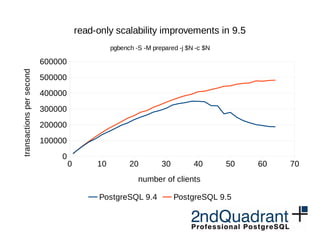
The document summarizes performance improvements in PostgreSQL versions 9.5 and 9.6. Some key improvements discussed include optimizations to sorting, hash joins, BRIN indexes, parallel query processing, aggregate functions, checkpoints, and freezing. Performance tests on sorting, hash joins, and parallel queries show significant speedups from these changes, such as faster sorting times and better scalability with parallel queries.








![asc desc almost asc almost desc random
0
50
100
150
200
250
300
350
400
450
500
Sorting improvements in PostgreSQL 9.5
sort duration on 50M rows (TEXT)
PostgreSQL 9.4 PostgreSQL 9.5
dataset type
duration[seconds]](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-8-320.jpg)
![asc desc almost asc almost desc random
0
50
100
150
200
250
300
350
Sorting improvements in PostgreSQL 9.5
sort duration on 50M rows (NUMERIC)
PostgreSQL 9.4 PostgreSQL 9.5
dataset type
duration[seconds]](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-9-320.jpg)



![0
200000
400000
600000
800000
1000000
1200000
1400000
1600000
1800000
2000000
0
10000
20000
30000
40000
50000
PostgreSQL 9.5 Hash Join Improvements
join duration - 50M rows (outer), different NTUP_PER_BUCKET
NTUP_PER_BUCKET=10 NTUP_PER_BUCKET=1
hash size (number of tuples in dimension)
duration[miliseconds]](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-14-320.jpg)


![0.00% 20.00% 40.00% 60.00% 80.00% 100.00%
0
5000
10000
15000
20000
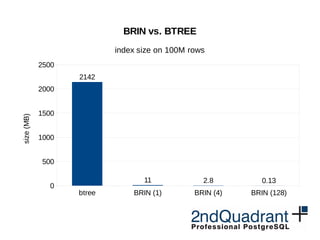
BRIN vs. BTREE
Bitmap Index Scan on 100M rows (sorted)
BTREE BRIN (128) BRIN (4)
fraction of table matching the condition
duration[miliseconds]](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-17-320.jpg)





![top
PID VIRT RES SHR S %CPU %MEM COMMAND
19018 32.8g 441m 427m R 100 0.2 postgres: sekondquad test [local] SELECT
20134 32.8g 80m 74m R 100 0.0 postgres: bgworker: parallel worker for PID 19018
20135 32.8g 80m 74m R 100 0.0 postgres: bgworker: parallel worker for PID 19018
20136 32.8g 80m 74m R 100 0.0 postgres: bgworker: parallel worker for PID 19018
20140 32.8g 80m 74m R 100 0.0 postgres: bgworker: parallel worker for PID 19018
20141 32.8g 80m 74m R 100 0.0 postgres: bgworker: parallel worker for PID 19018
20142 32.8g 80m 74m R 100 0.0 postgres: bgworker: parallel worker for PID 19018
20137 32.8g 80m 74m R 99 0.0 postgres: bgworker: parallel worker for PID 19018
20138 32.8g 80m 74m R 99 0.0 postgres: bgworker: parallel worker for PID 19018
20139 32.8g 80m 74m R 99 0.0 postgres: bgworker: parallel worker for PID 19018
16 0 0 0 S 0 0.0 [watchdog/2]
281 0 0 0 S 0 0.0 [khugepaged]
....](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-26-320.jpg)
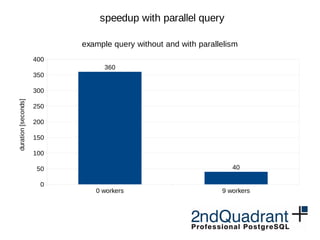
![0 workers 9 workers
0
50
100
150
200
250
300
350
400
360
40
speedup with parallel query
example query without and with parallelism
duration[seconds]](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-27-320.jpg)


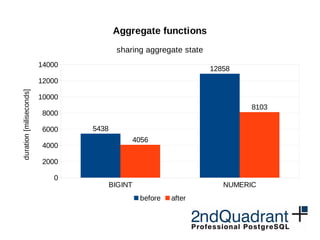
![BIGINT NUMERIC
0
2000
4000
6000
8000
10000
12000
14000
5438
12858
4056
8103
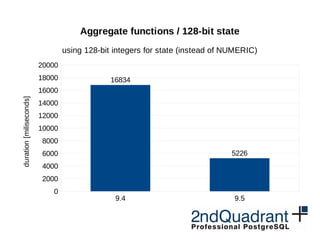
Aggregate functions
sharing aggregate state
before after
duration[miliseconds]](https://image.slidesharecdn.com/performance-milan-2016-160629080701/85/PostgreSQL-performance-improvements-in-9-5-and-9-6-31-320.jpg)



























































![[PGDay.Seoul 2020] PostgreSQL 13 New Features](https://cdn.slidesharecdn.com/ss_thumbnails/2020pgdayseoulpostgresql13newfeatures-201116014501-thumbnail.jpg?width=640&height=640&fit=bounds)







































