Downloaded 302 times



































![MongoDB Example
> // map function > // reduce function
> m = function(){ > r = function( key , values ){
... this.tags.forEach( ... var total = 0;
... function(z){ ... for ( var i=0; i<values.length; i++ )
... emit( z , { count : 1 } ... total += values[i].count;
); ... return { count : total };
... } ...};
... );
...};
> // execute
> res = db.things.mapReduce(m, r, { out : "myoutput" } );
42](https://image.slidesharecdn.com/ddemsak-introtobigdataandnosql-120422051419-phpapp01/75/Intro-to-Big-Data-and-NoSQL-42-2048.jpg)



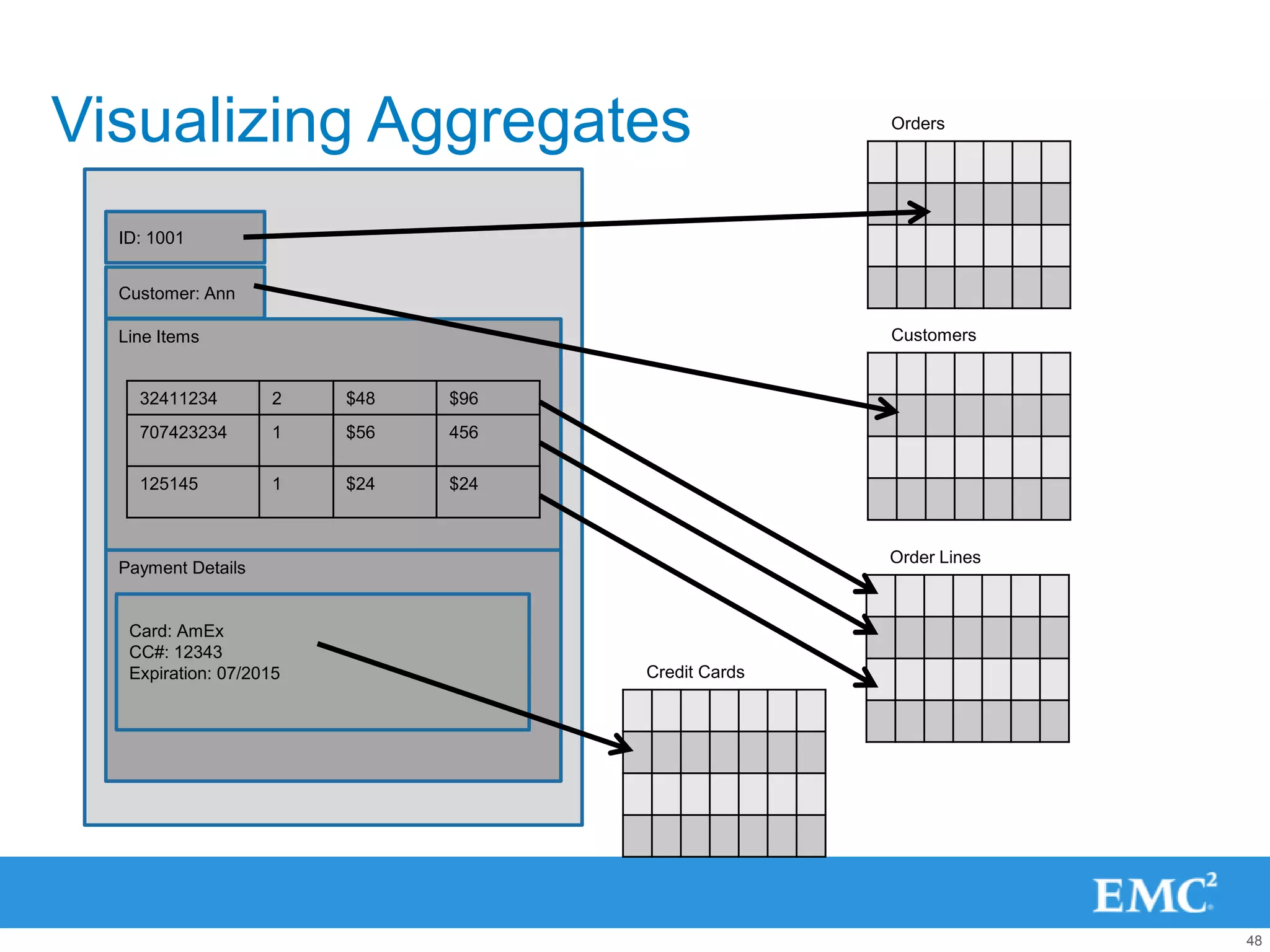
![Visualizing Aggregates
ID: 1001
Customer: Ann
Line Items
32411234 2 $48 $96 {
“SalesOrdersView”:{
707423234 1 $56 456 ID: 1001,
Customer: Ann,
125145 1 $24 $24 LineItems: []
……………..
…………….
……………..
Payment Details
}
}
Card: AmEx
CC#: 12343
Expiration: 07/2015
49](https://image.slidesharecdn.com/ddemsak-introtobigdataandnosql-120422051419-phpapp01/75/Intro-to-Big-Data-and-NoSQL-49-2048.jpg)




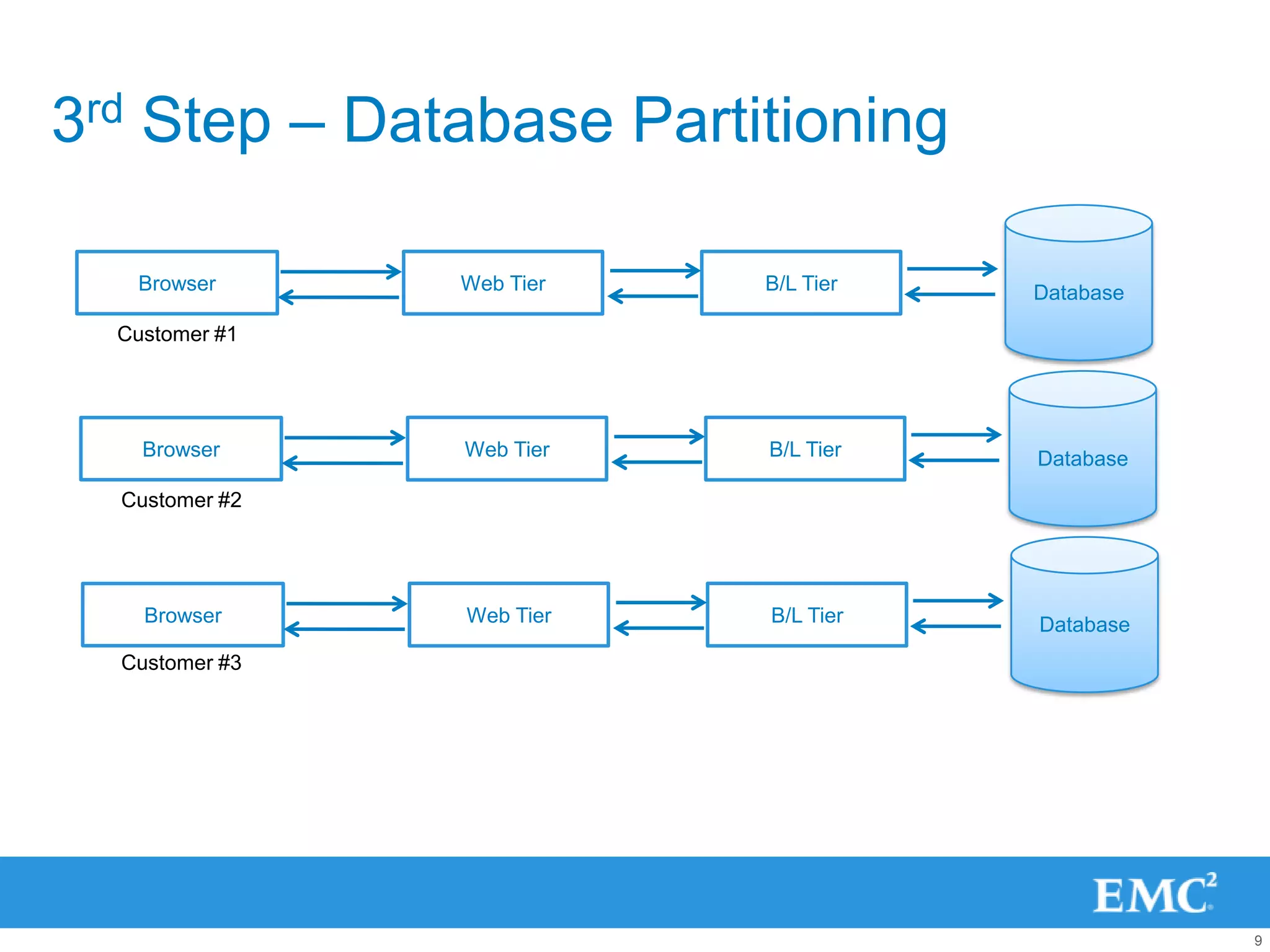
This document provides an introduction to big data and NoSQL databases. It begins with an introduction of the presenter. It then discusses how the era of big data came to be due to limitations of traditional relational databases and scaling approaches. The document introduces different NoSQL data models including document, key-value, graph and column-oriented databases. It provides examples of NoSQL databases that use each data model. The document discusses how NoSQL databases are better suited than relational databases for big data problems and provides a real-world example of Twitter's use of FlockDB. It concludes by discussing approaches for working with big data using MapReduce and provides examples of using MongoDB and Azure for big data.















































































