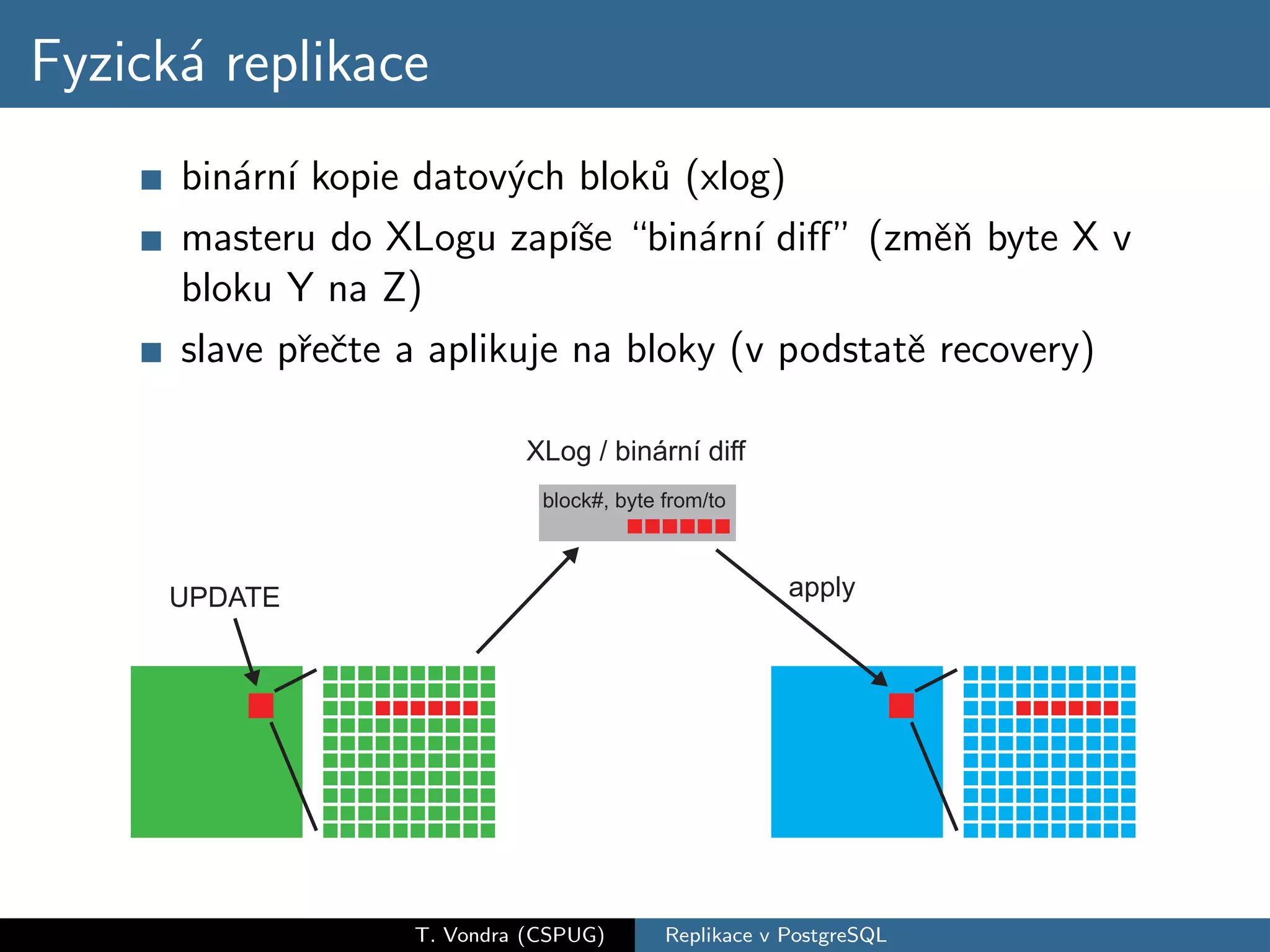
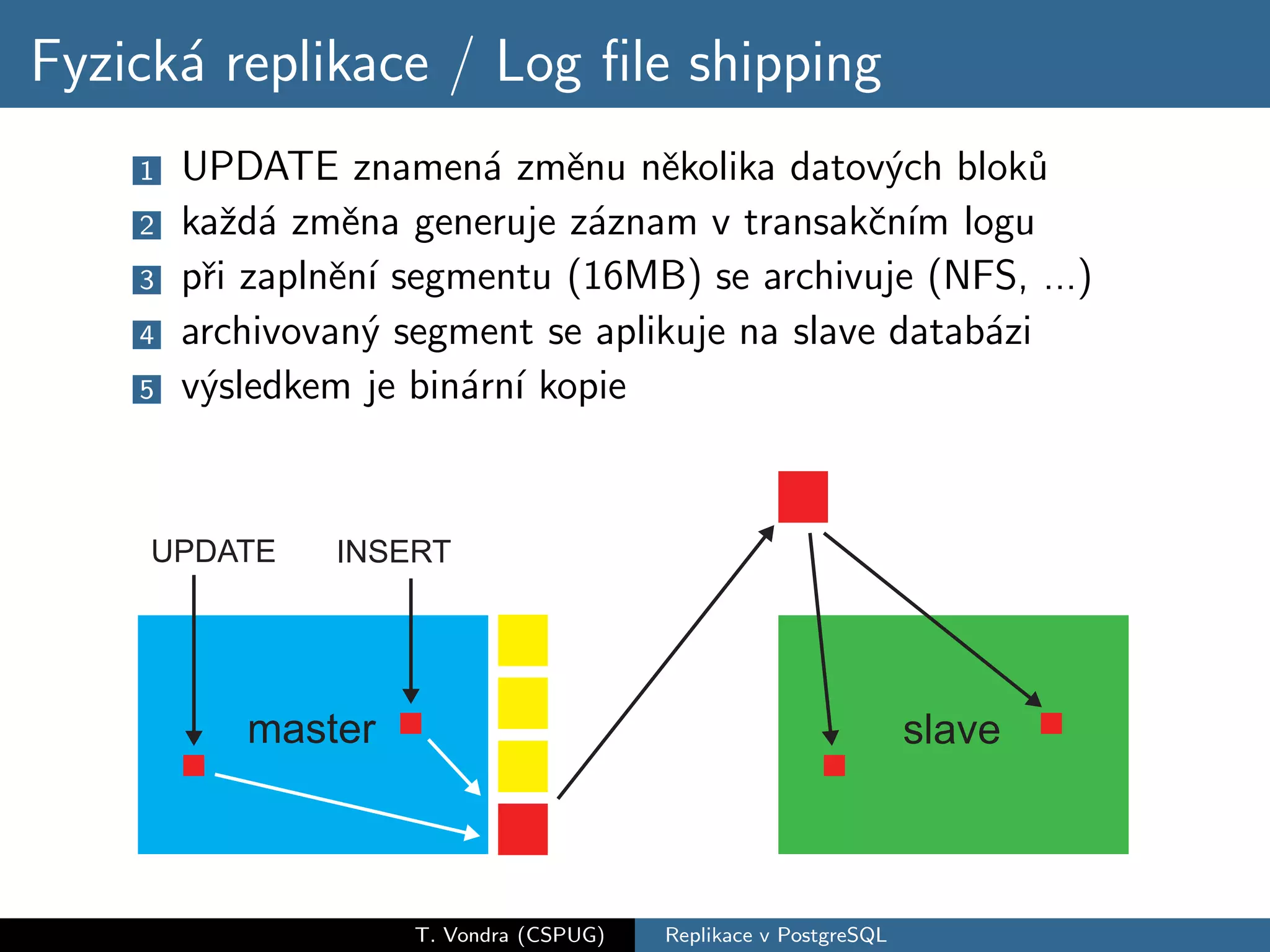
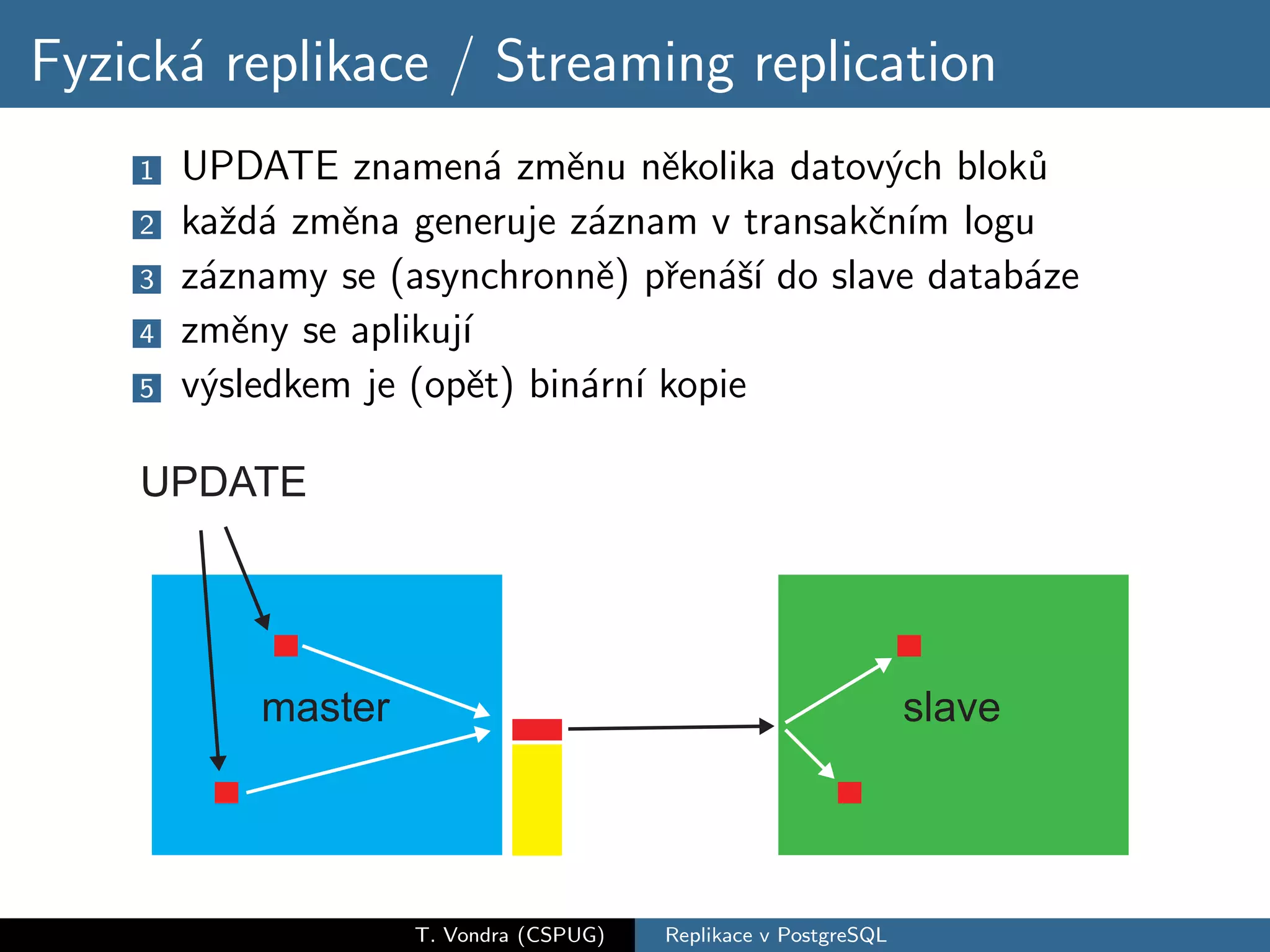
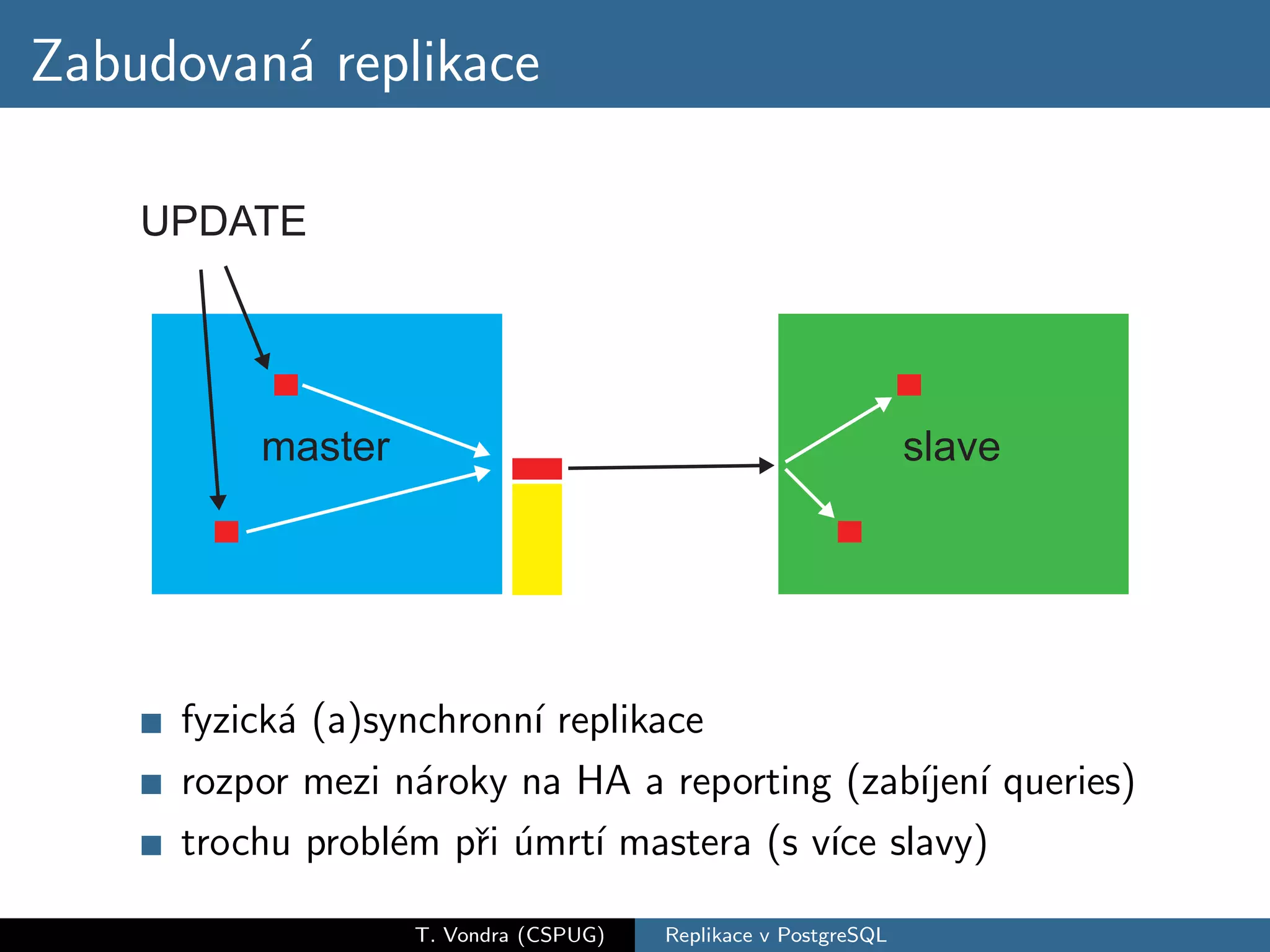
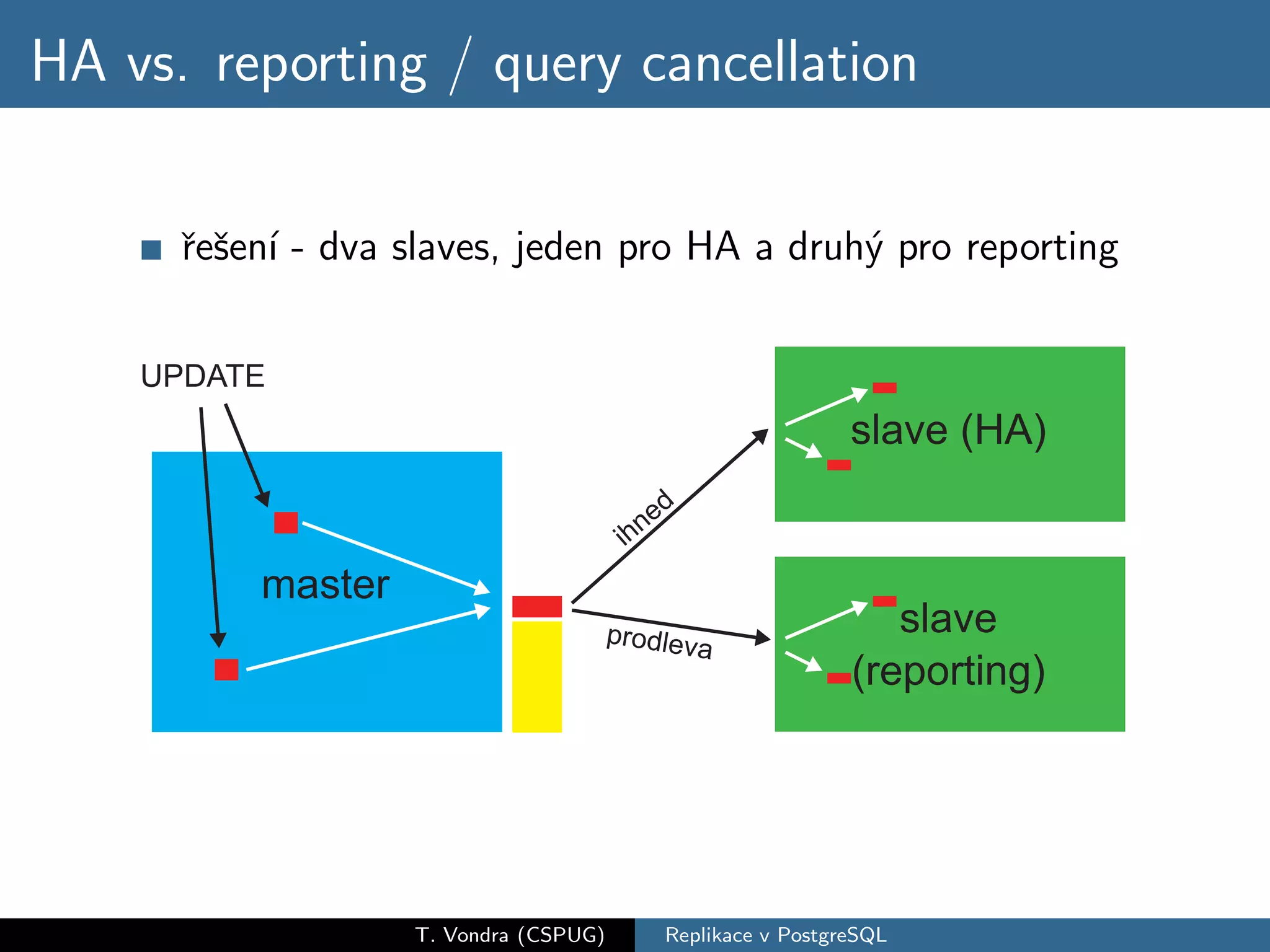
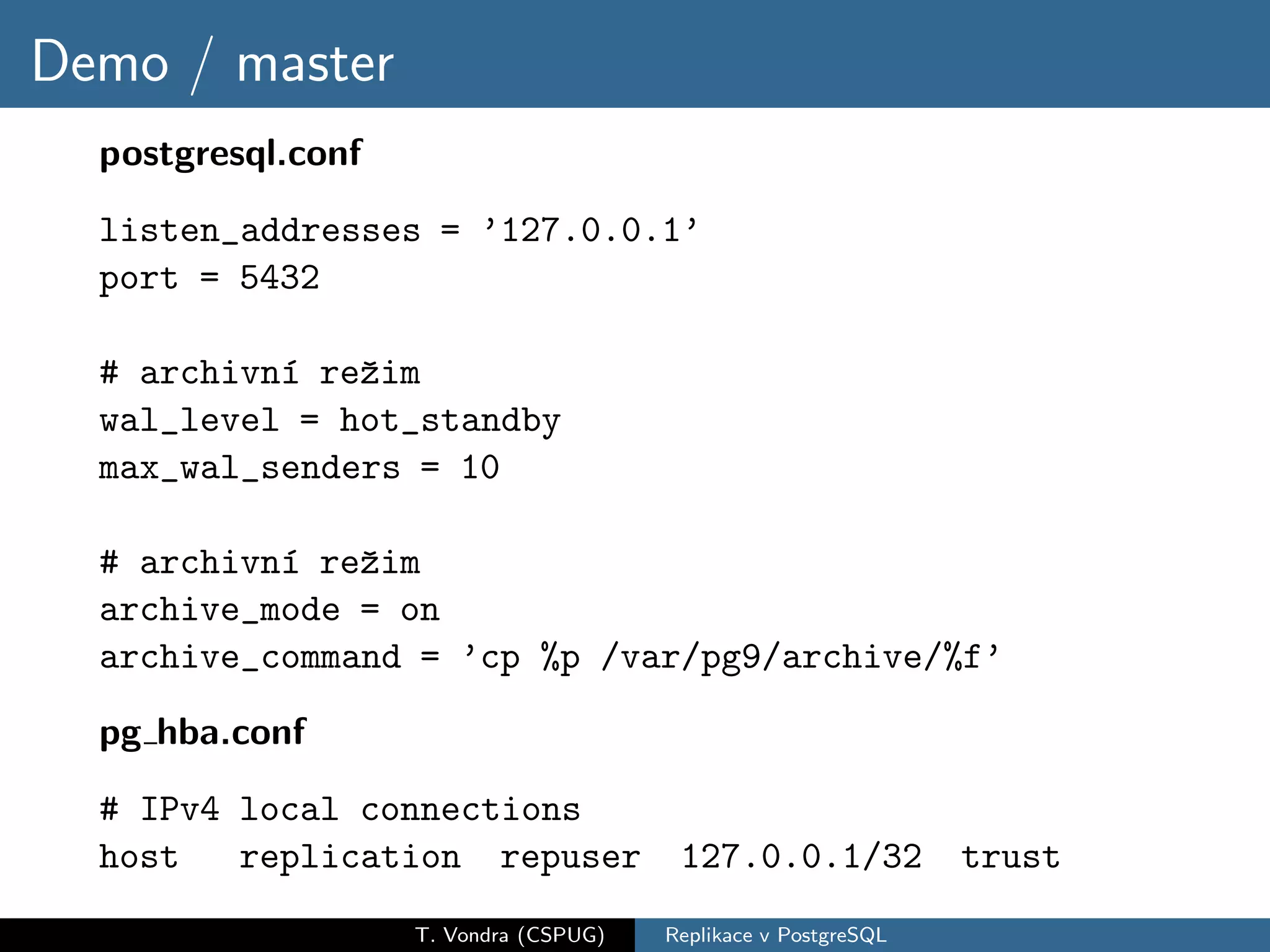
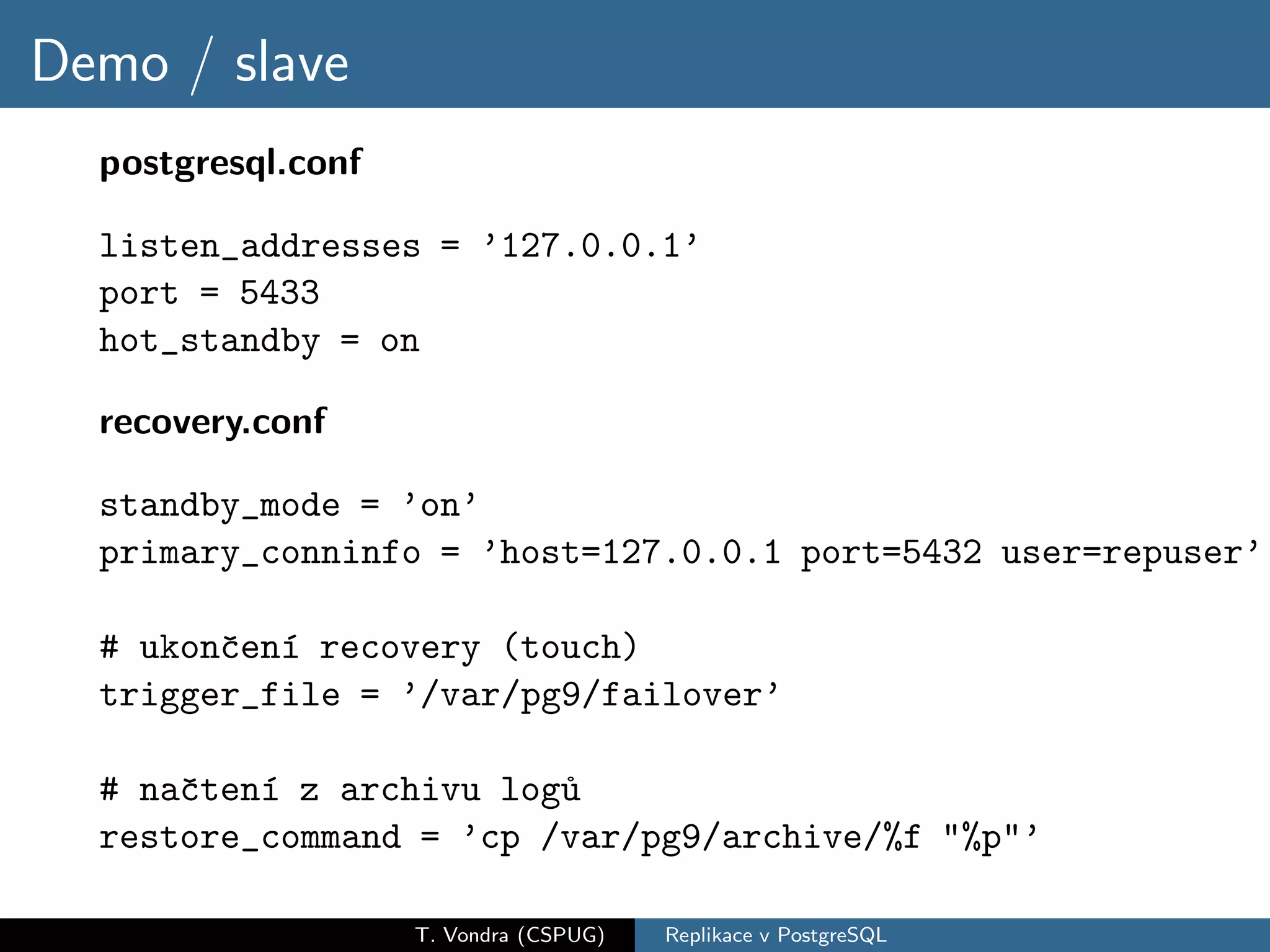
Přehled variant databázové replikace (master-slave vs. master-master, physical vs. logical) a jejich pro a proti. Krátká historie replikace v PostgreSQL s přehled nástrojů které dnes máme k dispozici (slony-I, pgpool-II, Londiste a Bucardo). A nakonec stručné srovnání s replikací ve dvou populárních databázích (MySQL a Oracle).