Download to read offline







![Memory Optimization: DRAM Accesses
9
© 2023 DeepX AI
49%
0%
20%
40%
60%
80%
100%
120%
MobileNetv1 MobileNetv2 MobileNetv3-Large ResNet50 EfficientNet-B0 YOLOv4 (telechips) YOLOv5s Average
Normalized DRAM Accesses Over Base [M1-4K, 2.25 MB]
Base #DRAM](https://image.slidesharecdn.com/e2w06kimdeepx2023-230608131045-632a7b0d/85/State-of-the-art-Model-Quantization-and-Optimization-for-Efficient-Edge-AI-a-Presentation-from-DEEPX-9-320.jpg)
![Memory Optimization: Performance
10
© 2023 DeepX AI
137%
0%
20%
40%
60%
80%
100%
120%
140%
160%
MobileNetv1 MobileNetv2 MobileNetv3-Large ResNet50 EfficientNet-B0 YOLOv4 (telechips) YOLOv5s Average
Normalized Performance (FPS) Over Base [M1-4K, 2.25 MB]
Base MemOpt](https://image.slidesharecdn.com/e2w06kimdeepx2023-230608131045-632a7b0d/85/State-of-the-art-Model-Quantization-and-Optimization-for-Efficient-Edge-AI-a-Presentation-from-DEEPX-10-320.jpg)







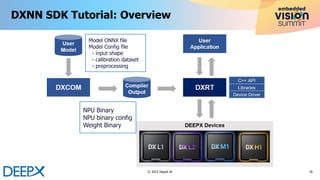

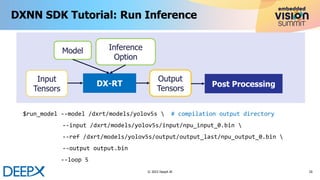










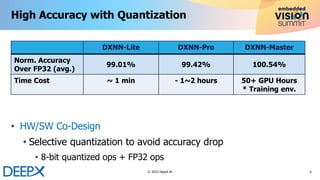
The document discusses advanced techniques in model quantization and optimization for efficient edge AI using DeepX's NPU technology. Key points include the importance of maintaining high accuracy with selective quantization, hardware/software co-design, and minimizing hardware costs, particularly SRAM utilization. Additionally, it provides details on the deployment of AI models and the benefits of fused operations to enhance performance and reduce memory access.



































































