Download to read offline





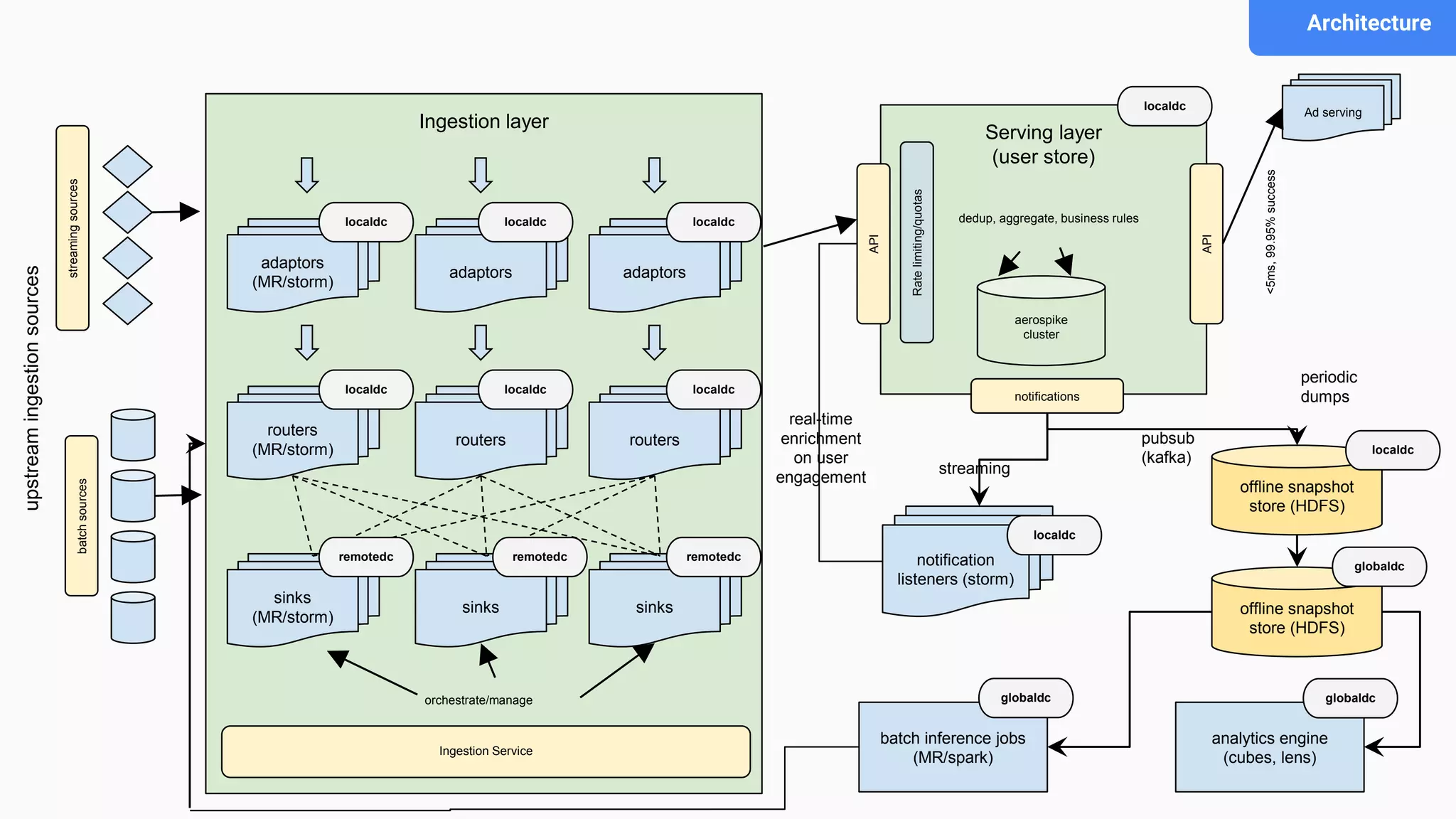
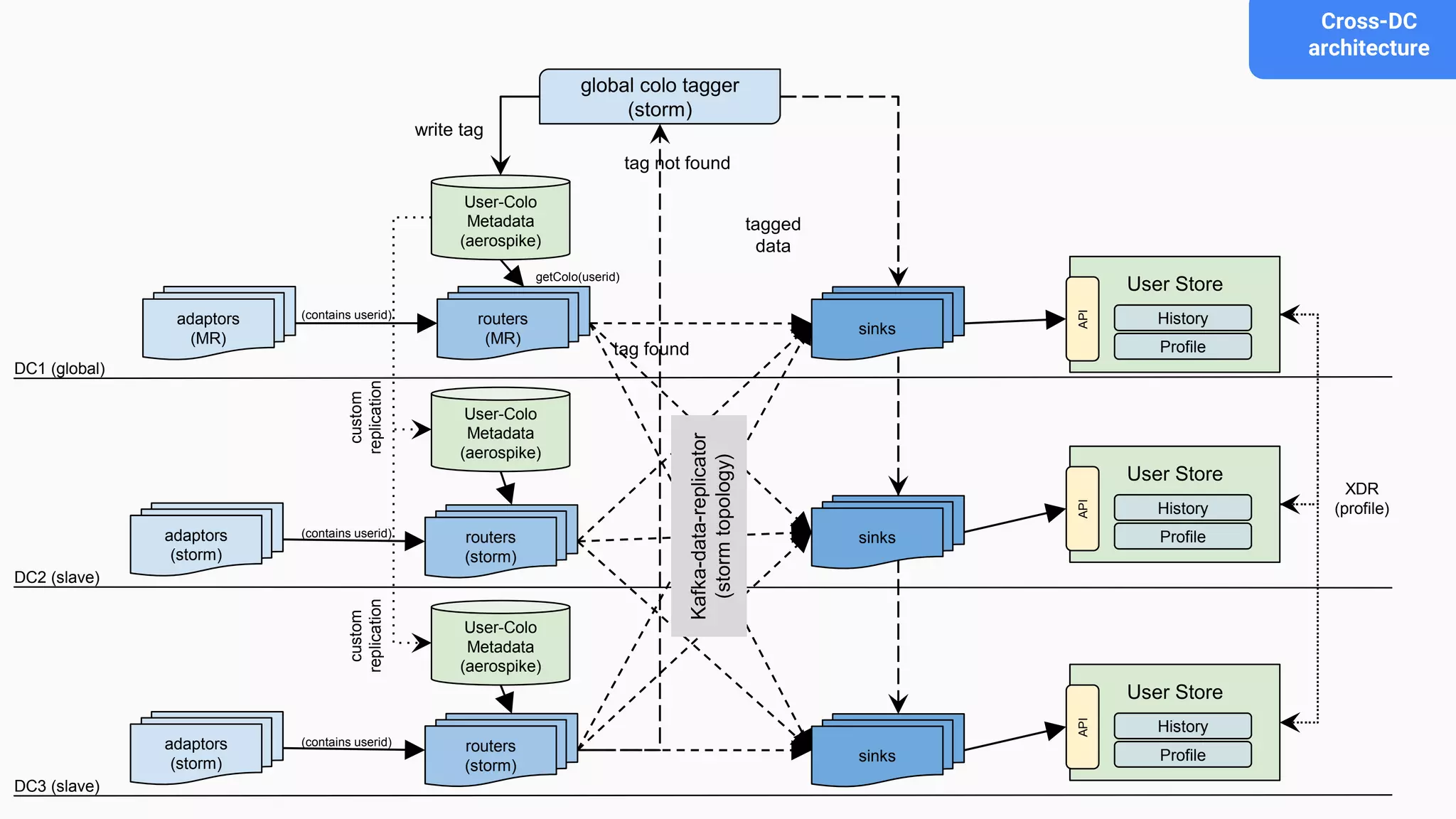
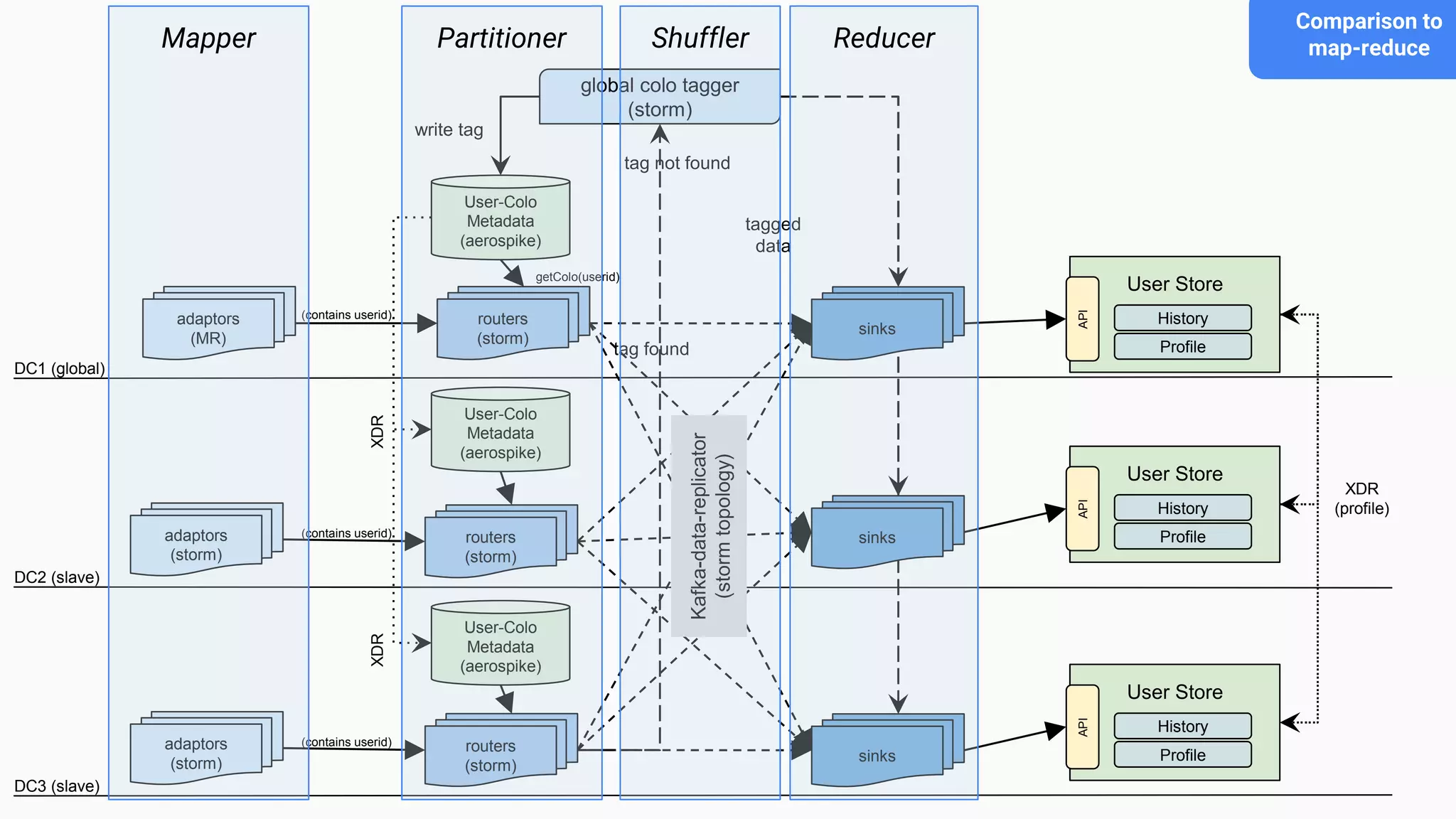

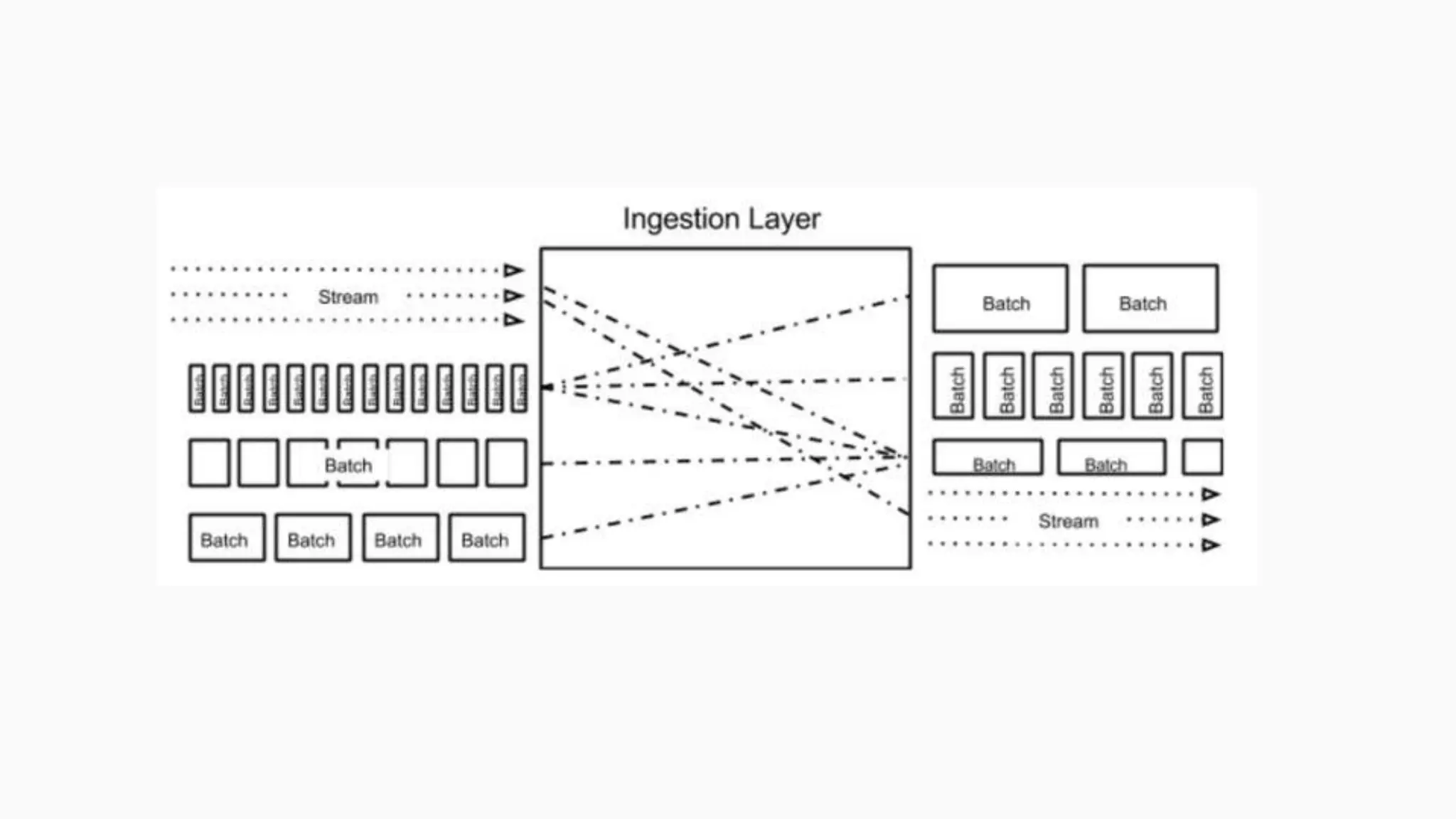







This document discusses an adaptive and self-healing framework for real-time data ingestion across geographically distributed data centers. It describes the problem domain of ingesting 15 billion events per day across multiple schemas and data types from various sources. The proposed architecture includes an ingestion layer using technologies like Storm, Kafka and HDFS to ingest, transform and replicate streaming and batch data. It also includes a serving layer using Aerospike to provide low-latency aggregated user views. Issues encountered with technologies like Storm and Kafka are discussed, as well as features still under development.


































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)







![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)





