Downloaded 4,633 times















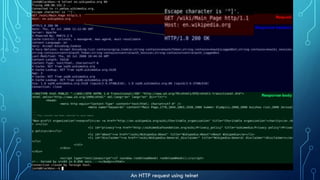




HTTP is the application-layer protocol for transmitting hypertext documents across the internet. It works by establishing a TCP connection between an HTTP client, like a web browser, and an HTTP server. The client sends a request to the server using methods like GET or POST. The server responds with a status code and the requested resource. HTTP is stateless, meaning each request is independent and servers do not remember past client interactions. Cookies and caching are techniques used to maintain some state and improve performance.























































































