Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kimikazu Kato
PDF, PPTX
37,960 views
Pythonを使った機械学習の学習
2017年1月27日、found it project勉強会で発表した資料です。 機械学習を勉強するためにどうPythonを役立てればいいかという話です。
Technology
◦
Related topics:
Data Science Insights
•
Read more
14
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 37
2
/ 37
3
/ 37
4
/ 37
5
/ 37
6
/ 37
7
/ 37
8
/ 37
9
/ 37
10
/ 37
11
/ 37
12
/ 37
13
/ 37
14
/ 37
15
/ 37
16
/ 37
17
/ 37
18
/ 37
19
/ 37
20
/ 37
21
/ 37
22
/ 37
23
/ 37
24
/ 37
25
/ 37
26
/ 37
27
/ 37
28
/ 37
29
/ 37
30
/ 37
31
/ 37
32
/ 37
33
/ 37
34
/ 37
35
/ 37
36
/ 37
37
/ 37
More Related Content
PDF
正しいプログラミング言語の覚え方
by
Kimikazu Kato
PPTX
Pythonで機械学習を自動化 auto sklearn
by
Yukino Ikegami
PPTX
TensorFlowで会話AIを作ってみた。
by
tak9029
PDF
TensorFlowによるFizz Buzz
by
yaju88
PDF
Scikit-learnを使って 画像分類を行う
by
Arata Honda
PDF
トピックモデルを用いた 潜在ファッション嗜好の推定
by
Takashi Kaneda
PDF
「長野で語るStapyのビジョン」
by
Takeshi Akutsu
PDF
Word2vecで大谷翔平の二刀流論争に終止符を打つ!
by
Takami Sato
正しいプログラミング言語の覚え方
by
Kimikazu Kato
Pythonで機械学習を自動化 auto sklearn
by
Yukino Ikegami
TensorFlowで会話AIを作ってみた。
by
tak9029
TensorFlowによるFizz Buzz
by
yaju88
Scikit-learnを使って 画像分類を行う
by
Arata Honda
トピックモデルを用いた 潜在ファッション嗜好の推定
by
Takashi Kaneda
「長野で語るStapyのビジョン」
by
Takeshi Akutsu
Word2vecで大谷翔平の二刀流論争に終止符を打つ!
by
Takami Sato
What's hot
PPTX
210526 Power Automate Desktop Python
by
Takuya Nishimoto
PPTX
PyCon JP 2015 keynote
by
Haruo Sato
PPTX
Pythonの会社を 9年間経営してきて分かったこと
by
Haruo Sato
PDF
養成読本と私
by
Kimikazu Kato
PDF
IntelliJ IDEAで快適なPython生活
by
敦志 金谷
PPTX
数理最適化とPython
by
Yosuke Onoue
PDF
TFLite_and_PyTorch_Mobile
by
yusuke shibui
PDF
S12 t1 python学習奮闘記#5
by
Takeshi Akutsu
PDF
S10 t1 spc_by_nowfromnow
by
Takeshi Akutsu
PPTX
Python エンジニアの作り方 2011.08 #pyconjp
by
Takeshi Komiya
PDF
S09 t0 orientation
by
Takeshi Akutsu
PDF
S08 t0 orientation
by
Takeshi Akutsu
PDF
Python学習奮闘記#07 webapp
by
Takeshi Akutsu
ODP
stapy#23 LT
by
NaoY-2501
PDF
S18 t0 introduction
by
Takeshi Akutsu
PDF
まとめ
by
Takeshi Akutsu
PDF
S01 t2 akutsu_my_pythonhistory
by
Takeshi Akutsu
PDF
10分でわかるPythonの開発環境
by
Hisao Soyama
PDF
S01 t1 tsuji_pylearn_ut_01
by
Takeshi Akutsu
PDF
S10 t0 orientation
by
Takeshi Akutsu
210526 Power Automate Desktop Python
by
Takuya Nishimoto
PyCon JP 2015 keynote
by
Haruo Sato
Pythonの会社を 9年間経営してきて分かったこと
by
Haruo Sato
養成読本と私
by
Kimikazu Kato
IntelliJ IDEAで快適なPython生活
by
敦志 金谷
数理最適化とPython
by
Yosuke Onoue
TFLite_and_PyTorch_Mobile
by
yusuke shibui
S12 t1 python学習奮闘記#5
by
Takeshi Akutsu
S10 t1 spc_by_nowfromnow
by
Takeshi Akutsu
Python エンジニアの作り方 2011.08 #pyconjp
by
Takeshi Komiya
S09 t0 orientation
by
Takeshi Akutsu
S08 t0 orientation
by
Takeshi Akutsu
Python学習奮闘記#07 webapp
by
Takeshi Akutsu
stapy#23 LT
by
NaoY-2501
S18 t0 introduction
by
Takeshi Akutsu
まとめ
by
Takeshi Akutsu
S01 t2 akutsu_my_pythonhistory
by
Takeshi Akutsu
10分でわかるPythonの開発環境
by
Hisao Soyama
S01 t1 tsuji_pylearn_ut_01
by
Takeshi Akutsu
S10 t0 orientation
by
Takeshi Akutsu
Viewers also liked
PDF
実戦投入する機械学習
by
Takahiro Kubo
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PDF
ロジスティック回帰の考え方・使い方 - TokyoR #33
by
horihorio
PDF
一般向けのDeep Learning
by
Preferred Networks
PDF
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
PDF
Pythonで機械学習入門以前
by
Kimikazu Kato
PPTX
SVMについて
by
mknh1122
PDF
可視化周辺の進化がヤヴァイ 〜2016〜
by
Takashi Kitano
PDF
scikit-learnを用いた機械学習チュートリアル
by
敦志 金谷
PDF
ルールベースから機械学習への道 公開用
by
nishio
PDF
決定木学習
by
Mitsuo Shimohata
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
PDF
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
パターン認識 第10章 決定木
by
Miyoshi Yuya
PPTX
Simple perceptron by TJO
by
Takashi J OZAKI
PDF
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
PDF
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
PDF
今日から使える! みんなのクラスタリング超入門
by
toilet_lunch
PDF
はじめてでもわかるベイズ分類器 -基礎からMahout実装まで-
by
Naoki Yanai
実戦投入する機械学習
by
Takahiro Kubo
バンディットアルゴリズム入門と実践
by
智之 村上
ロジスティック回帰の考え方・使い方 - TokyoR #33
by
horihorio
一般向けのDeep Learning
by
Preferred Networks
機械学習チュートリアル@Jubatus Casual Talks
by
Yuya Unno
Pythonで機械学習入門以前
by
Kimikazu Kato
SVMについて
by
mknh1122
可視化周辺の進化がヤヴァイ 〜2016〜
by
Takashi Kitano
scikit-learnを用いた機械学習チュートリアル
by
敦志 金谷
ルールベースから機械学習への道 公開用
by
nishio
決定木学習
by
Mitsuo Shimohata
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
「はじめてでもわかる RandomForest 入門-集団学習による分類・予測 -」 -第7回データマイニング+WEB勉強会@東京
by
Koichi Hamada
パターン認識 第10章 決定木
by
Miyoshi Yuya
Simple perceptron by TJO
by
Takashi J OZAKI
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
今日から使える! みんなのクラスタリング超入門
by
toilet_lunch
はじめてでもわかるベイズ分類器 -基礎からMahout実装まで-
by
Naoki Yanai
Similar to Pythonを使った機械学習の学習
PDF
Scikit learnで学ぶ機械学習入門
by
Takami Sato
PDF
機械学習ゴリゴリ派のための数学とPython
by
Kimikazu Kato
PPTX
機械学習を始める前の「学習」
by
Serverworks Co.,Ltd.
PPTX
早稲田大学 理工メディアセンター 機械学習とAI セミナー: 機械学習入門
by
Daiyu Hatakeyama
PDF
[第2版] Python機械学習プログラミング 第1章
by
Haruki Eguchi
PDF
Pythonによる機械学習の最前線
by
Kimikazu Kato
PPTX
機械学習の基礎
by
Ken Kumagai
PDF
Pythonによる機械学習
by
Kimikazu Kato
PDF
Rとpythonとjuliaで機械学習レベル4を目指す
by
yuta july
PDF
機械学習 入門
by
Hayato Maki
PDF
チュートリアル:細胞画像を使った初めてのディープラーニング
by
DaisukeTakao
PPTX
「Python 機械学習プログラミング」 の挫折しない読み方
by
Hiroki Yamamoto
PPTX
Machine learning
by
hiroyukikageyama2
PPTX
Tfug kansai vol1
by
Natsutani Minoru
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PPTX
Machine learning
by
TakahiroBaba3
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V e-1
by
Shunsuke Nakamura
PPTX
Study ml
by
卓馬 三浦卓馬
PPTX
[輪講] 第1章
by
Takenobu Sasatani
Scikit learnで学ぶ機械学習入門
by
Takami Sato
機械学習ゴリゴリ派のための数学とPython
by
Kimikazu Kato
機械学習を始める前の「学習」
by
Serverworks Co.,Ltd.
早稲田大学 理工メディアセンター 機械学習とAI セミナー: 機械学習入門
by
Daiyu Hatakeyama
[第2版] Python機械学習プログラミング 第1章
by
Haruki Eguchi
Pythonによる機械学習の最前線
by
Kimikazu Kato
機械学習の基礎
by
Ken Kumagai
Pythonによる機械学習
by
Kimikazu Kato
Rとpythonとjuliaで機械学習レベル4を目指す
by
yuta july
機械学習 入門
by
Hayato Maki
チュートリアル:細胞画像を使った初めてのディープラーニング
by
DaisukeTakao
「Python 機械学習プログラミング」 の挫折しない読み方
by
Hiroki Yamamoto
Machine learning
by
hiroyukikageyama2
Tfug kansai vol1
by
Natsutani Minoru
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
Machine learning
by
TakahiroBaba3
1028 TECH & BRIDGE MEETING
by
健司 亀本
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V e-1
by
Shunsuke Nakamura
Study ml
by
卓馬 三浦卓馬
[輪講] 第1章
by
Takenobu Sasatani
More from Kimikazu Kato
PDF
2012-03-08 MSS研究会
by
Kimikazu Kato
PDF
A Safe Rule for Sparse Logistic Regression
by
Kimikazu Kato
PPTX
関東GPGPU勉強会資料
by
Kimikazu Kato
PPTX
純粋関数型アルゴリズム入門
by
Kimikazu Kato
PDF
Effective Numerical Computation in NumPy and SciPy
by
Kimikazu Kato
PDF
Sapporo20140709
by
Kimikazu Kato
PDF
【論文紹介】Approximate Bayesian Image Interpretation Using Generative Probabilisti...
by
Kimikazu Kato
PDF
Tokyo webmining 2017-10-28
by
Kimikazu Kato
PDF
特定の不快感を与えるツイートの分類と自動生成について
by
Kimikazu Kato
PDF
ネット通販向けレコメンドシステム提供サービスについて
by
Kimikazu Kato
PDF
Recommendation System --Theory and Practice
by
Kimikazu Kato
PDF
Introduction to behavior based recommendation system
by
Kimikazu Kato
PDF
Introduction to NumPy for Machine Learning Programmers
by
Kimikazu Kato
PDF
Zuang-FPSGD
by
Kimikazu Kato
PDF
About Our Recommender System
by
Kimikazu Kato
PDF
Fast and Probvably Seedings for k-Means
by
Kimikazu Kato
PDF
Sparse pca via bipartite matching
by
Kimikazu Kato
2012-03-08 MSS研究会
by
Kimikazu Kato
A Safe Rule for Sparse Logistic Regression
by
Kimikazu Kato
関東GPGPU勉強会資料
by
Kimikazu Kato
純粋関数型アルゴリズム入門
by
Kimikazu Kato
Effective Numerical Computation in NumPy and SciPy
by
Kimikazu Kato
Sapporo20140709
by
Kimikazu Kato
【論文紹介】Approximate Bayesian Image Interpretation Using Generative Probabilisti...
by
Kimikazu Kato
Tokyo webmining 2017-10-28
by
Kimikazu Kato
特定の不快感を与えるツイートの分類と自動生成について
by
Kimikazu Kato
ネット通販向けレコメンドシステム提供サービスについて
by
Kimikazu Kato
Recommendation System --Theory and Practice
by
Kimikazu Kato
Introduction to behavior based recommendation system
by
Kimikazu Kato
Introduction to NumPy for Machine Learning Programmers
by
Kimikazu Kato
Zuang-FPSGD
by
Kimikazu Kato
About Our Recommender System
by
Kimikazu Kato
Fast and Probvably Seedings for k-Means
by
Kimikazu Kato
Sparse pca via bipartite matching
by
Kimikazu Kato
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
Pythonを使った機械学習の学習
1.
Pythonを使った機械学習の学習 2017年1月27日 found it project
セミナー 加藤公一 シルバーエッグ・テクノロジー(株)
2.
自己紹介 加藤公一(かとうきみかず) シルバーエッグ・テクノロジー(株) チーフサイエンティスト Twitter: @hamukazu 博士(情報理工学)、修士は数学 機械学習歴もPython歴も4年 趣味:筋トレ、特技:ベンチプレス
3.
今日のはなし • 機械学習の学習の話 – どのように勉強するとよいか •
私はどのように学習したか – 4年前は初心者
4.
ちなみに… http://bit.ly/kimikazu20140913 http://bit.ly/kimikazu20160204 いままでPythonの高速化芸を得意としてきました。 PyCon JP
2014 ソフトウェアジャパン2016 今日はその話はしません。
5.
宣伝 http://bit.ly/yoseiml 書きました!
6.
宣伝 http://bit.ly/kagakupy 訳しました!
7.
今日の話 • 機械学習を効率よく勉強するにはどうすれば いいだろうか • ただツールを使うだけではなく内部動作にも 詳しくなるために •
理解を助けるツールとしてのPython
8.
私はどうやって勉強したか • 本(論文)を読む • 自分で実装する –
人工データで振る舞いを確認する – 内部動作を可視化する • 既存の実装を見る – ソースコードを読む – 内部データを読む
9.
まずはこれ
10.
さらにその前に • 線形代数 • 微積分
11.
自分で実装する • 便利なライブラリがあっても、理解のためにあ えて自分で作ってみる – 参考例:大学のクラスで学習するソートのアルゴ リズム→機能を得ることが目的ではない、便利な ライブラリならいくらでもある •
最新の論文に出ているアルゴリズムは自分 で実装せざるをえないことも – 意外と簡単につくれる
12.
人工データでの確認 I1 I2 I3
I4 I5 U1 1 1 1 U2 1 1 1 U3 1 1 1 U4 1 1 ? ? ? レコメンデーションの場合 ユーザU4には何を薦めればいい? クラスタリングの場合 これを2つのクラスタに分ける 離れた2つの点を中心に正規分布した点をそれぞれ作る こういう自明なケースで確認:単体テストとしても有効
13.
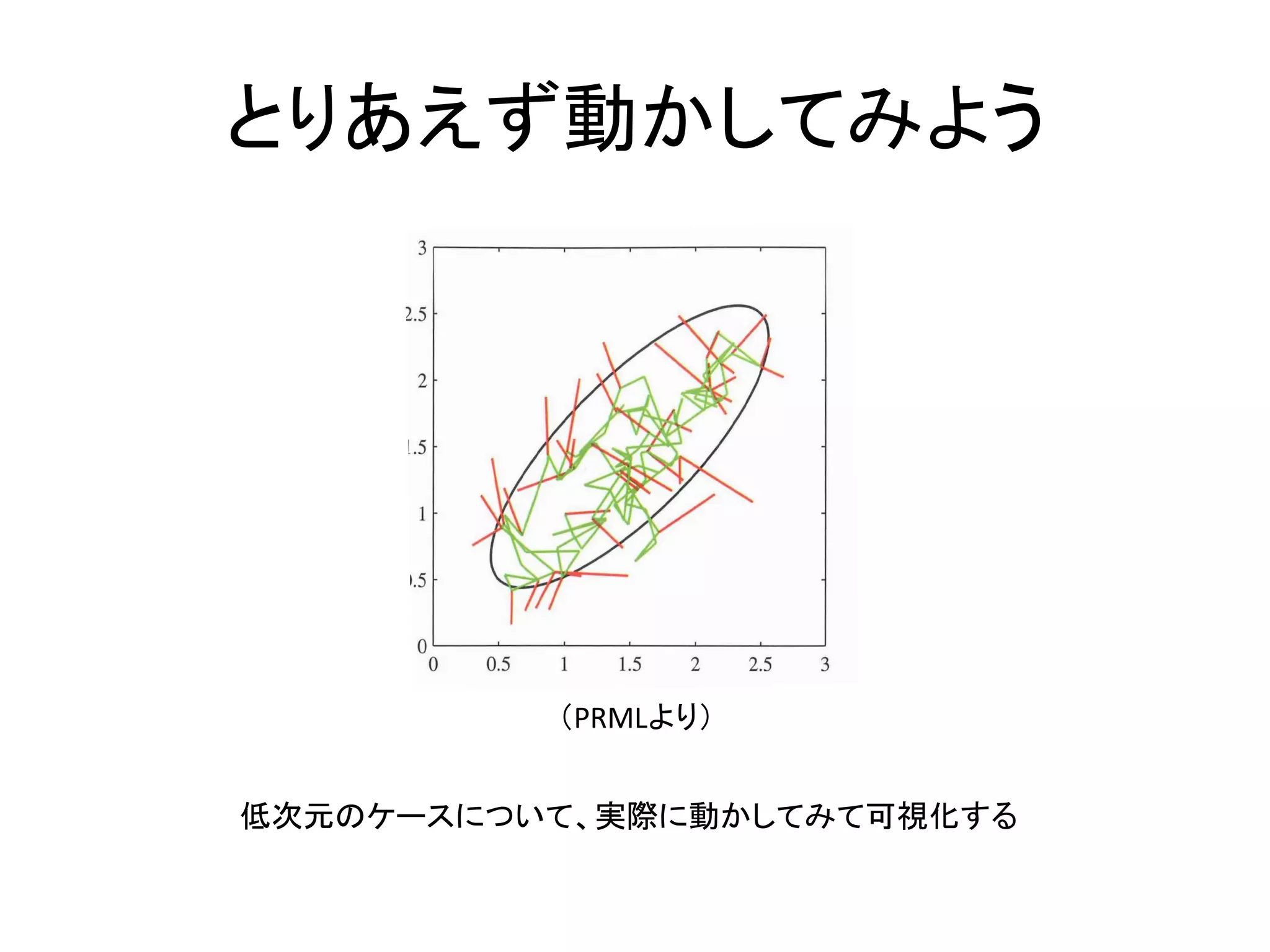
内部動作の可視化 Metropolis-Hastingsアルゴリズム(MCMCの一 種)の動作原理を説明できますか?
14.
とりあえず動かしてみよう (PRMLより) 低次元のケースについて、実際に動かしてみて可視化する
15.
他の例:Lasso • Lassoの解がなぜsparseになるか説明できま すか?
16.
L2ノルムの最小化 直線と共有点を持つように 円(L2球)を最小化
17.
L1ノルムの最小化 直線と共有点を持つように ひし形(L1球)を最小化
18.
このように… • データが単純なとき(極端な分布のとき)、次 元が低いとき、など簡単なケースで実装して 試してみる • 実用上の価値がなくても動作の理解には役 に立つ
19.
数値的な解析に便利なツール • Numpy/Scipy (これはあたりまえ) •
Sympy (あまり使わない?)
20.
問題 次の機械学習でよく出てくる関数を微分せよ(制限時間各5秒)
21.
答
22.
数値微分はあまりよくないという話 実際にfの値を評価しながら計算すると、hが小さいとき に桁落ちが起こって精度が落ちる
23.
Sympy • シンボリックな計算ができる • 代数的な演算や、微分・積分などもシンボリッ クに
24.
既存のライブラリを使ってみる • とりあえずはscikit-learn • インターフェースが統一されてる •
ドキュメントも整備されている
25.
みんな大好きあやめの分類 PCAで2次元に射影してからSVMで分類
26.
これで喜んでていいの? 普通サポートベクタ知りたいよね?
27.
サポートベクタの可視化 SVC.support_vector_でサポートベクタが取 得できる (ドキュメントに書いてある)
28.
Scikit-learnのよさ • ドキュメントがよく書かれていて、内部データ 構造についても記述があるものが多い • 内部データ構造を見ることで機械学習アルゴ リズムの理解に役立つ •
それでも納得しなければソースコードを読め ばいい • とにかく深掘りしやすい環境
29.
しかし… • Scikit-learnがすべてではない • 機械学習ライブラリの中にはドキュメントが不 親切なものも
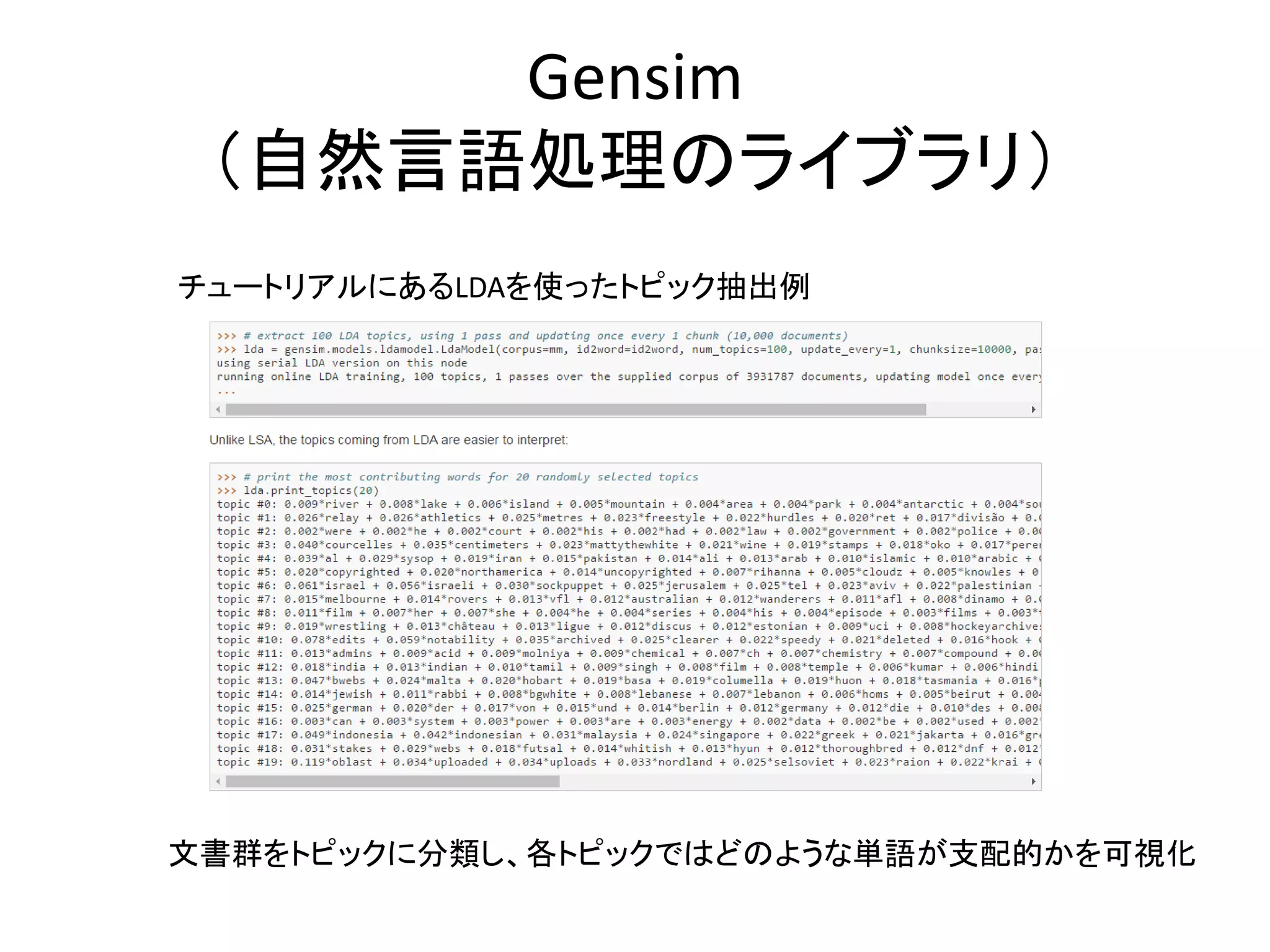
30.
Gensim (自然言語処理のライブラリ) チュートリアルにあるLDAを使ったトピック抽出例 文書群をトピックに分類し、各トピックではどのような単語が支配的かを可視化
31.
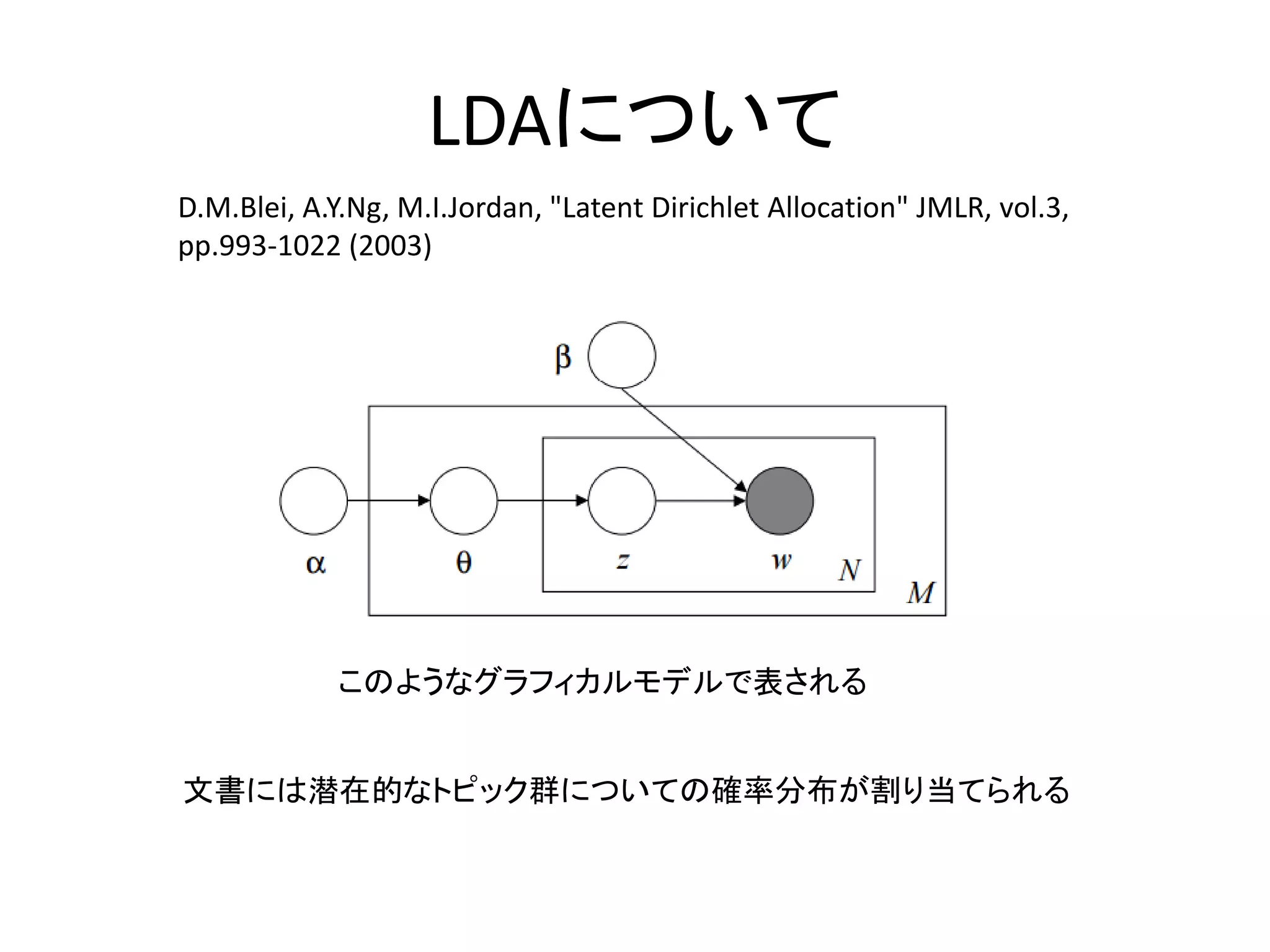
LDAについて D.M.Blei, A.Y.Ng, M.I.Jordan,
"Latent Dirichlet Allocation" JMLR, vol.3, pp.993-1022 (2003) このようなグラフィカルモデルで表される 文書には潜在的なトピック群についての確率分布が割り当てられる
32.
こんなデモでいいの? その他の内部パラメータを可視化しなくない?
33.
そのためには • 内部データ構造について、ドキュメントにはな にも書いていない • なので、ソースコードを読まないとならない •
といっても、よく整理されているので読みやす い
34.
LDAのパラメータ
35.
まとめ • 中身を理解したかったら手を動かしながら勉 強しよう • 理解のためのツールとしてもPythonは使える •
Sympyはいいぞ
36.
私のキャリア戦略 • 「中身をよくわかっている」というのは競争力 になるのではないか – より深いチューニング –
最新の研究論文の実装・実験がスムーズに
37.
良い理論ほど実用的なものはない 「科学技術計算のためのPython―確率・統計・機械学習」より
Download























































































![[第2版] Python機械学習プログラミング 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-01-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)














![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)






















