Download as PDF, PPTX





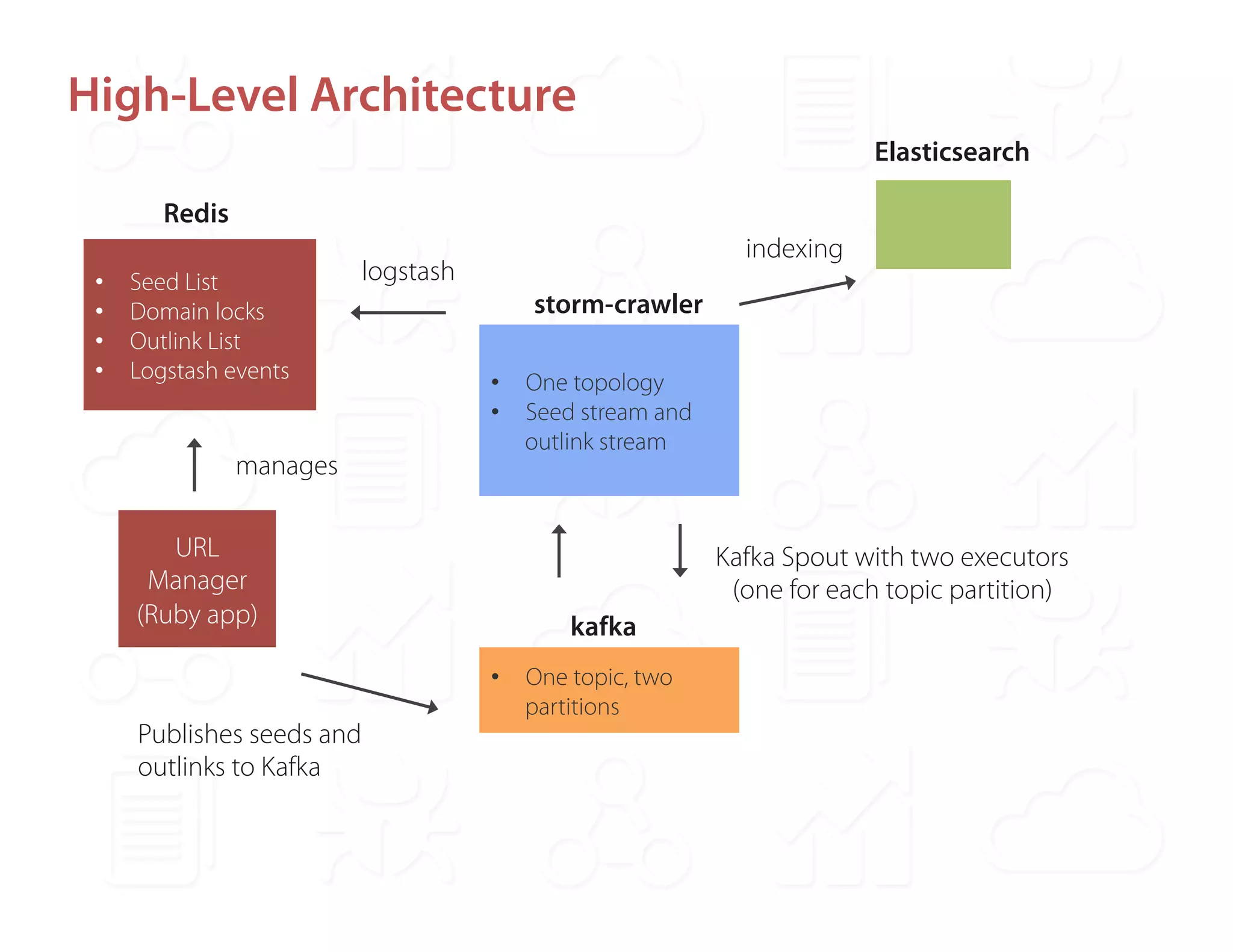
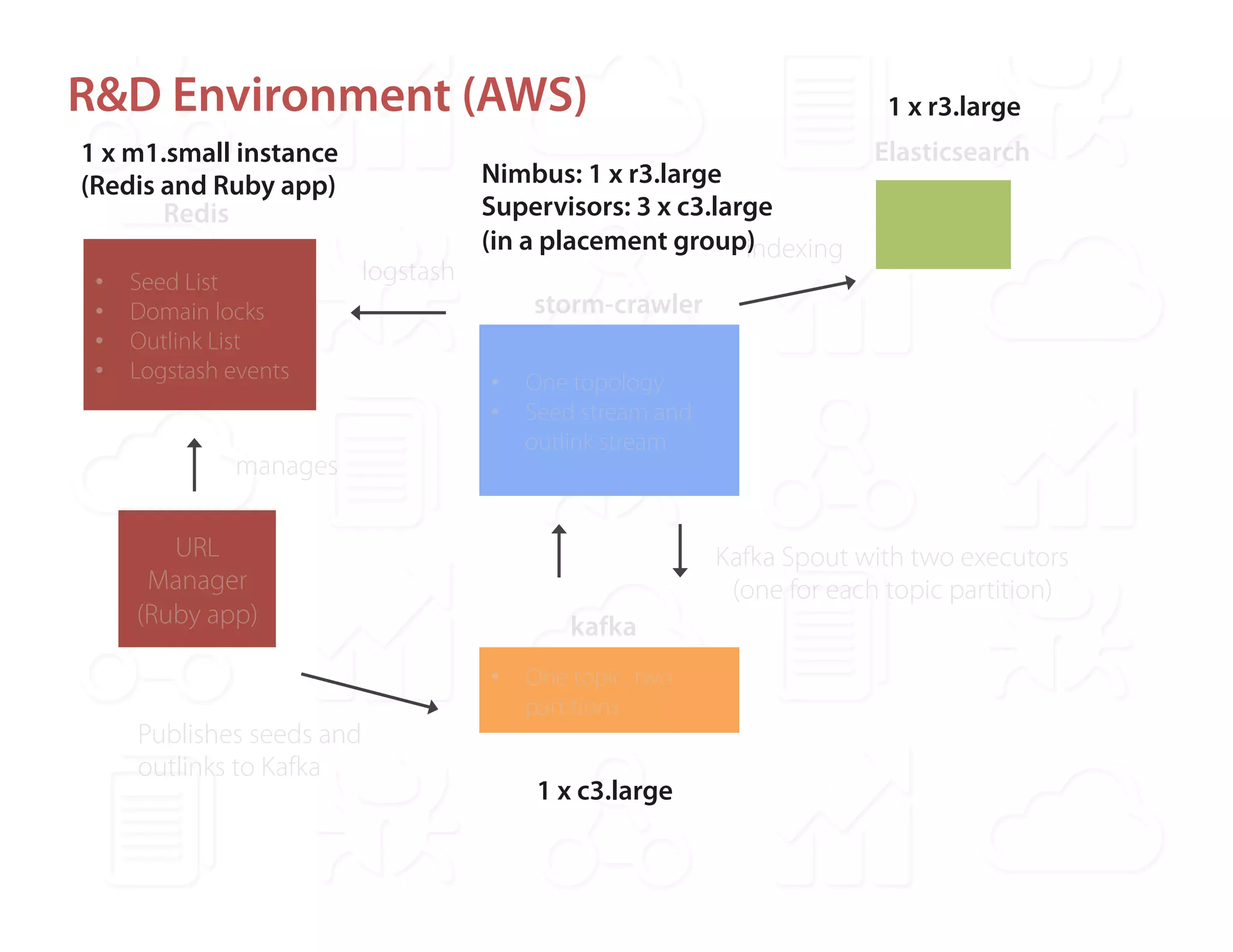
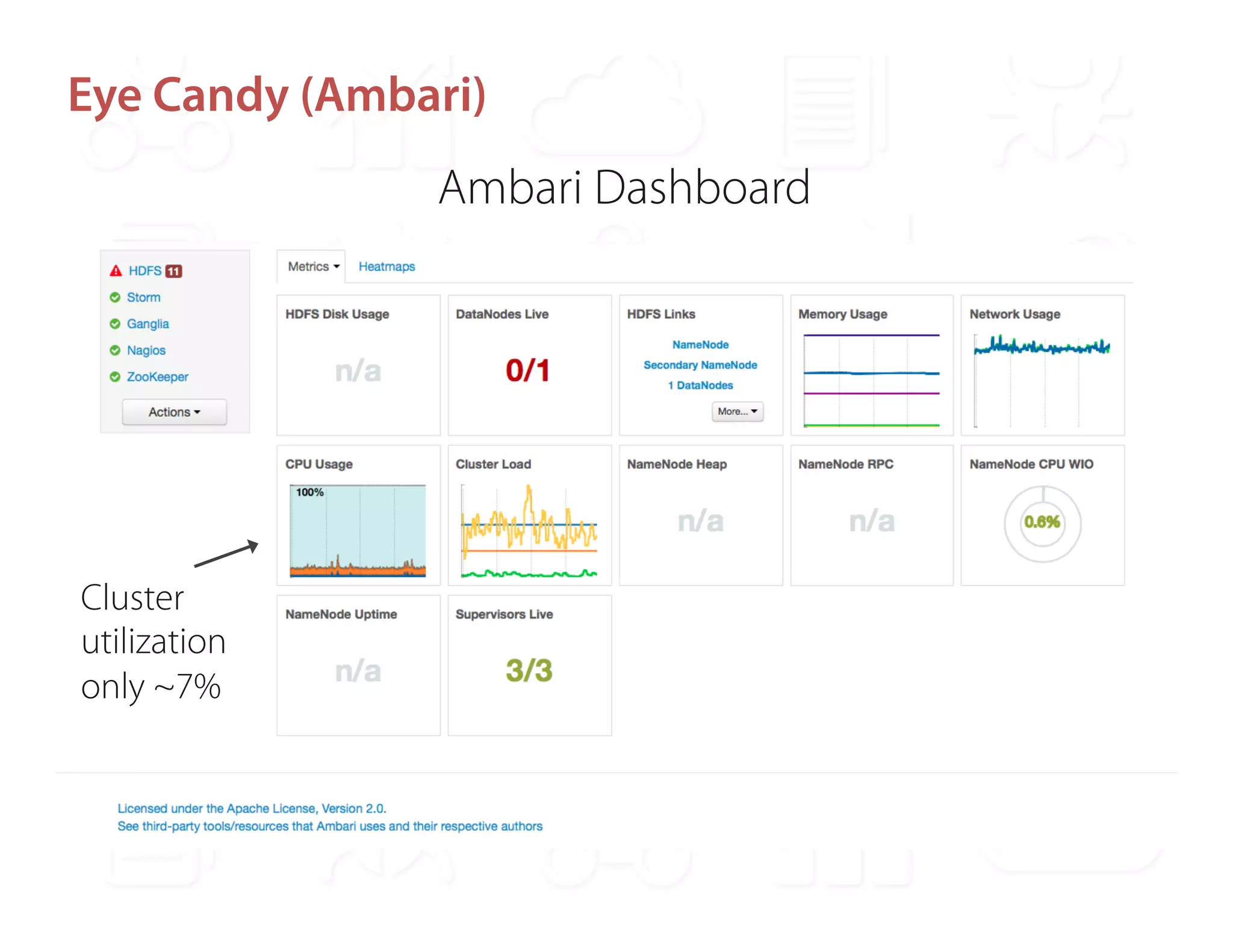

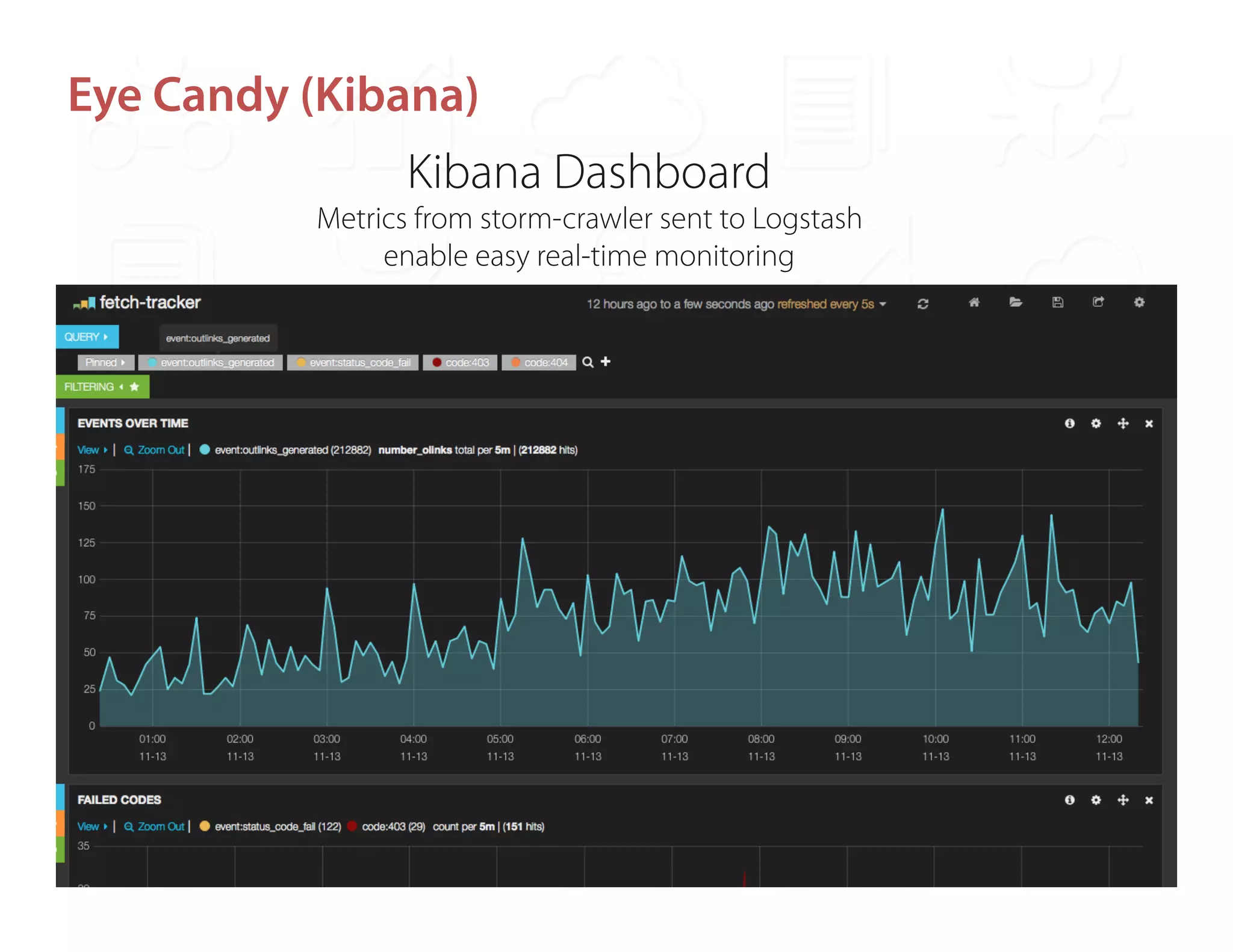


Ontopic is a fintech startup in Los Angeles focused on developing a real-time web monitoring engine for qualitative financial research, utilizing the StormCrawler framework integrated with technologies like Kafka and Redis. They have successfully monitored around 2,000 sources while achieving a high throughput of approximately 800,000 URLs per day without scalability concerns. Ontopic is also committed to open-sourcing their developments and contributing to the StormCrawler project by providing tutorials and integration points.













































































