Downloaded 12 times






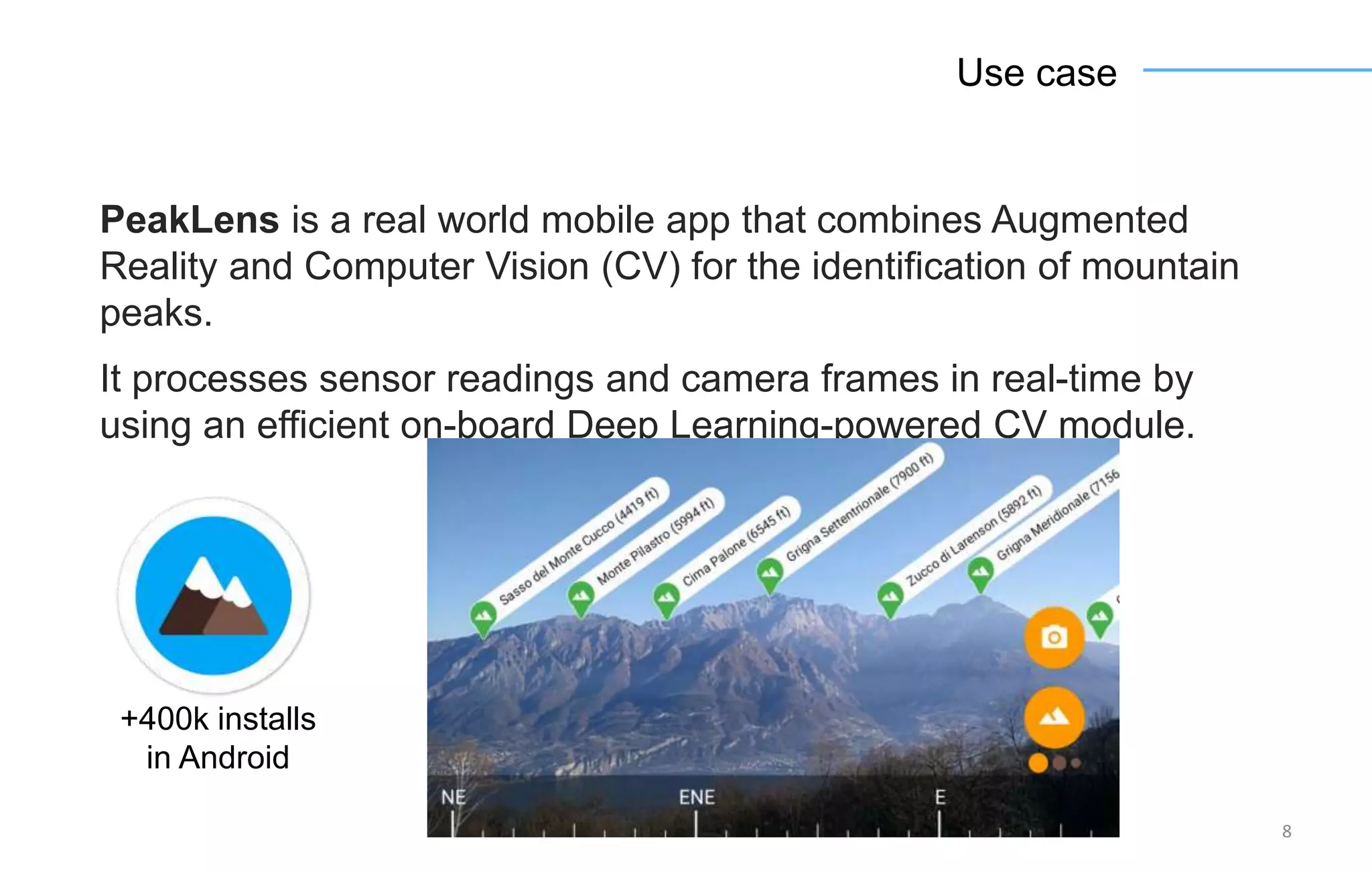


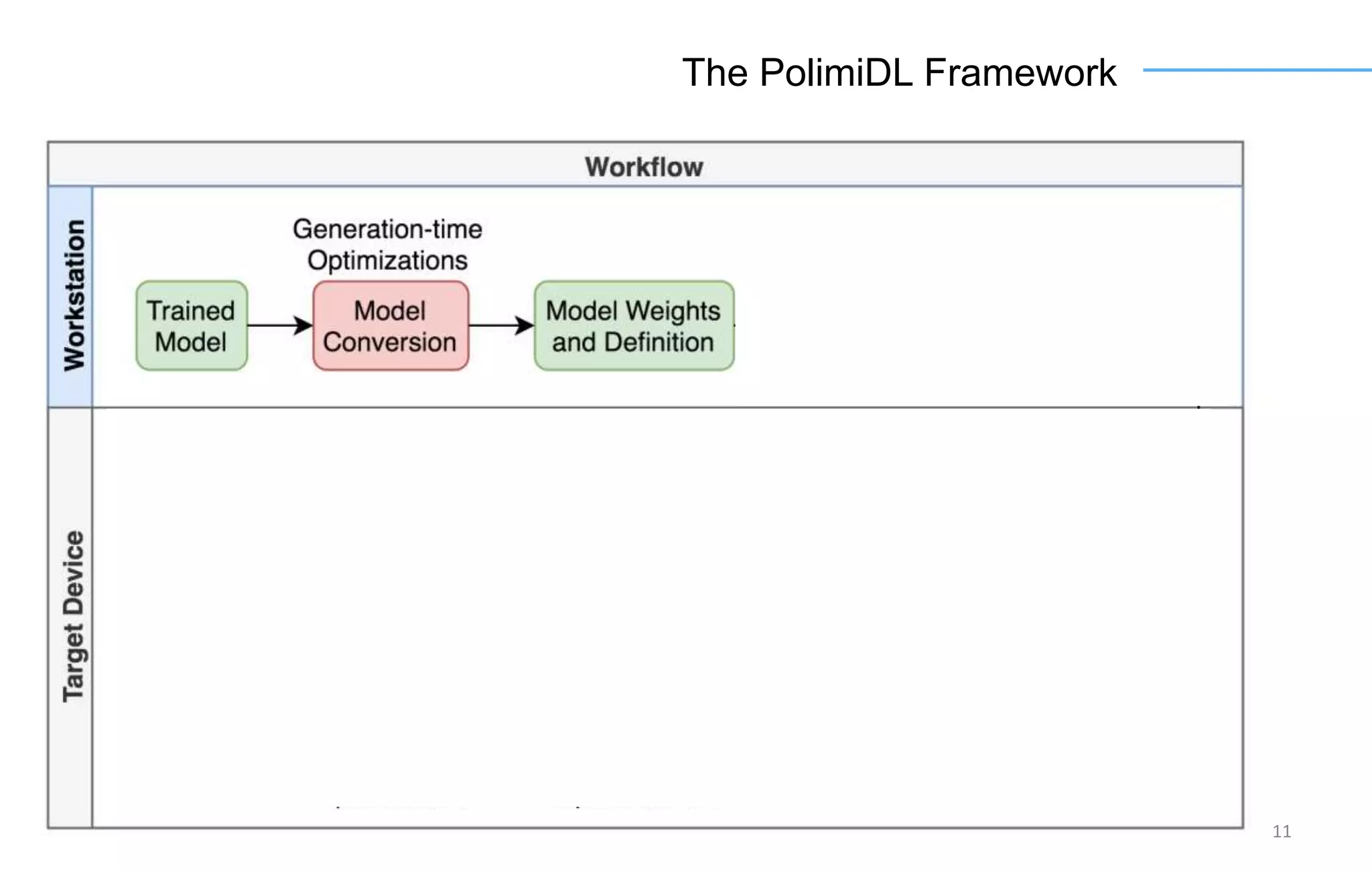


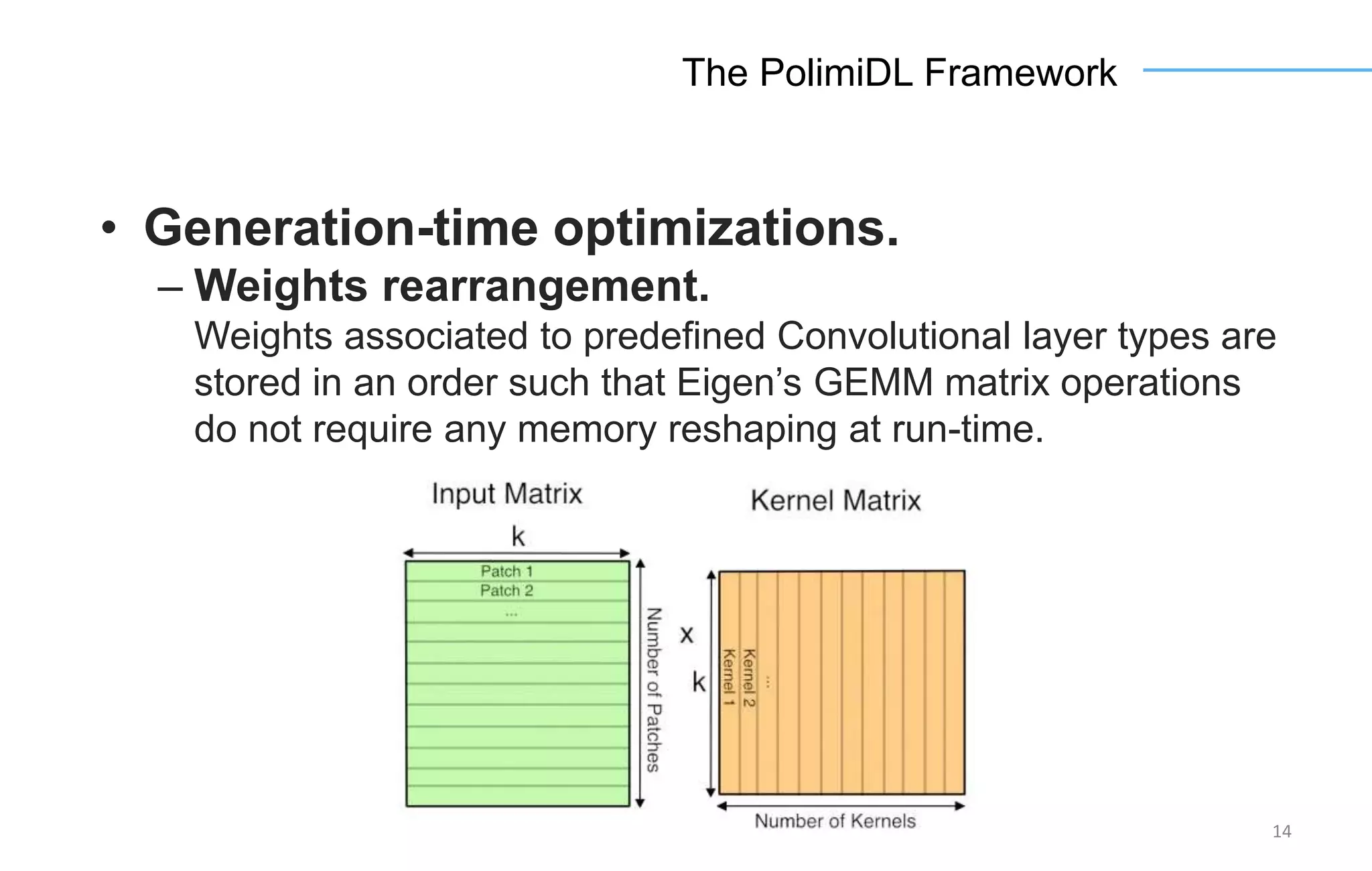
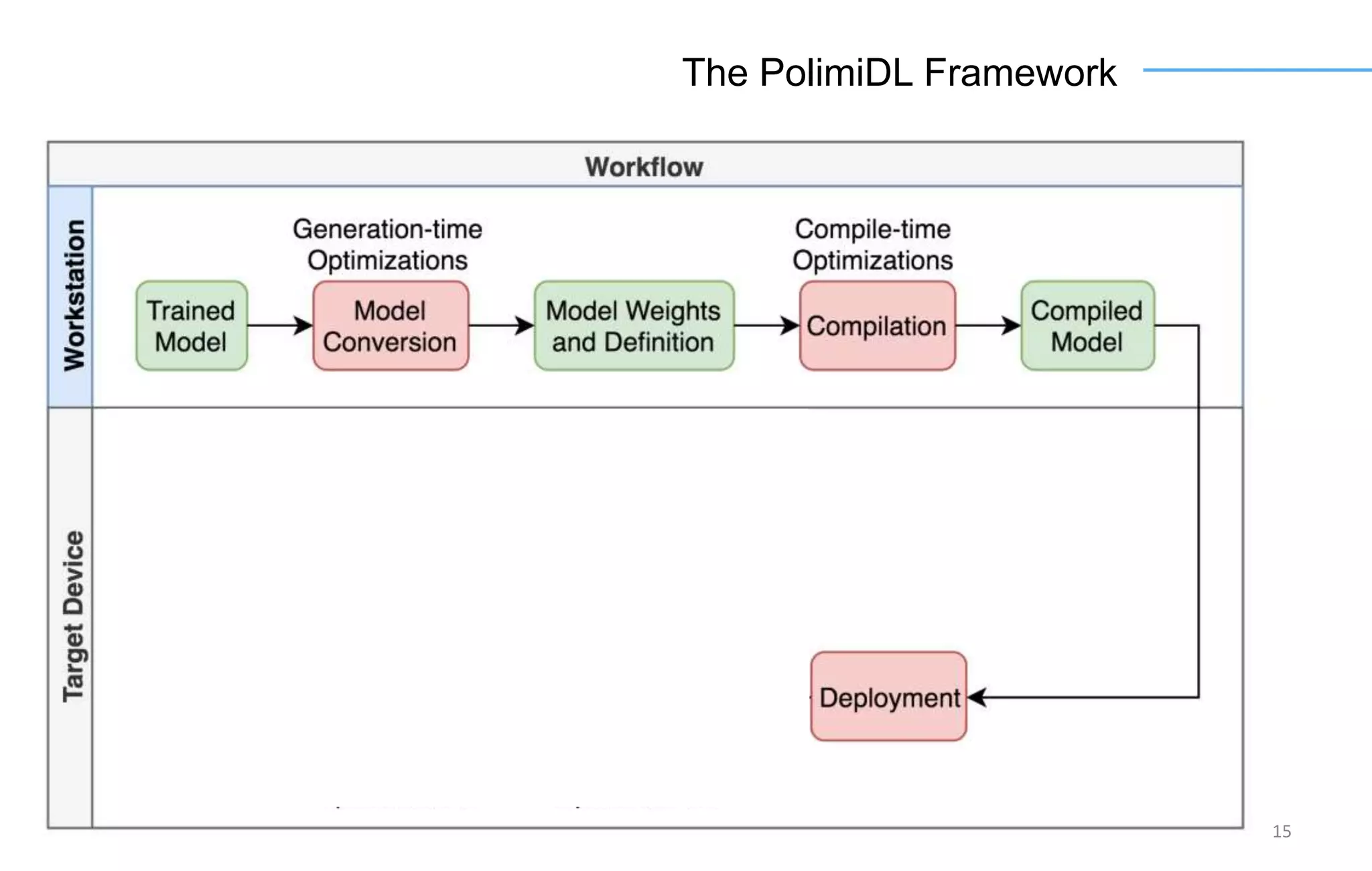
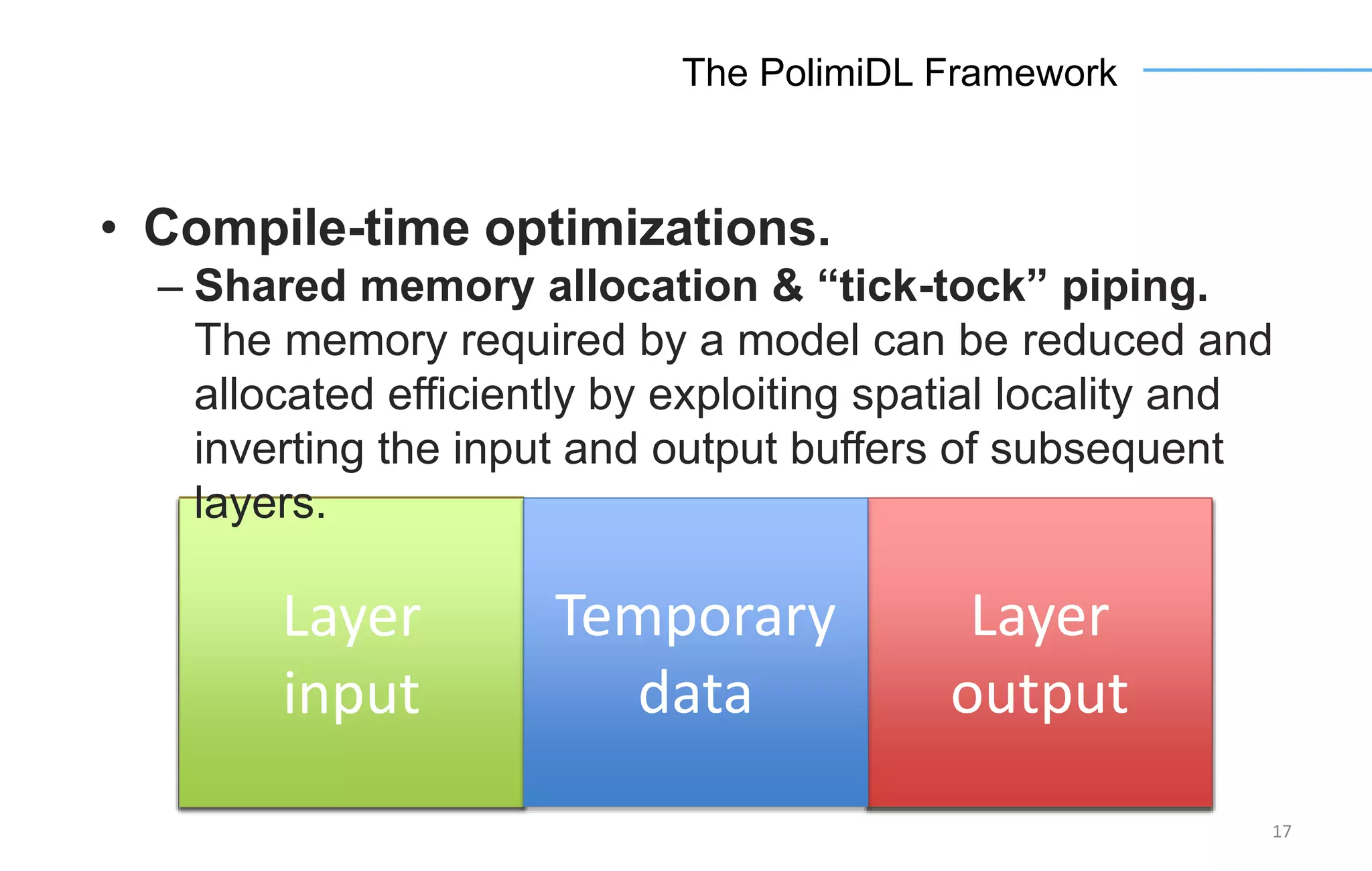
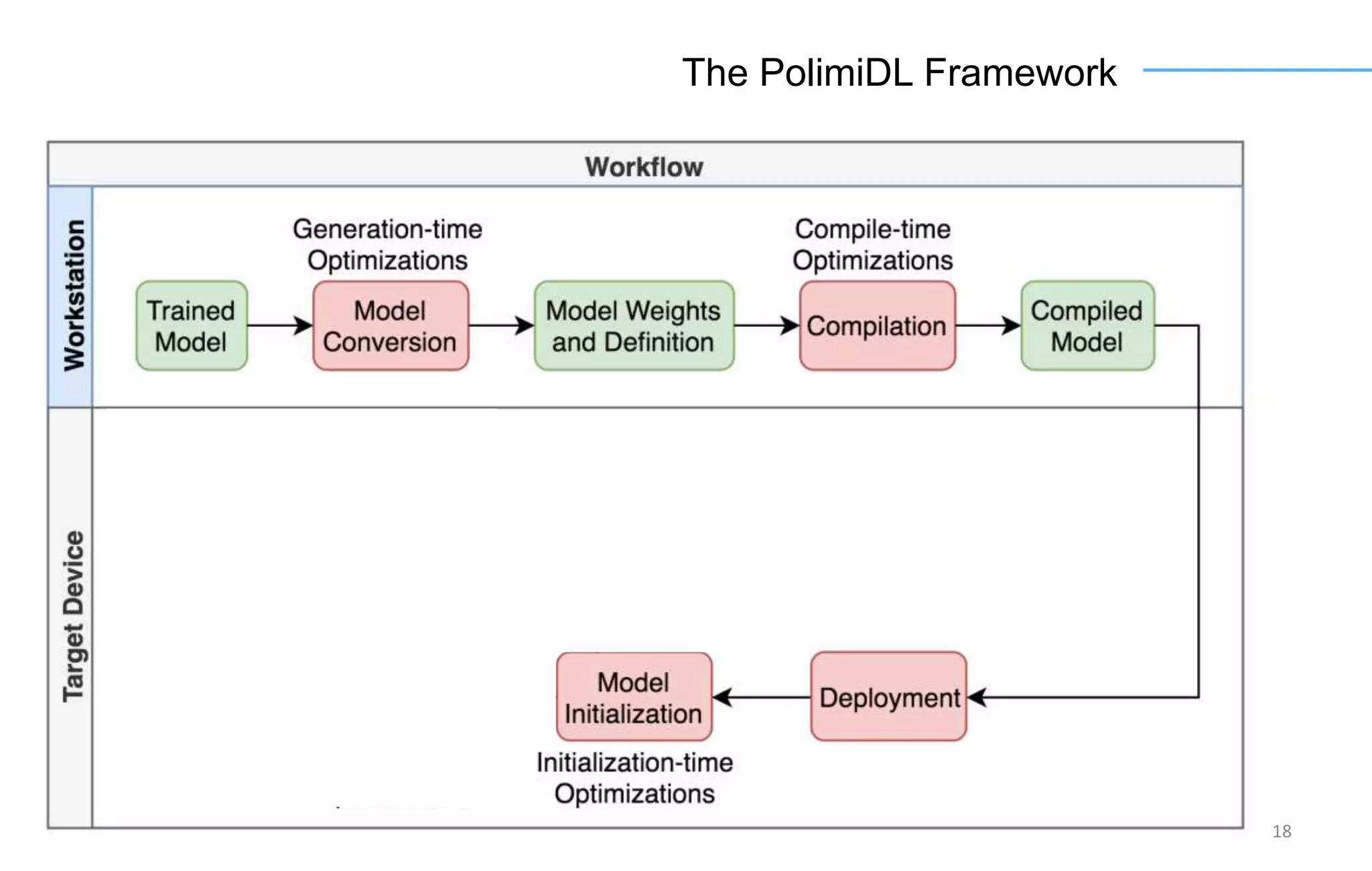


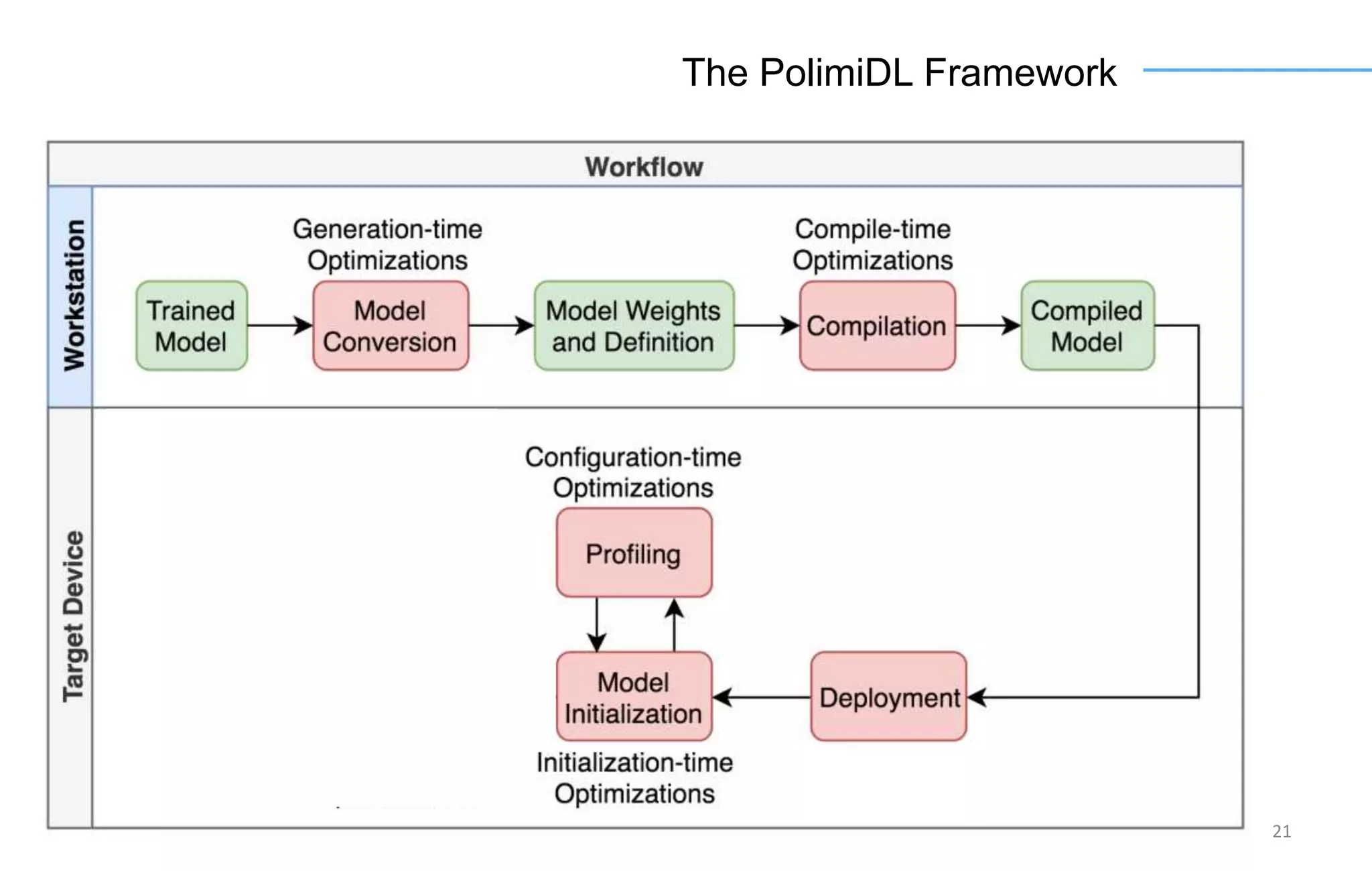

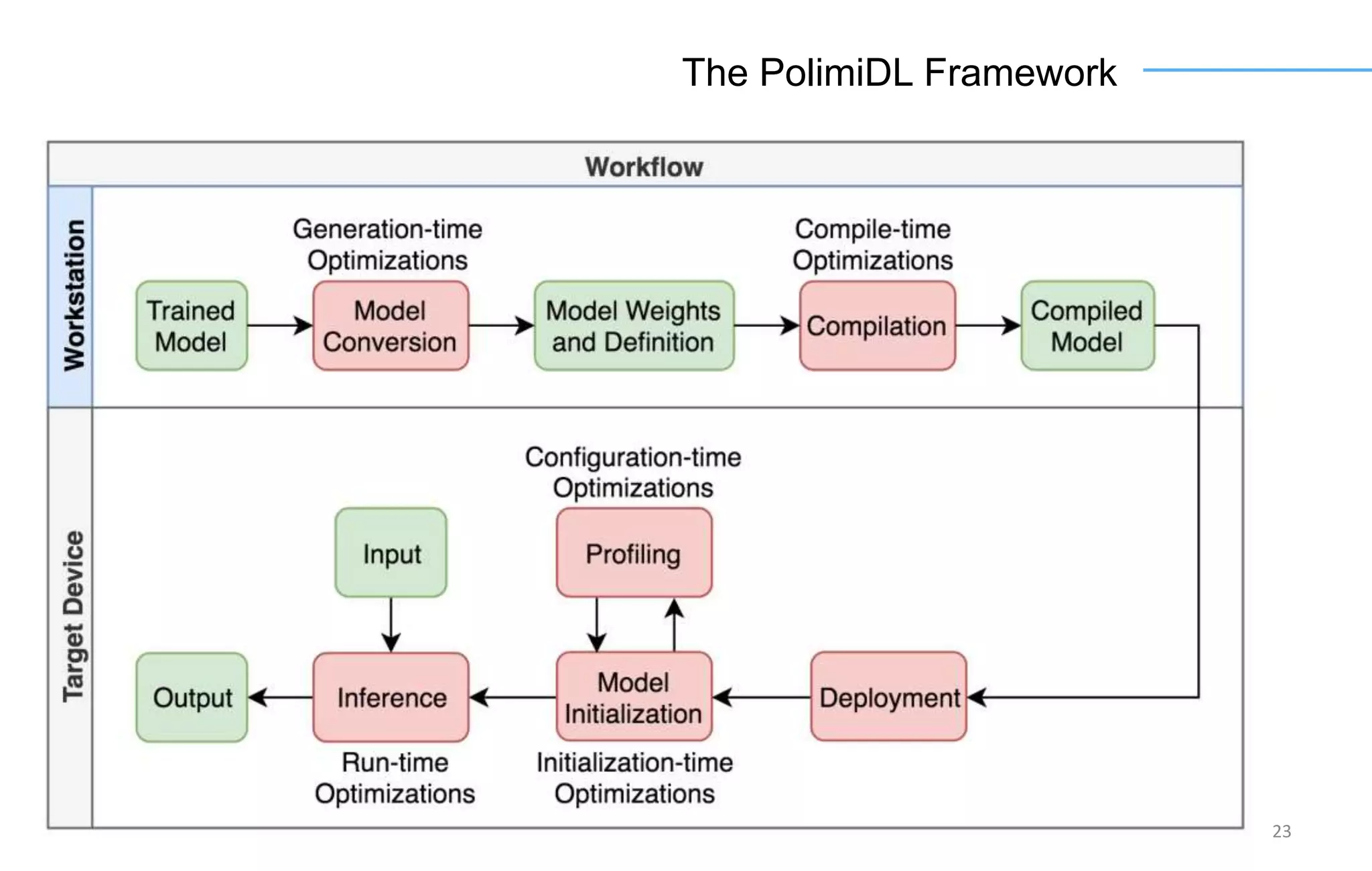

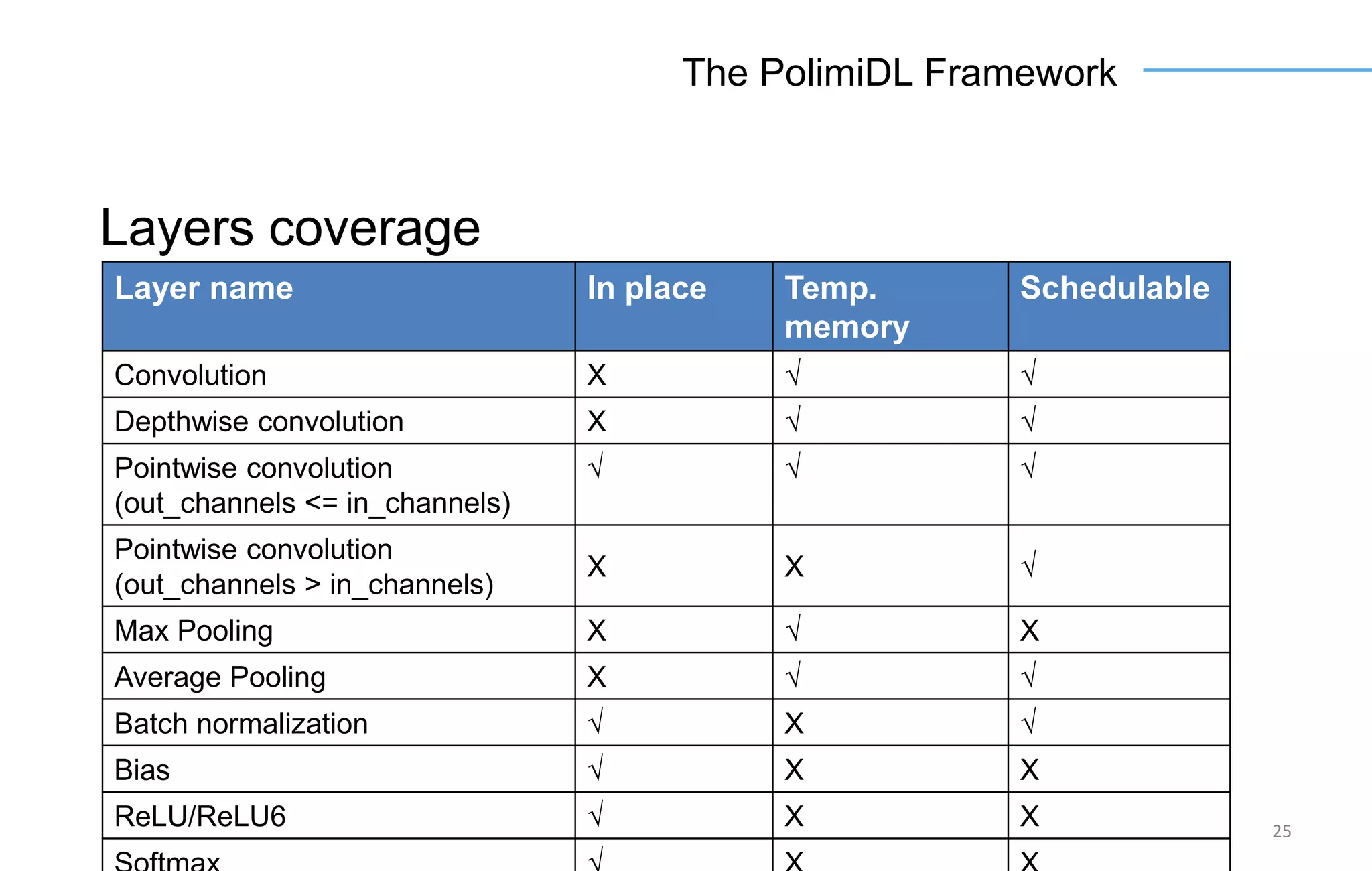

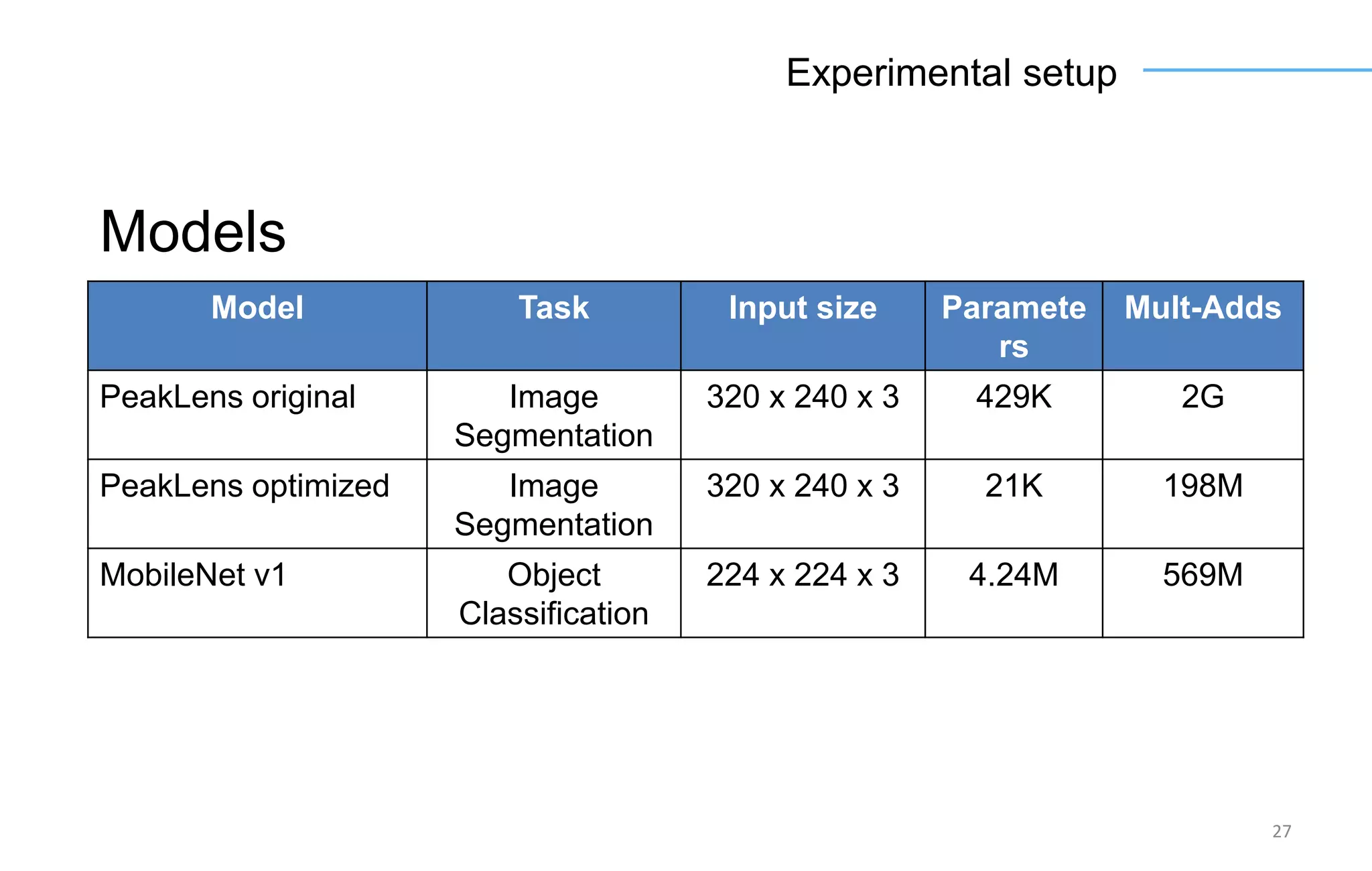
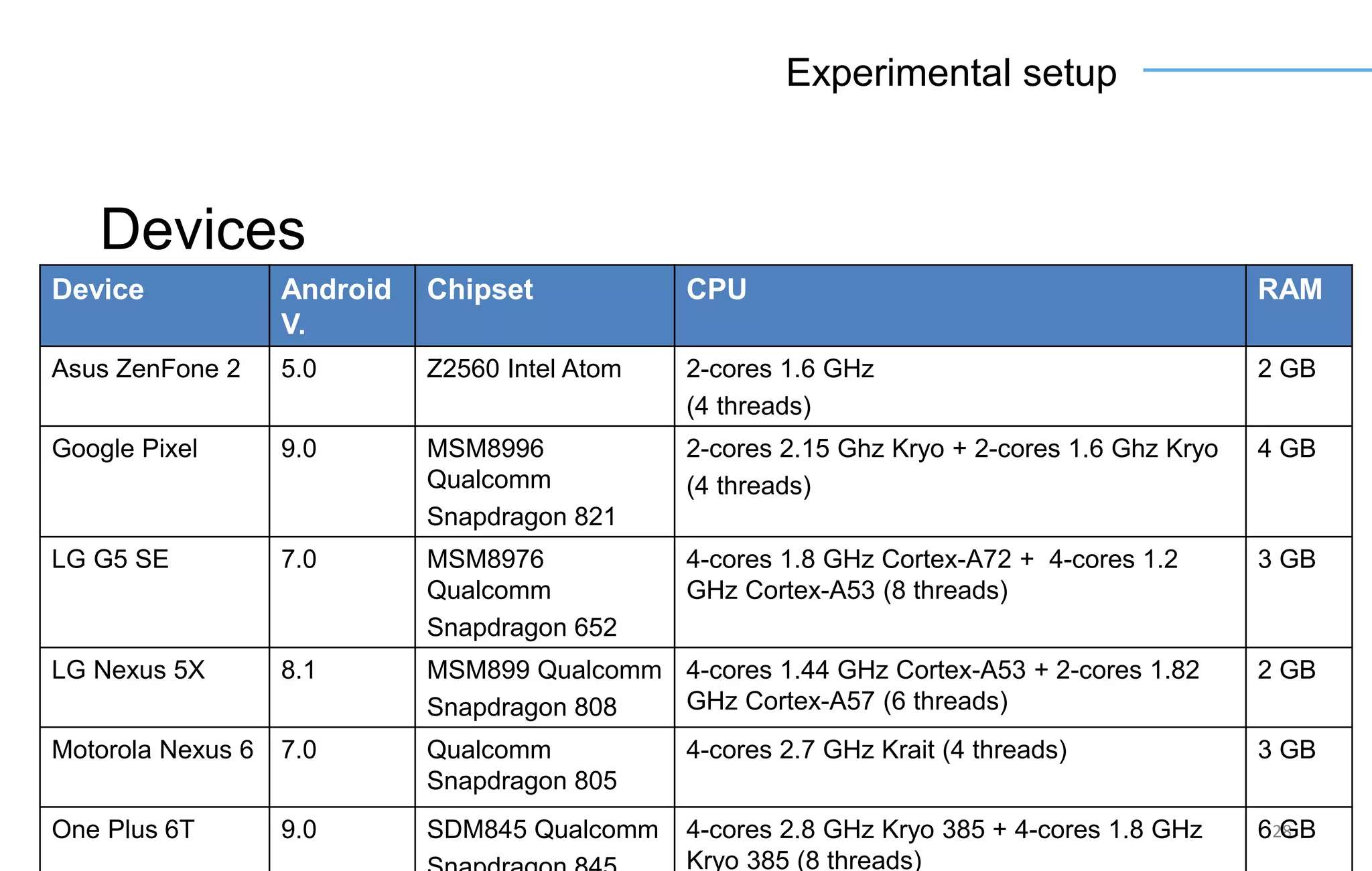

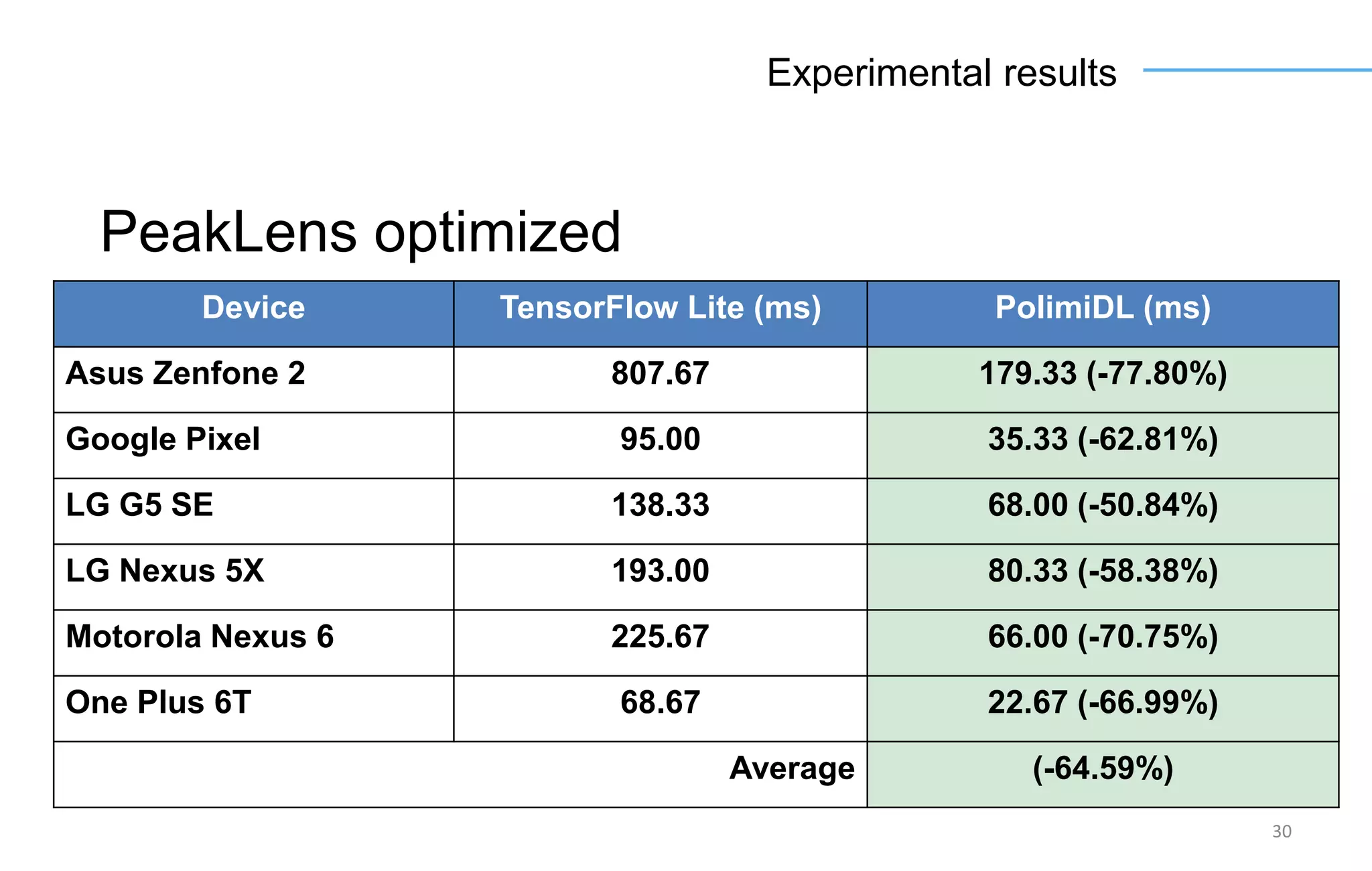
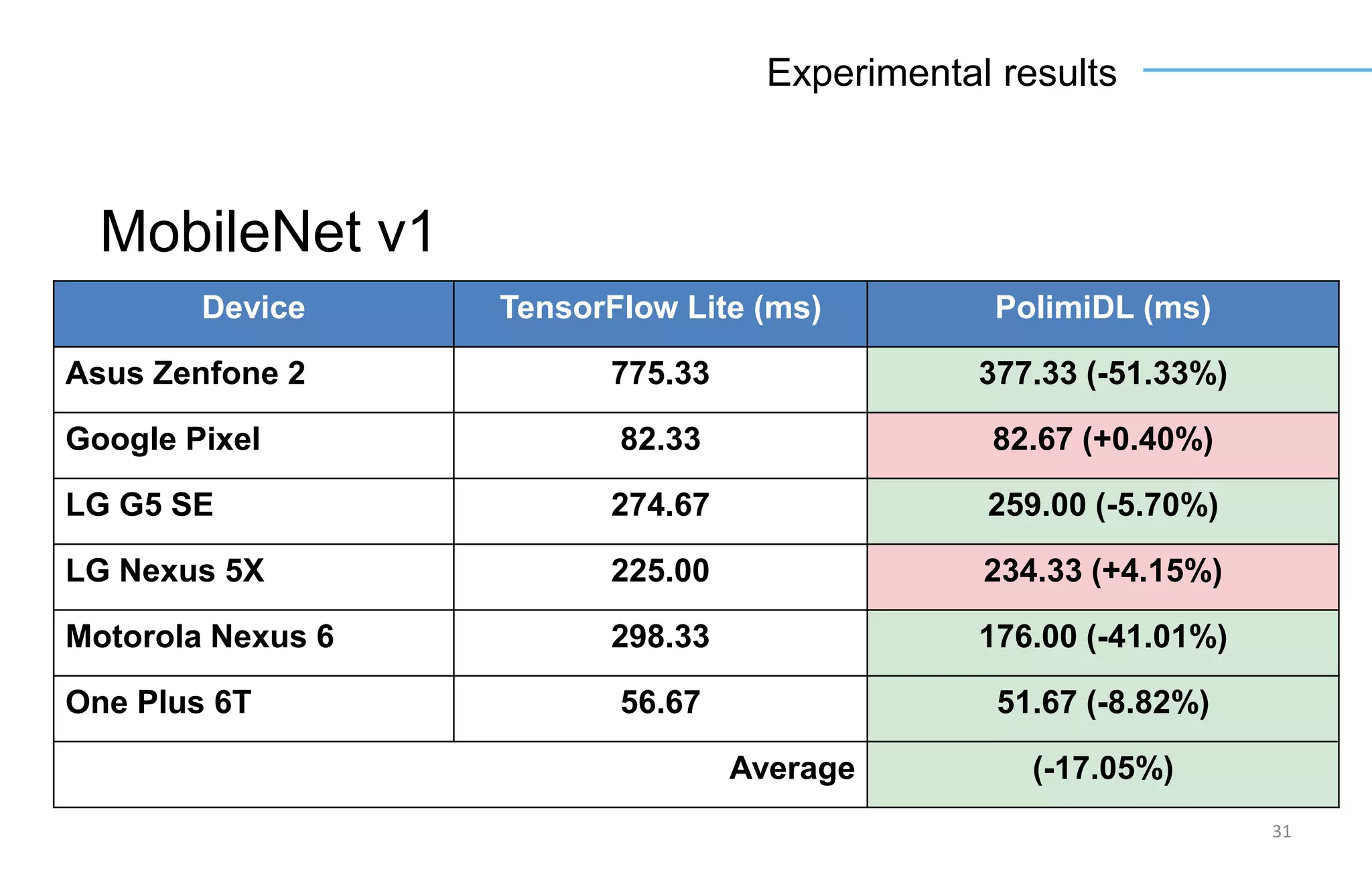



The document discusses the challenges and solutions for accelerating deep learning inference on mobile systems through a framework called Polimidl. It focuses on various optimizations at different stages of model deployment to enable efficient execution while maintaining accuracy, targeting real-time applications in smart devices. The framework shows competitive results against TensorFlow Lite across various devices, with plans for future enhancements in layer support and evaluation metrics.