Download as PDF, PPTX







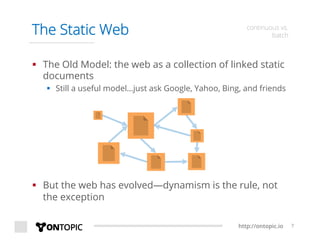
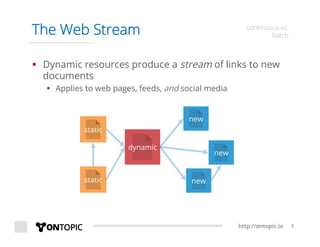




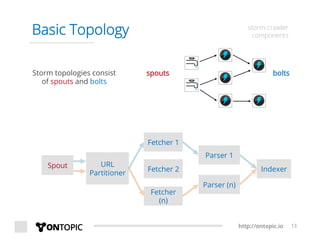









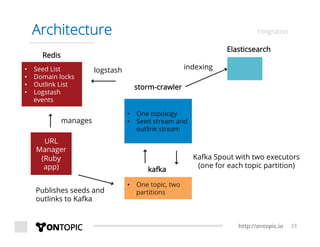
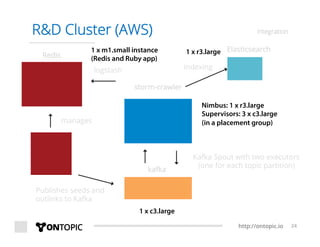





The document provides an overview of Storm Crawler, a real-time distributed web crawling framework built on Apache Storm, allowing for continuous and efficient crawling. It discusses the advantages of continuous crawling over traditional batch methods, highlighting low latency and better resource allocation. The document also outlines the components of Storm Crawler and its integration with technologies like Elasticsearch and Kafka, along with various use cases and deployment examples.






















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












