Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kimikazu Kato
PPTX, PDF
6,812 views
純粋関数型アルゴリズム入門
日本ユニシス社内でHaskellの勉強会をやったときの私の発表資料です。
Technology
◦
Read more
17
Save
Share
Embed
Embed presentation
Download
Downloaded 36 times
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
Most read
15
/ 33
Most read
16
/ 33
Most read
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
by
Takuya Akiba
PDF
プログラミングコンテストでの乱択アルゴリズム
by
Takuya Akiba
PDF
中3女子が狂える本当に気持ちのいい constexpr
by
Genya Murakami
PDF
自動定理証明の紹介
by
Masahiro Sakai
KEY
ラムダ計算入門
by
Eita Sugimoto
PPTX
動的計画法を極める!
by
HCPC: 北海道大学競技プログラミングサークル
PDF
ウェーブレット木の世界
by
Preferred Networks
PDF
プログラミングコンテストでの動的計画法
by
Takuya Akiba
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
by
Takuya Akiba
プログラミングコンテストでの乱択アルゴリズム
by
Takuya Akiba
中3女子が狂える本当に気持ちのいい constexpr
by
Genya Murakami
自動定理証明の紹介
by
Masahiro Sakai
ラムダ計算入門
by
Eita Sugimoto
動的計画法を極める!
by
HCPC: 北海道大学競技プログラミングサークル
ウェーブレット木の世界
by
Preferred Networks
プログラミングコンテストでの動的計画法
by
Takuya Akiba
What's hot
PDF
色々なダイクストラ高速化
by
yosupo
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
PDF
最大流 (max flow)
by
HCPC: 北海道大学競技プログラミングサークル
PDF
LCA and RMQ ~簡潔もあるよ!~
by
Yuma Inoue
PDF
AtCoder Beginner Contest 023 解説
by
AtCoder Inc.
PDF
Binary indexed tree
by
HCPC: 北海道大学競技プログラミングサークル
PDF
ユークリッド最小全域木
by
理玖 川崎
PDF
最小カットを使って「燃やす埋める問題」を解く
by
shindannin
PDF
AtCoder Beginner Contest 022 解説
by
AtCoder Inc.
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
PDF
様々な全域木問題
by
tmaehara
PDF
Rolling hash
by
HCPC: 北海道大学競技プログラミングサークル
PDF
Rolling Hashを殺す話
by
Nagisa Eto
PDF
プログラミングコンテストでのデータ構造
by
Takuya Akiba
PPTX
AtCoder Beginner Contest 002 解説
by
AtCoder Inc.
PDF
競技プログラミングにおけるコードの書き方とその利便性
by
Hibiki Yamashiro
PPTX
競技プログラミングのためのC++入門
by
natrium11321
PDF
指数時間アルゴリズムの最先端
by
Yoichi Iwata
PDF
AtCoder Beginner Contest 015 解説
by
AtCoder Inc.
PDF
Re永続データ構造が分からない人のためのスライド
by
Masaki Hara
色々なダイクストラ高速化
by
yosupo
明日使えないすごいビット演算
by
京大 マイコンクラブ
最大流 (max flow)
by
HCPC: 北海道大学競技プログラミングサークル
LCA and RMQ ~簡潔もあるよ!~
by
Yuma Inoue
AtCoder Beginner Contest 023 解説
by
AtCoder Inc.
Binary indexed tree
by
HCPC: 北海道大学競技プログラミングサークル
ユークリッド最小全域木
by
理玖 川崎
最小カットを使って「燃やす埋める問題」を解く
by
shindannin
AtCoder Beginner Contest 022 解説
by
AtCoder Inc.
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
様々な全域木問題
by
tmaehara
Rolling hash
by
HCPC: 北海道大学競技プログラミングサークル
Rolling Hashを殺す話
by
Nagisa Eto
プログラミングコンテストでのデータ構造
by
Takuya Akiba
AtCoder Beginner Contest 002 解説
by
AtCoder Inc.
競技プログラミングにおけるコードの書き方とその利便性
by
Hibiki Yamashiro
競技プログラミングのためのC++入門
by
natrium11321
指数時間アルゴリズムの最先端
by
Yoichi Iwata
AtCoder Beginner Contest 015 解説
by
AtCoder Inc.
Re永続データ構造が分からない人のためのスライド
by
Masaki Hara
Similar to 純粋関数型アルゴリズム入門
PDF
関数プログラミング入門
by
Hideyuki Tanaka
KEY
Algebraic DP: 動的計画法を書きやすく
by
Hiromi Ishii
PDF
たのしい関数型
by
Shinichi Kozake
PDF
すごいHaskell読書会 in 大阪 2週目 #5 第5章:高階関数 (2)
by
Yoichi Nakayama
PDF
関数型プログラミング入門 with OCaml
by
Haruka Oikawa
PDF
C++0x in programming competition
by
yak1ex
PDF
PFI Christmas seminar 2009
by
Preferred Networks
PPT
Algorithm 速いアルゴリズムを書くための基礎
by
Kenji Otsuka
PDF
F#入門 ~関数プログラミングとは何か~
by
Nobuhisa Koizumi
PDF
Pyramid
by
tomerun
PDF
programming camp 2008, introduction of programming, algorithm
by
Hiro Yoshioka
PDF
動的計画法入門(An introduction to Dynamic Programming)
by
kakira9618
PDF
命令プログラミングから関数プログラミングへ
by
Naoki Kitora
PDF
Functional Way
by
Kent Ohashi
PDF
関数型都市忘年会『はじめての函数型プログラミング』
by
Kenta USAMI
PPTX
Coq 20100208a
by
tmiya
PDF
第22回アルゴリズム勉強会資料
by
Yuuki Ono
PDF
R language definition3.1_3.2
by
Yoshiteru Kamiyama
PDF
すごいHaskell読書会#1 in 大阪
by
yashigani
PDF
第21回アルゴリズム勉強会
by
Yuuki Ono
関数プログラミング入門
by
Hideyuki Tanaka
Algebraic DP: 動的計画法を書きやすく
by
Hiromi Ishii
たのしい関数型
by
Shinichi Kozake
すごいHaskell読書会 in 大阪 2週目 #5 第5章:高階関数 (2)
by
Yoichi Nakayama
関数型プログラミング入門 with OCaml
by
Haruka Oikawa
C++0x in programming competition
by
yak1ex
PFI Christmas seminar 2009
by
Preferred Networks
Algorithm 速いアルゴリズムを書くための基礎
by
Kenji Otsuka
F#入門 ~関数プログラミングとは何か~
by
Nobuhisa Koizumi
Pyramid
by
tomerun
programming camp 2008, introduction of programming, algorithm
by
Hiro Yoshioka
動的計画法入門(An introduction to Dynamic Programming)
by
kakira9618
命令プログラミングから関数プログラミングへ
by
Naoki Kitora
Functional Way
by
Kent Ohashi
関数型都市忘年会『はじめての函数型プログラミング』
by
Kenta USAMI
Coq 20100208a
by
tmiya
第22回アルゴリズム勉強会資料
by
Yuuki Ono
R language definition3.1_3.2
by
Yoshiteru Kamiyama
すごいHaskell読書会#1 in 大阪
by
yashigani
第21回アルゴリズム勉強会
by
Yuuki Ono
More from Kimikazu Kato
PDF
Tokyo webmining 2017-10-28
by
Kimikazu Kato
PDF
機械学習ゴリゴリ派のための数学とPython
by
Kimikazu Kato
PDF
Pythonを使った機械学習の学習
by
Kimikazu Kato
PDF
Fast and Probvably Seedings for k-Means
by
Kimikazu Kato
PDF
Pythonで機械学習入門以前
by
Kimikazu Kato
PDF
Pythonによる機械学習
by
Kimikazu Kato
PDF
Introduction to behavior based recommendation system
by
Kimikazu Kato
PDF
Pythonによる機械学習の最前線
by
Kimikazu Kato
PDF
Sparse pca via bipartite matching
by
Kimikazu Kato
PDF
正しいプログラミング言語の覚え方
by
Kimikazu Kato
PDF
養成読本と私
by
Kimikazu Kato
PDF
Introduction to NumPy for Machine Learning Programmers
by
Kimikazu Kato
PDF
Recommendation System --Theory and Practice
by
Kimikazu Kato
PDF
A Safe Rule for Sparse Logistic Regression
by
Kimikazu Kato
PDF
特定の不快感を与えるツイートの分類と自動生成について
by
Kimikazu Kato
PDF
Effective Numerical Computation in NumPy and SciPy
by
Kimikazu Kato
PDF
Sapporo20140709
by
Kimikazu Kato
PDF
【論文紹介】Approximate Bayesian Image Interpretation Using Generative Probabilisti...
by
Kimikazu Kato
PDF
Zuang-FPSGD
by
Kimikazu Kato
PDF
About Our Recommender System
by
Kimikazu Kato
Tokyo webmining 2017-10-28
by
Kimikazu Kato
機械学習ゴリゴリ派のための数学とPython
by
Kimikazu Kato
Pythonを使った機械学習の学習
by
Kimikazu Kato
Fast and Probvably Seedings for k-Means
by
Kimikazu Kato
Pythonで機械学習入門以前
by
Kimikazu Kato
Pythonによる機械学習
by
Kimikazu Kato
Introduction to behavior based recommendation system
by
Kimikazu Kato
Pythonによる機械学習の最前線
by
Kimikazu Kato
Sparse pca via bipartite matching
by
Kimikazu Kato
正しいプログラミング言語の覚え方
by
Kimikazu Kato
養成読本と私
by
Kimikazu Kato
Introduction to NumPy for Machine Learning Programmers
by
Kimikazu Kato
Recommendation System --Theory and Practice
by
Kimikazu Kato
A Safe Rule for Sparse Logistic Regression
by
Kimikazu Kato
特定の不快感を与えるツイートの分類と自動生成について
by
Kimikazu Kato
Effective Numerical Computation in NumPy and SciPy
by
Kimikazu Kato
Sapporo20140709
by
Kimikazu Kato
【論文紹介】Approximate Bayesian Image Interpretation Using Generative Probabilisti...
by
Kimikazu Kato
Zuang-FPSGD
by
Kimikazu Kato
About Our Recommender System
by
Kimikazu Kato
純粋関数型アルゴリズム入門
1.
純粋関数型アルゴリズム入門 日本ユニシス株式会社
総合技術研究所 加藤公一
2.
まずは簡単に自己紹介
3.
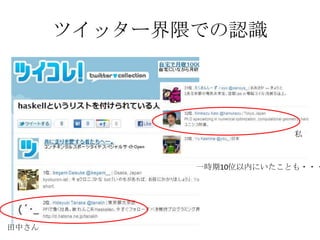
ツイッター界隈での認識
私 一時期10位以内にいたことも・・・ 田中さん
4.
でもインチキHaskellerです 実はあまリHaskellのコード書いたことないですし・・・
5.
なので我田引水 アルゴリズムの話をします
6.
今日の話 この本の解説
Purely Functional Data Structure Chris Okazaki リストとキューの話しかしません (それでも十分難しい)
7.
関数型言語の利点 • 本を読め! by
C.Okazaki – J.Backus 1978 – J.Hughes 1989 – P.Hudak and M.P. Jones 1994 • それだとあんまりなので、適宜説明しま す
8.
データ永続性(persistency) • 変数に割り当てられた値は一切変更され
ることはない – 破壊的代入が行われない – いつ参照しても同じ値が返ってくる • 永続性により保守性が高まる 例: 1. aにある値を代入 2. bにある値を代入 3. a,bの値を表示 4. aとbにある操作をしてその結果をcに代入 5. a,bの値を表示 この間に値が変わらないのが、永続性
9.
純粋関数型データ構造
(アルゴリズム) • データの永続性が保証されるデータ構造 (アルゴリズム)である • つまり永続性による保守性と、計算効率 を同時に考慮する
10.
例:リストの結合
xs=[1; 2; 3; 4] ys=[5; 6; 7; 8] zs=xs++ys 手続き型言語(たとえばC言語)では? xs ys 1 2 3 4 5 6 7 8 zs これだと、実行後xsの値が書き変わってしまう (永続的ではない) 永続性の保証のためには、事前にデータのコピーが必要
11.
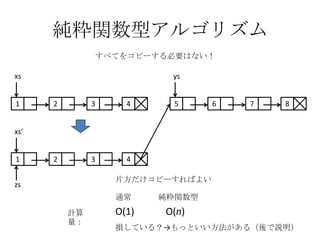
純粋関数型アルゴリズム
すべてをコピーする必要はない! xs ys 1 2 3 4 5 6 7 8 xs’ 1 2 3 4 片方だけコピーすればよい zs 通常 純粋関数型 計算 O(1) O(n) 量: 損している?→もっといい方法がある(後で説明)
12.
純粋関数型アルゴリズムを
学ぶメリット • (非純粋)関数型言語を使っている人: 一部を純粋関数型にすることで保守性を 高めることができる • 純粋関数型言語を使っている人:計算効 率の良いプログラムが書ける • 手続き型言語を使っている人:保守性を 高めることができる – 解く問題によっては・・・
13.
以下の疑似コード表記ルール • 遅延評価がデフォルトだとみなしたくな
いので、ML風に疑似コードを書きます – アルゴリズムを明示的に理解するため – MLを知らない人でも大丈夫です。多分読めま す。 • Haskellのハラワタを示していると解釈して もいい
14.
準備:リストの基本操作
a=[1;2;3] head a => 1 a 1 2 3 1 b=tail a => [2;3] a 1 2 3 b c=Cons(0,a) => [0;1;2;3] c 0 1 2 3 a すべて永続性を保持しても計算量O(1)
15.
ならし計算量
(Amortized Complexity) • 一連の操作の中で、ならして(平均的 な)計算量を考える • 一連の操作の中で一部計算量が多いこと があったとしても、平均すると計算量が 小さいということがある
16.
例:キュー(queue) • 先入れ先出しリスト • ここでは以下の3つの操作を考える
– head:キューの最初の値を取得する – tail:キューから最初の値を削除する – snoc:キューに値を追加する snoc 1 snoc 2 snoc 3 head => 1 tail head => 2 head => 2
17.
純粋関数型なキューのアルゴリズ
ム • キューを2つのリストの組(f,r)として表す – ただし、常にfが空にならないように管理する – fが空になった時は、(reverse r, [])を返す • 新しく値を加える(snoc)ときは、rの頭 に加える • 値を取得する(head)ときは、fの頭の値 を取得する • 値を削除する(tail)ときは、fの頭を削除 する
18.
通常のリストによる表現
純粋関数型データ構造 q1=snoc (empty,1) ([], [1]) [1] ([1], []) q2=snoc (q1,2) q3=snoc (q2,3) q4=snoc (q3,4) [1;2;3;4] ([1], [4;3;2]) q5=tail q4 ([], [4;3;2]) [2;3;4] ([2;3;4], []) q6=tail q5 [3;4] ([3;4], []) q7=snoc q6 5 [3;4;5] ([3;4], [5])
19.
計算量 • reverse rの計算量が大きい:rのサイズmと
するとO(m) • しかしreverseはたまにしか起こらないの で、ならすと大きな計算量増加にはなら ない→ならし計算量の考え方
20.
詳細な解析 • snocの計算量は1(rの先頭に要素を加える
だけ) • tailの計算量は – 通常は1(fのtailをとる) – fの要素数が1のときはm+1(fのtailを取ってか らrのreverse)
21.
ならし計算量 • snocの計算量は2だと思う(実際には1なの
で、1貯金する) • tailの計算量は – 通常は1 – fの要素数が1のときは貯金を使って1(rのサ イズがmになるまではsnocがm回行われている →貯金はmある) • つまり、ならせばすべての操作の計算量 はO(1)であるとみなしてよい
22.
銀行家法(Banker’s Method) • このように、実際にかかっていない計算
量をかかったとみなして貯金し、必要に 応じて(大きな計算量が必要なときに) その貯金を使うという考え方を、銀行家 法と呼ぶ。
23.
ここまでのまとめ • ならし計算量でみると、キューの操作の
計算量は、純粋関数型でもO(1) • ここでの計算量評価法は「銀行家法」が 使われた – ほかには物理学者法(Physicist’s method)があ る • でもなんかだまされたような気がす る・・・
24.
遅延評価(Lazy evaluation) •
実際に必要になるまで評価は行わない • 代入時点では「式」を覚えている • 一度評価されたら値を覚えている • Haskellではデフォルトの動作
25.
記法 • 既存関数を遅延評価するときは頭に$を付
ける • 遅延評価する関数を新たに定義するとき は、関数名の前にlazyを付ける • 強制的に評価するときには、force関数を 適用 例:n番目の素数を返す関数primes n val p=$primes 1000000 一瞬で終わる(計算しない) val q=force p 時間がかかる val r=force p 一瞬で終わる(答を覚えている)
26.
遅延付きリスト(ストリーム)
~アイデア~ • リストの結合は最終的な目的ではない • 通常リストについての操作で最終的な目 的は、リストの一部を表示または他の計 算に使うこと • 以下、2つのリストを結合した後にtake k (最初のk個の要素をとる)をするという ストーリを考える
27.
リストはConsの遅延で表現する
val p=$Cons(1,$Cons(2,$Cons(3,$Cons(4,$Nil)))) 1 2 3 4 val q=$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil)))) 4 5 6 7 fun lazy ($Nil)++t=t | ($Cons(x,s))++t=$Cons(x,s++t) fun lazy take(0,s) = $Nil | take(n,$Nil) = $Nil | take(n,$Cons(x,s)) = $Cons(x,take(n-1,s))
28.
fun lazy ($Nil)++t=t
| ($Cons(x,s))++t=$Cons(x,s++t) fun lazy take(0,s) = $Nil | take(n,$Nil) = $Nil | take(n,$Cons(x,s)) = $Cons(x,take(n-1,s)) val p=$Cons(1,$Cons(2,$Cons(3,$Cons(4,$Nil)))) val q=$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil)))) val r=take(2,p++q) val s=force r take(2, $Cons(1,$Cons(2,$Cons(3,$Cons(4,$Nil)))) ++$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil))))) => take(2, $Cons(1,$Cons(2,$Cons(3,$Cons(4,$Nil))) ++$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil)))))) => $Cons(1,take(1,$Cons(2,$Cons(3,$Cons(4,$Nil))) ++$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil)))))) => $Cons(1,take(1,$Cons(2,$Cons(3,$Cons(4,$Nil)) ++$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil))))))) => $Cons(1,$Cons(2,take(0,$Cons(3,$Cons(4,$Nil)) ++$Cons(4,$Cons(5,$Cons(6,$Cons(7,$Nil))))))) => $Cons(1,$Cons(2,$Nil)
29.
計算量 • 結合(++)してtake kする計算量は、純粋
関数型でもO(k) • 結合対象のリストのサイズには依存しな い
30.
キューの遅延評価版 • キューは、遅延評価版を考えることで、
「ならし」の部分が消滅する – つまり、ならさなくてもO(1)に
31.
基本的アイデア • reverseの遅延評価版「rotate」を考える • rのサイズがfのサイズより1大きいときに
限ってrotateが動くこととする – 非遅延版はf=[]のときにreverseが走った – 今度はf++reverse rを計算したい • しかしそのまま直接では、遅延評価版を 作れないので、アキュムレータを入れる (f,r,a)のタプルを考える fun rotate ($Nil, Cons(y,_), a)=$Cons(y,a) | rotate ($Cons(x,xs), Cons(y,ys), a) 注:rについては非遅延リストでいい =$Cons(x,rotate(xs,ys,$Cons(y,a)))
32.
例
fun rotate ($Nil, Cons(y,_), a)=$Cons(y,a) | rotate ($Cons(x,xs), $Cons(y,ys), a) =$Cons(x,rotate(xs,ys,$Cons(y,a))) f=[1;2], r=[5;4;3] の場合 f2=rotate($Cons(1,$Cons(2,$Nil)), [5;4;3], $Nil) => $Cons(1, rotate($Cons(2,$Nil),[4;3],$Cons(5,$Nil))) ここで停止する 次にtailをとると・・・ f3=tail f2 =>rotate($Cons(2,$Nil),[4;3],$Cons(5,$Nil)) =>$Cons(2, rotate($Nil,[3],$Cons(4,$Cons(5,$Nil)))) ここで停止する またまたtailをとると・・・ f4=tail f3 =>rotate($Nil,[3],$Cons(4,$Cons(5,$Nil))) =>$Cons(3,$Cons(4,$Cons(5,$Nil))) ここで停止する 以下tailをとる操作は自明 以上のようなrotateを部品として使う ほかにも工夫が必要だが、説明略
33.
まとめ • 純粋関数型アルゴリズムは便利 –
計算は速いし、保守性も高い – もちろん多少の犠牲(オーバーヘッド)は伴 う • 純粋関数型アルゴリズムを設計するうえ で遅延評価は重要 – 計算量に直接効いてくる – ならし計算量がならさなくてもよくなる (deamortalization)
Download










![例:リストの結合
xs=[1; 2; 3; 4]
ys=[5; 6; 7; 8]
zs=xs++ys
手続き型言語(たとえばC言語)では?
xs ys
1 2 3 4 5 6 7 8
zs
これだと、実行後xsの値が書き変わってしまう
(永続的ではない)
永続性の保証のためには、事前にデータのコピーが必要](https://image.slidesharecdn.com/random-111111013236-phpapp01/85/slide-10-320.jpg)


![準備:リストの基本操作
a=[1;2;3]
head a => 1 a 1 2 3
1
b=tail a => [2;3]
a 1 2 3
b
c=Cons(0,a) => [0;1;2;3]
c 0 1 2 3
a
すべて永続性を保持しても計算量O(1)](https://image.slidesharecdn.com/random-111111013236-phpapp01/85/slide-14-320.jpg)


![純粋関数型なキューのアルゴリズ
ム
• キューを2つのリストの組(f,r)として表す
– ただし、常にfが空にならないように管理する
– fが空になった時は、(reverse r, [])を返す
• 新しく値を加える(snoc)ときは、rの頭
に加える
• 値を取得する(head)ときは、fの頭の値
を取得する
• 値を削除する(tail)ときは、fの頭を削除
する](https://image.slidesharecdn.com/random-111111013236-phpapp01/85/slide-17-320.jpg)
![通常のリストによる表現 純粋関数型データ構造
q1=snoc (empty,1)
([], [1])
[1]
([1], [])
q2=snoc (q1,2)
q3=snoc (q2,3)
q4=snoc (q3,4)
[1;2;3;4] ([1], [4;3;2])
q5=tail q4
([], [4;3;2])
[2;3;4]
([2;3;4], [])
q6=tail q5
[3;4] ([3;4], [])
q7=snoc q6 5
[3;4;5] ([3;4], [5])](https://image.slidesharecdn.com/random-111111013236-phpapp01/85/slide-18-320.jpg)












![基本的アイデア
• reverseの遅延評価版「rotate」を考える
• rのサイズがfのサイズより1大きいときに
限ってrotateが動くこととする
– 非遅延版はf=[]のときにreverseが走った
– 今度はf++reverse rを計算したい
• しかしそのまま直接では、遅延評価版を
作れないので、アキュムレータを入れる
(f,r,a)のタプルを考える
fun rotate ($Nil, Cons(y,_), a)=$Cons(y,a)
| rotate ($Cons(x,xs), Cons(y,ys), a) 注:rについては非遅延リストでいい
=$Cons(x,rotate(xs,ys,$Cons(y,a)))](https://image.slidesharecdn.com/random-111111013236-phpapp01/85/slide-31-320.jpg)
![例 fun rotate ($Nil, Cons(y,_), a)=$Cons(y,a)
| rotate ($Cons(x,xs), $Cons(y,ys), a)
=$Cons(x,rotate(xs,ys,$Cons(y,a)))
f=[1;2], r=[5;4;3] の場合
f2=rotate($Cons(1,$Cons(2,$Nil)), [5;4;3], $Nil)
=> $Cons(1, rotate($Cons(2,$Nil),[4;3],$Cons(5,$Nil))) ここで停止する
次にtailをとると・・・
f3=tail f2
=>rotate($Cons(2,$Nil),[4;3],$Cons(5,$Nil))
=>$Cons(2, rotate($Nil,[3],$Cons(4,$Cons(5,$Nil)))) ここで停止する
またまたtailをとると・・・
f4=tail f3
=>rotate($Nil,[3],$Cons(4,$Cons(5,$Nil)))
=>$Cons(3,$Cons(4,$Cons(5,$Nil)))
ここで停止する
以下tailをとる操作は自明
以上のようなrotateを部品として使う
ほかにも工夫が必要だが、説明略](https://image.slidesharecdn.com/random-111111013236-phpapp01/85/slide-32-320.jpg)




































































