Downloaded 229 times








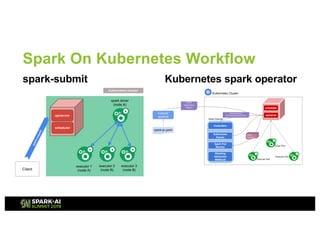

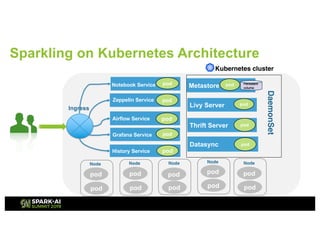


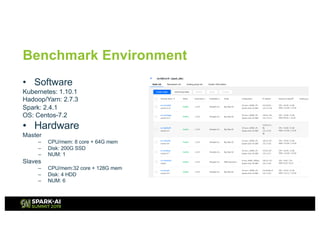
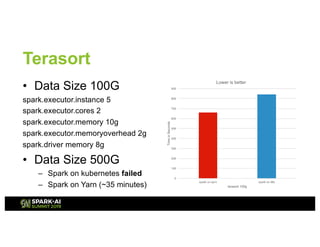


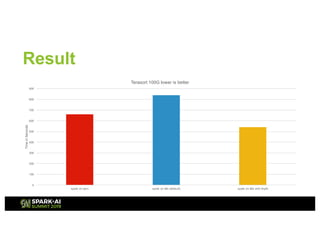

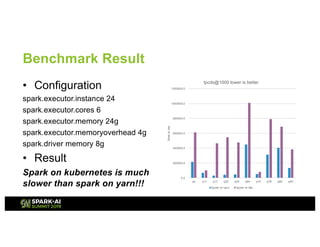



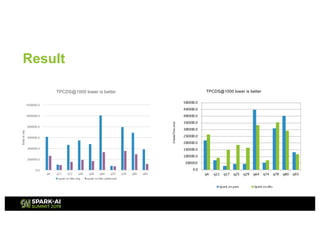




The document presents an overview of Tencent Cloud's implementation of Spark on Kubernetes, detailing architecture, best practices, and performance benchmarks. It discusses the motivations behind using Dockerized Spark, the advantages of Kubernetes, and the challenges faced when transitioning from a Yarn setup. Additionally, it provides insights into benchmarking results, root cause analysis of performance issues, and future work aimed at improving Spark's integration with Kubernetes.




































![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)


















































