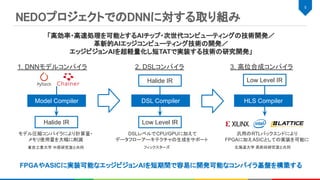
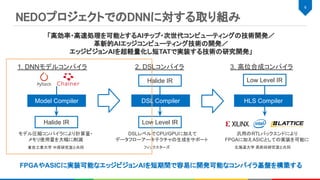
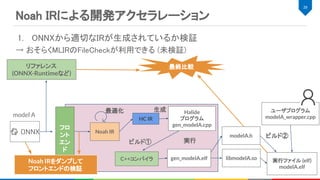
メリット:
各ベンダのデバイスに最適化された計算カーネルは高速
“monolithic kernel approach”と呼ばれる[1][2]
ONNXなど主要なフォーマットの変換もサポートされている
デバッグがしやすい
デメリット:
新しい計算カーネルの開発に時間がかかる
パラメータや入出力の精度のパターンが膨大で特殊化には限界がある[2]
個別の計算カーネルを跨いだ全体最適化が難しい
12
1. Machine Learning Systems are Stuck in a Rut, Paul Barham & Michael Isard, 2019, https://dl.acm.org/citation.cfm?id=3321441
2. VTA: A Hardware-Software Blueprint for Flexible Deep Learning Specialization, Thierry Moreau et al, 2018, https://arxiv.org/abs/1807.04188
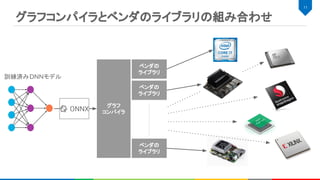
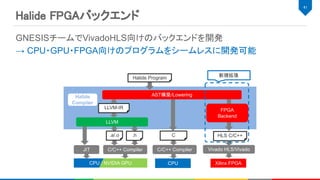
グラフコンパイラとベンダのライブラリの組み合わせ
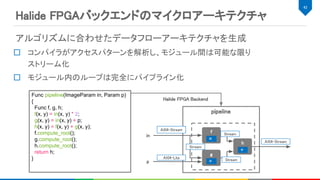
Halide FPGAバックエンドによるコードの生成
44
placeholder_0(c, x,y, n) = runtime_argument(c, x, y, n); // runtime_argumentは実行時に渡される
constant_0(c, x, y, n) = buffer(c, x, y, n);
pad_0 = BoundaryConditions::constant_exterior(placeholder_0, 0, {{0, C}, {0, X}, {0, Y}, {0, N}});
RDom rc_0(0, C), rx_0(0, KX), ry_0(0, KY); // convは縮約領域内の重み付き和で表現
conv_0(c, x, y, n) += pad_0(rc_0, x * SX + rx_0 - PX, y * SY + ry_0 - PY, n) * constant_0(rc, rx, ry, c);
add_0(c, x, y, n) += conv_0 + biased_0(n); // バイアスは入力とバイアス値の加算で表現
relu_0(c, x, y, n) = max(add_0(c, x, y, n), 0); // reluは入力と0のmaxで表現
pad_1 = BoundaryConditions::constant_exterior(add_0, 0, {{0, C}, {0, X}, {0, Y}, {0, N}});
RDom rx_1(0, KX), ry_1(0, KY); // maxpoolingは縮約領域内のmaxで表現
maxpool_0(c, x, y, n) = maximum(r, pad_1(c, x * SX + rx_1 - P, y * SY + ry_1 - P, n));
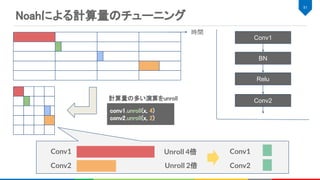
この計算パイプラインをモノリシック計算カーネルで構築すると...
(全ての関数を compute_root でスケジュールすることで再現可能)
45.
45
// conv_0の初期化
for conv_0_n:
forconv_0_y:
for conv_0_x:
for conv_0_c:
conv_0(...) = 0
// conv_0の計算
for conv_0_n:
for conv_0_y:
for conv_0_x:
for conv_0_c:
for ry_0:
for rx_0:
for rc_0:
conv_0(...) = …
// add_0の計算 (バイアス)
for add_0_n:
for add_0_y:
for add_0_x:
for add_0_c:
add_0(...) = ...
// relu_0の計算
for relu_0_3:
for relu_0_2:
for relu_0_1:
for relu_0_0:
relu_0(...) = …
// maxpool_0の計算
for maxpool_0_n:
for maxpool_0_y:
for maxpool_0_x:
for maxpool_0_c:
// maxpoolのリダクション
for ry_1:
for rx_1:
maximum(...) = ...
consume maximum
maxpool_0(...) = ...
モノリシック計算カーネルでのループのイメージ
46.
46
// conv_0の初期化
for conv_0_n:
forconv_0_y:
for conv_0_x:
for conv_0_c:
conv_0(...) = 0
// conv_0の計算
for conv_0_n:
for conv_0_y:
for conv_0_x:
for conv_0_c:
for ry_0:
for rx_0:
for rc_0:
conv_0(...) = …
// add_0の計算 (バイアス)
for add_0_n:
for add_0_y:
for add_0_x:
for add_0_c:
add_0(...) = ...
// relu_0の計算
for relu_0_3:
for relu_0_2:
for relu_0_1:
for relu_0_0:
relu_0(...) = …
// maxpool_0の計算
for maxpool_0_n:
for maxpool_0_y:
for maxpool_0_x:
for maxpool_0_c:
// maxpoolのリダクション
for ry_1:
for rx_1:
maximum(...) = ...
consume maximum
maxpool_0(...) = ...
モノリシック計算カーネルでのループのイメージ
計算カーネル間のバッファにムダが発生
これはFPGAでは致命的!!
47.
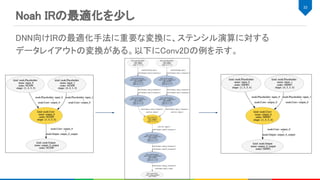
Halide FPGAバックエンドによるコードの生成
47
placeholder_0(c, x,y, n) = runtime_argument(c, x, y, n); // runtime_argumentは実行時に渡される
constant_0(c, x, y, n) = buffer(c, x, y, n);
pad_0 = BoundaryConditions::constant_exterior(placeholder_0, 0, {{0, C}, {0, X}, {0, Y}, {0, N}});
RDom rc_0(0, C), rx_0(0, KX), ry_0(0, KY); // convは縮約領域内の重み付き和で表現
conv_0(c, x, y, n) += pad_0(rc_0, x * SX + rx_0 - PX, y * SY + ry_0 - PY, n) * constant_0(rc, rx, ry, c);
add_0(c, x, y, n) += conv_0 + biased_0(n); // バイアスは入力とバイアス値の加算で表現
relu_0(c, x, y, n) = max(add_0(c, x, y, n), 0); // reluは入力と0のmaxで表現
pad_1 = BoundaryConditions::constant_exterior(add_0, 0, {{0, C}, {0, X}, {0, Y}, {0, N}});
RDom rx_1(0, KX), ry_1(0, KY); // maxpoolingは縮約領域内のmaxで表現
maxpool_0(c, x, y, n) = maximum(r, pad_1(c, x * SX + rx_1 - P, y * SY + ry_1 - P, n));
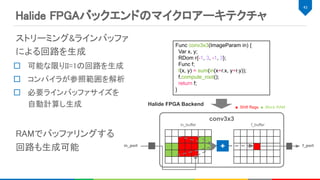
ステンシル計算(conv_0, maxpool_0)にcompute_inline,
ポイントワイズ計算(add_0, relu_0) にcompute_root でスケジュール
48.
48
// conv_0の初期化 (Halideだと初期化は別ループになる)
forconv_0_n:
for conv_0_y:
for conv_0_x:
for conv_0_c:
conv_0(...) = 0
// conv_0の計算
for conv_0_n:
for conv_0_y:
for conv_0_x:
for conv_0_c:
for ry_0:
for rx_0:
for rc_0:
conv_0(...) = …
// ポイントワイス演算のループを融合した
add_0(...) = …
relu_0(...) = …
// maxpool_0の計算はconv_0とは別のループになる
for maxpool_0_n:
for maxpool_0_y:
for maxpool_0_x:
for maxpool_0_c:
// maxpoolのリダクション
for ry_1:
for rx_1:
maximum(...) = ...
consume maximum
maxpool_0(...) = ...
FPGA向けに最適化したループのイメージ
49.
49
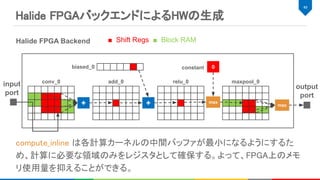
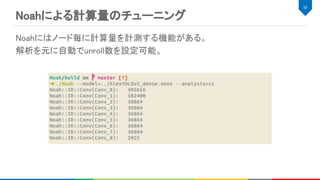
Halide FPGAバックエンドによるHWの生成
conv_0 add_0
■Shift Regs ■ Block RAMHalide FPGA Backend
+
relu_0 maxpool_0
+
biased_0
max
0 constant
max
input
port
output
port
compute_inline は各計算カーネルの中間バッファが最小になるようにするた
め、計算に必要な領域のみをレジスタとして確保する。よって、FPGA上のメモ
リ使用量を抑えることができる。
参考
1. Paul Barhamand Michael Isard. 2019. Machine Learning Systems are Stuck in a Rut. In Proceedings of the Workshop on Hot Topics in
Operating Systems (HotOS '19). ACM, New York, NY, USA, 177-183. DOI: https://doi.org/10.1145/3317550.3321441
2. Thierry Moreau and Tianqi Chen and Luis Vega and Jared Roesch and Eddie Yan and Lianmin Zheng and Josh Fromm and Ziheng Jiang
and Luis Ceze and Carlos Guestrin and Arvind Krishnamurthy, 2018. A Hardware-Software Blueprint for Flexible Deep Learning
Specialization, https://arxiv.org/abs/1807.04188
3. J.Ragan-Kelley, et al. Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing
Pipelines. In Proceedings of the 34th, ACM SIGPLAN Conference on Programming Language Design and Implementation, 519–530,
2013.
4. MLIR, 2019, https://github.com/tensorflow/mlir
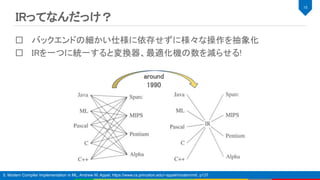
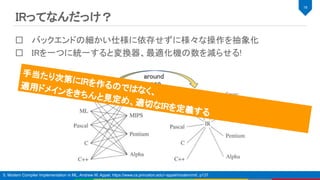
5. Andrew W. Appel, Modern Compiler Implementation in ML, 1998, Published by Cambridge University Press, ISBN 0-521-60764-7,
https://www.cs.princeton.edu/~appel/modern/ml/
55








![メリット:
各ベンダのデバイスに最適化された計算カーネルは高速
“monolithic kernel approach”と呼ばれる [1][2]
ONNXなど主要なフォーマットの変換もサポートされている
デバッグがしやすい
デメリット:
新しい計算カーネルの開発に時間がかかる
パラメータや入出力の精度のパターンが膨大で特殊化には限界がある[2]
個別の計算カーネルを跨いだ全体最適化が難しい
12
1. Machine Learning Systems are Stuck in a Rut, Paul Barham & Michael Isard, 2019, https://dl.acm.org/citation.cfm?id=3321441
2. VTA: A Hardware-Software Blueprint for Flexible Deep Learning Specialization, Thierry Moreau et al, 2018, https://arxiv.org/abs/1807.04188
グラフコンパイラとベンダのライブラリの組み合わせ](https://image.slidesharecdn.com/20190928dlaccel-191031064940/85/slide-12-320.jpg)


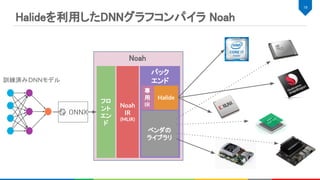
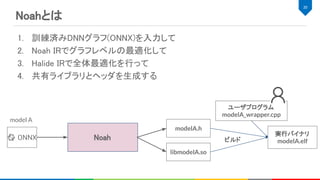

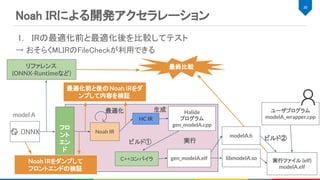
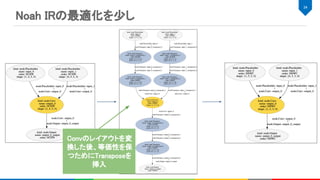
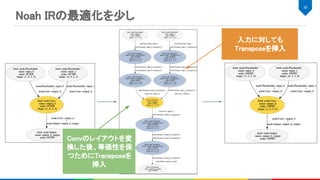
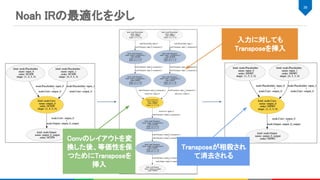
![Noah IR
MLIRとは
Multi Layer Internal Representationの略
IRを構築、IR同士の変換する仕組みを提供
IRのダンプ、パースなどのIO機能 (シリアライズも?)
CSE, DCEなどの一般的なコンパイラ最適化や独自パス構築用の基盤を提供
LLVM Dialect、Affine Dialect、GPU用Dialectなど多様なIRが実装済み
22
4. MLIR, https://github.com/tensorflow/mlir
MLIRベースの中間表現で、各ノードにおける演算に必要な情報を全て含んで
いる。
%10 = "noah.Conv"(%0, %4) {
dilations = [1, 1], group = 1 : i64, kernel_shape = [5, 5], name = "Convolution28_Output_0",
order = "NCHW", pads = [2, 2, 2, 2], strides = [1, 1]
} : (tensor<1x1x28x28xf32>, tensor<8x1x5x5xf32>) -> tensor<1x8x28x28xf32>](https://image.slidesharecdn.com/20190928dlaccel-191031064940/85/slide-22-320.jpg)
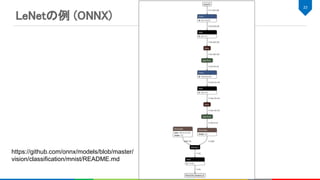
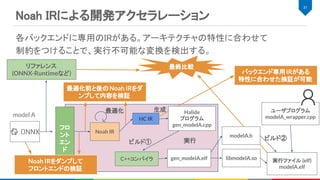
![LeNetの例 (Noah IR)
24
module {
func @LeNetFromONNX(%arg0: tensor<1x1x28x28xf32>) -> tensor<1x10xf32> {
%0 = "noah.Placeholder"() {name = "Input3"} : () -> tensor<1x1x28x28xf32>
%1 = "noah.Constant"() {name = "Parameter193", value = dense<[...]> : tensor<16x4x4x10xf32>} : () ->
tensor<16x4x4x10xf32>
...
%8 = "noah.Constant"() {name = "Pooling160_Output_0_reshape0_shape", value = dense<[1, 256]> : tensor<2xi64>} : () ->
tensor<2xi64>
%9 = "noah.Reshape"(%1, %2) {name = "Parameter193_reshape1"} : (tensor<16x4x4x10xf32>, tensor<2xi64>) ->
tensor<256x10xf32>
%10 = "noah.Conv"(%0, %4) {dilations = [1, 1], group = 1 : i64, kernel_shape = [5, 5], name = "Convolution28_Output_0",
order = "NCHW", pads = [2, 2, 2, 2], strides = [1, 1]} : (tensor<1x1x28x28xf32>, tensor<8x1x5x5xf32>) ->
tensor<1x8x28x28xf32>
...
%22 = "noah.Reshape"(%21, %8) {name = "Pooling160_Output_0_reshape0"} : (tensor<1x16x4x4xf32>, tensor<2xi64>) ->
tensor<1x256xf32>
%23 = "noah.MatMul"(%22, %9) {name = "Times212_Output_0"} : (tensor<1x256xf32>, tensor<256x10xf32>) ->
tensor<1x10xf32>
%24 = "noah.Add"(%23, %3) {name = "Plus214_Output_0"} : (tensor<1x10xf32>, tensor<1x10xf32>) -> tensor<1x10xf32>
"noah.Output"(%24) {name = "Plus214_Output_0_output"} : (tensor<1x10xf32>) -> ()
}
}](https://image.slidesharecdn.com/20190928dlaccel-191031064940/85/slide-24-320.jpg)
![Tablegenを用いたNoah IRの定義
25
# Noah/Ops.td (TablegenはLLVMのC++のソースコードを生成する独自 DSL)
def NOAH_ConvOp : NOAH_Op<"Conv", [NoSideEffect]> {
let summary = "Comment for Convolution operator";
let arguments = (ins // 実際の引数の定義
StrAttr:$name,
NOAH_4DTensor:$X,
NOAH_4DTensor:$W,
Variadic<NOAH_1DTensor>:$B, // オプショナルな入力
Confined<I64ArrayAttr, [ArrayMinCount<2>]>:$kernel_shape,
Confined<I64ArrayAttr, [ArrayMinCount<2>]>:$strides,
Confined<I64ArrayAttr, [ArrayMinCount<2>]>:$dilations,
Confined<I64ArrayAttr, [ArrayMinCount<4>]>:$pads,
I64Attr:$group,
DefaultValuedAttr<NOAH_DataOrderKind, "NCHW">:$order // デフォルト付きレイアウト
);
let results = (outs NOAH_4DTensor:$Y);
}](https://image.slidesharecdn.com/20190928dlaccel-191031064940/85/slide-25-320.jpg)
![Tablegenを用いたIRの成約と検証
26
# f32, f64, i32, i64のみを対象とする成約
def NOAH_ElementType : Type<
Or<[I32.predicate, I64.predicate, F32.predicate, F64.predicate]>,
"noah.element_type"
>;
# MLIRの標準型 “RankedTensorType” を継承して、データ型の制約をつける
def NOAH_Tensor : StaticShapeTensorOf<[NOAH_ElementType]>;
# 4次元であることを保証する成約
def IsRank4D : CPred<"$_self.cast<RankedTensorType>().getRank() == 4">;
# 4次元かつf32, f64, i32, i64であることを保証する成約
def NOAH_4DTensor
: Type<And<[NOAH_Tensor.predicate, Is4DTensor]>>;](https://image.slidesharecdn.com/20190928dlaccel-191031064940/85/slide-26-320.jpg)

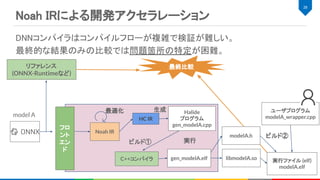

![Halideについて
画像処理の高性能計算に特化したドメイン固有言語(DSL) [3]
特徴
C++の内部DSLとして実装
アルゴリズムとスケジューリングを分離して記述
– 純粋関数型言語による簡素なアルゴリズム記述
– 最適化方法を指定するスケジューリング記述
様々なHWターゲットに対する最適化・コード生成が可能
ターゲット: x86, ARM, POWER, MIPS, NVIDIA GPGPU, Hexagon
出力形式: LLVM-IR, C/C++, OpenCL, OpenGL, Matlab, Metal など
37
3. Halide, https://halide-lang.org/](https://image.slidesharecdn.com/20190928dlaccel-191031064940/85/slide-37-320.jpg)























![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]AlphaStarとその関連技術](https://cdn.slidesharecdn.com/ss_thumbnails/dlalphastar-190605035416-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


































