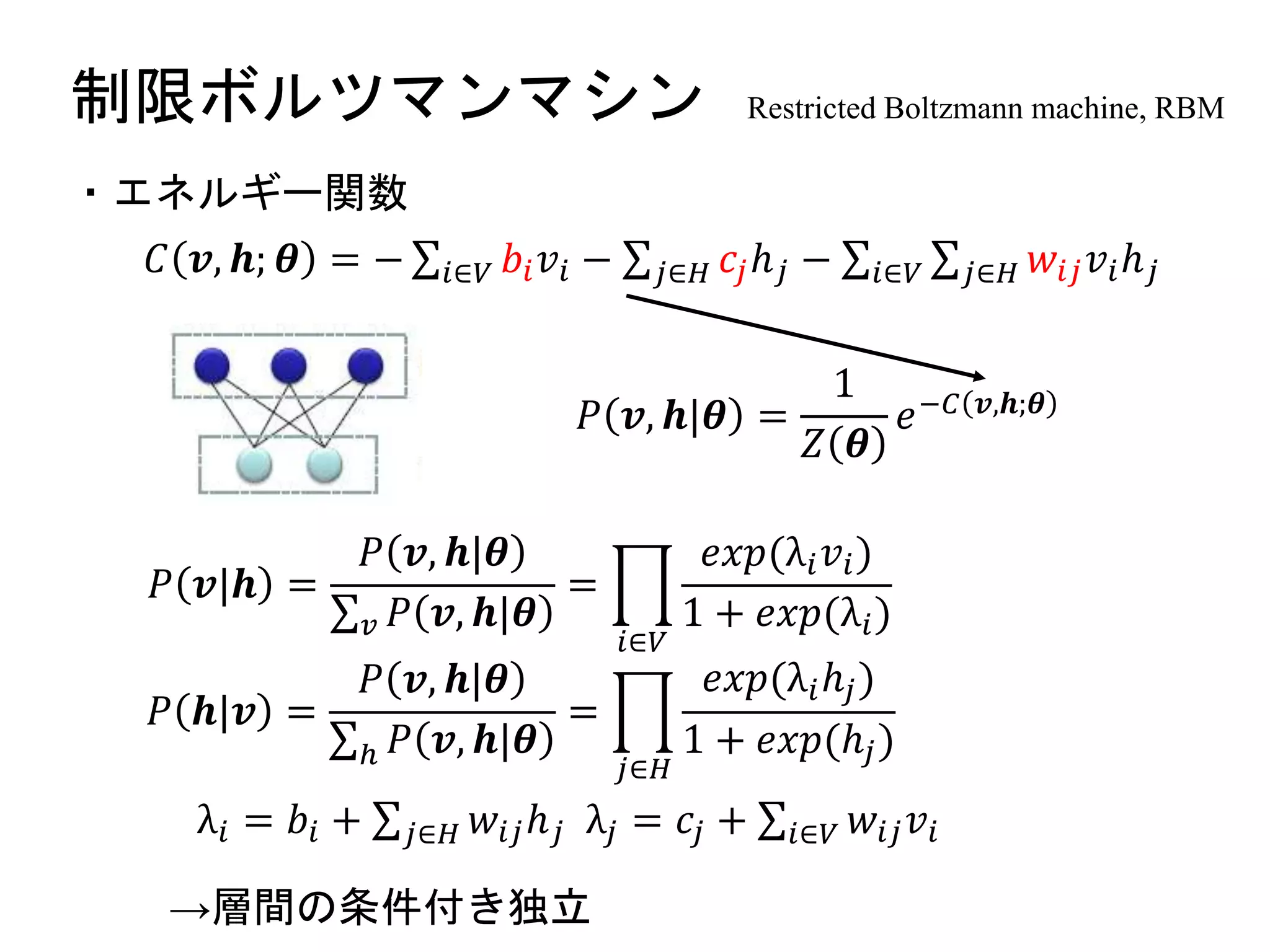
𝐶 𝒗, 𝒉; 𝜽 = − 𝑖∈𝑉 𝑏𝑖 𝑣𝑖 − 𝑗∈𝐻 𝑐𝑗ℎ 𝑗 − 𝑖∈𝑉 𝑗∈𝐻 𝑤𝑖𝑗 𝑣𝑖ℎ 𝑗
𝑃 𝒗, 𝒉|𝜽 =
1
𝑍 𝜽
𝑒−𝐶 𝒗,𝒉;𝜽
・エネルギー関数
→層間の条件付き独立
𝑃 𝒗|𝒉 =
𝑃 𝒗, 𝒉|𝜽
𝑣 𝑃 𝒗, 𝒉|𝜽
=
𝑖∈𝑉
𝑒𝑥𝑝(λ𝑖 𝑣𝑖)
1 + 𝑒𝑥𝑝(λ𝑖)
𝑃 𝒉|𝒗 =
𝑃 𝒗, 𝒉|𝜽
ℎ 𝑃 𝒗, 𝒉|𝜽
=
𝑗∈𝐻
𝑒𝑥𝑝(λ𝑖ℎ𝑗)
1 + 𝑒𝑥𝑝(ℎ𝑗)
λ𝑖 = 𝑏𝑖 + 𝑗∈𝐻 𝑤𝑖𝑗ℎ 𝑗 λ𝑗 = 𝑐𝑗 + 𝑖∈𝑉 𝑤𝑖𝑗 𝑣𝑖
- 19.
- 20.
- 21.
- 22.
- 23.