Download as PDF, PPTX
















![Schema Metastore
_schemas
{“ID”:1,
“ProductName”:“Belt”}
{
"type": "struct",
"fields": [
{
"name": "ID",
"type": “string",
"nullable": true,
"metadata": {}
},
{
"name": "ProductName",
"type": “string",
"nullable": true,
"metadata": {}
}
]
}
0
On First Read](https://image.slidesharecdn.com/1060simonwhiteley-210614173625/85/Accelerating-Data-Ingestion-with-Databricks-Autoloader-30-320.jpg)
![Schema Metastore – DataType Inference
_schemas
{“ID”:1,
“ProductName”:“Belt”}
{
"type": "struct",
"fields": [
{
"name": "ID",
"type": “int",
"nullable": true,
"metadata": {}
},
{
"name": "ProductName",
"type": “string",
"nullable": true,
"metadata": {}
}
]
}
0
On First Read
.option(“cloudFiles.inferColumnTypes”,”True”)](https://image.slidesharecdn.com/1060simonwhiteley-210614173625/85/Accelerating-Data-Ingestion-with-Databricks-Autoloader-31-320.jpg)
![Schema Metastore – Schema Hints
_schemas
{“ID”:1,
“ProductName”:“Belt”}
{
"type": "struct",
"fields": [
{
"name": "ID",
"type": “long",
"nullable": true,
"metadata": {}
},
{
"name": "ProductName",
"type": “string",
"nullable": true,
"metadata": {}
}
]
}
0
On First Read
.option(“cloudFiles.schemaHints”,”ID long”)](https://image.slidesharecdn.com/1060simonwhiteley-210614173625/85/Accelerating-Data-Ingestion-with-Databricks-Autoloader-32-320.jpg)












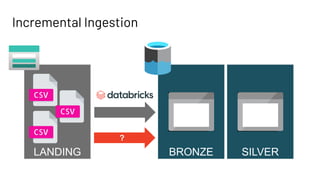
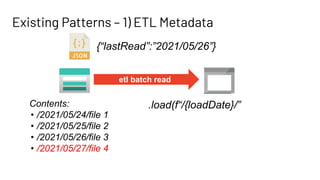
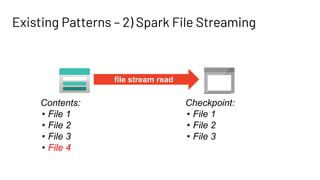
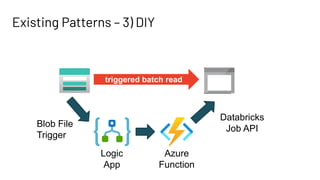
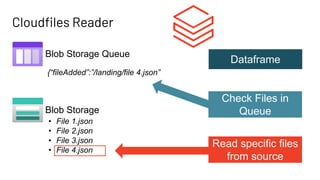
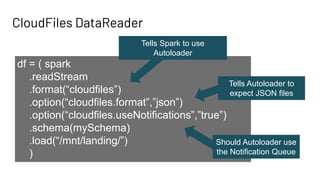
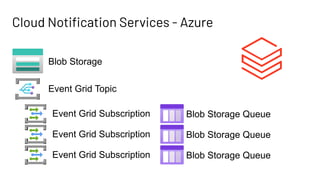
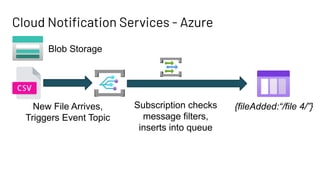
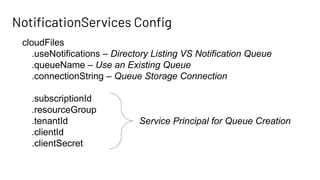
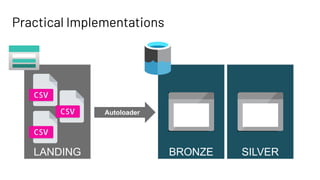
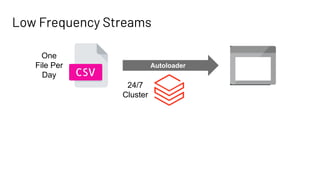
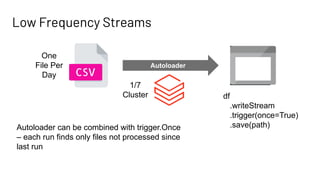
The document discusses Databricks Autoloader, an optimized cloud file source for Apache Spark that enables efficient incremental data ingestion from cloud storage. It highlights the components, implementation methods, and schema evolution features, emphasizing the advantages of using Autoloader over existing ingestion patterns. Additionally, it provides insights into practical implementations, lessons learned, and best practices for managing event grids and streaming operations.
























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)






























































